リフトチャート(LiftChart)を使ったモデルの評価
こんにちはシバタアキラです。
機械学習モデルの評価の方法に、DataRobotでよく使われているリフトチャート(LiftChart)というものがあります。実は私もデータロボットで働くまで知らなかったモデル評価方法でした。実は知らないのは私だけではなく、ほとんどのユーザーの方はリフトチャートを知らない上、インターネット上を調べてもほとんど情報がありません。さらにはリフトチャートには複数の定義があり、DataRobotで使われているバージョンを定義する文献はほとんどありません(累積反応曲線と言われる別のものをリフトチャートと呼ぶことがある)。一方でリフトチャートは、そのシンプルさにかかわらず非常に優れた特徴を持っているモデル評価方法です。本稿ではそんなリフトチャートの計算方法と利用方法をご紹介します。
リフトチャートとは何のためのもの?
リフトチャートは機械学習モデルに限らず、予測モデルの精度をはかるために使われます。モデルの出力する予測値がどれくらいの判別能力や予知能力を有しているのか、また複数のモデルを比較した時に、どちらのモデルの精度が良いのかを素早く視覚的に捉えることができます。
まずリフトチャートを見てみましょう
早速ですが、リフトチャートを見てみたいと思います。ここでの前提は、とある目的変数を多数の説明変数に基づく予測モデルを使って予測した結果として、テストデータにおける予測値と実測値の比較を行っているとします。さっそく借金の貸し倒れを予測するための機械学習モデルを使った予測結果から得られたリフトチャートを見てみましょう。
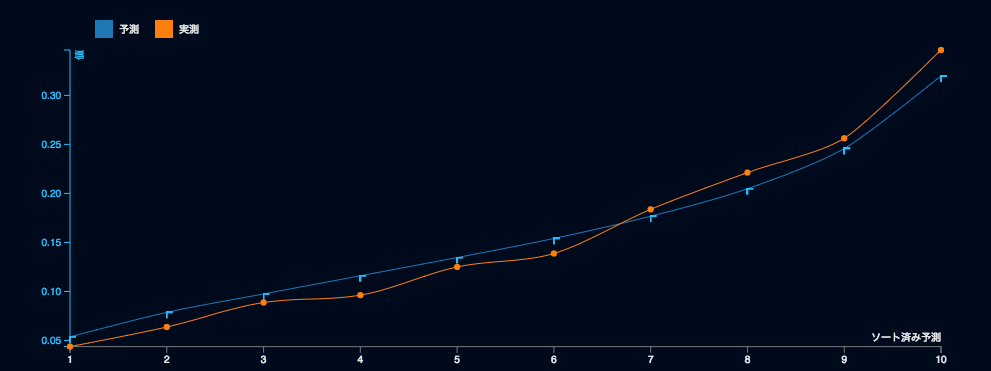
このシンプルさが特長です。リフトチャートを見る上ではあまり多くの情報はありません。主に二つの点を観察します:
- 実測の線の角度 – 一般的には、急なほどよい
- 予測と実測の近しさ – 一般的には、近いほどよい
DataRobotにおいては、Y軸が相対軸で出力されるため、少し注意が必要です。つまり、ここでの予測値は0-1の値を取りうるのですが、このモデルの精度はそこまで高くないため、表示範囲が0.05-0.35になっています。
リフトチャートの作り方
リフトチャートを理解するために、リフトチャートの作り方を見ていきましょう。いま、仮にテストデータ(「検定データ」とも呼ばれる)の中に、20行の実測値があるとします。下の例では、借金の貸し倒れがあったかどうかを予測した結果を表しているとします。それぞれの実測値に対して、計算された予測値が並んでいるとします。
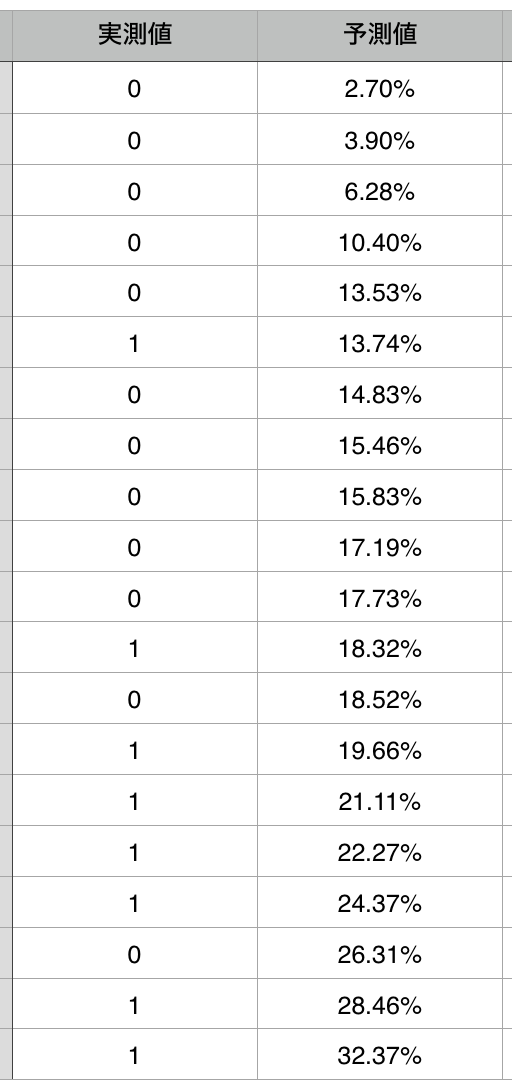
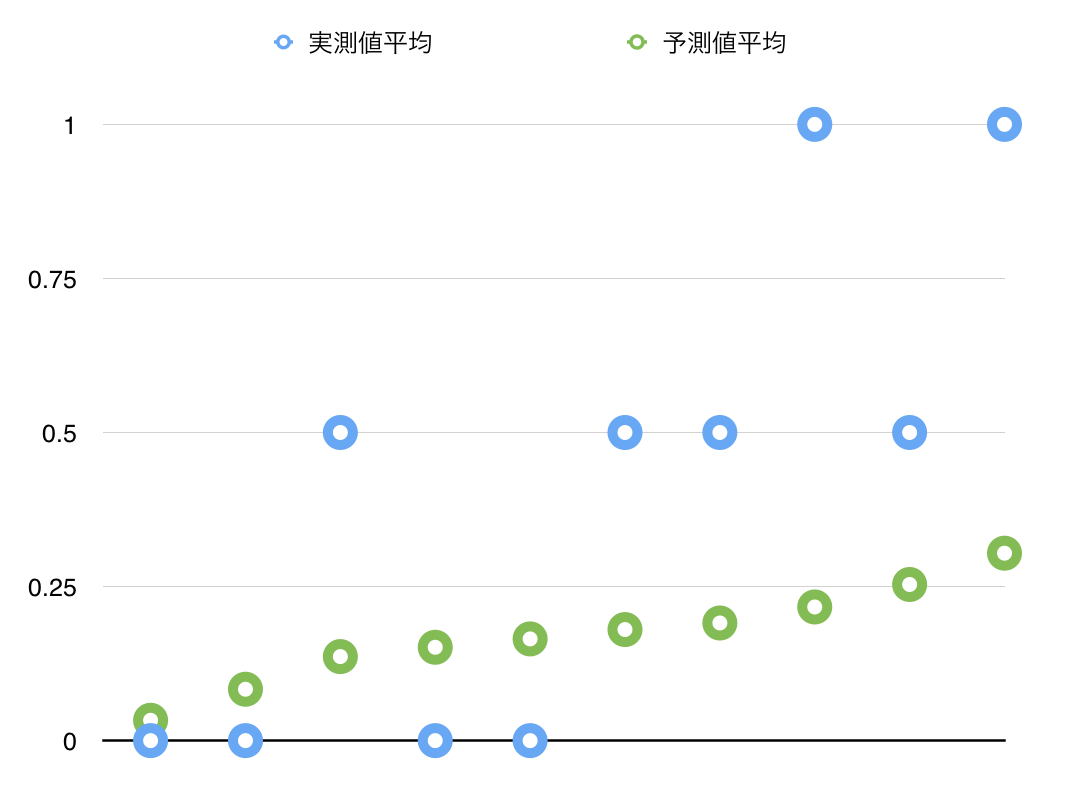
これを、予測値で並べ替えます。上から下に大きい値になるよう並べ替えました。こうした時に、「予測値が高い場合は実測値も大きな値(今回はTrue値)になるだろう」と想定できます。これが重要なポイントです。予測値の精度がたかければ、当然下の方に実測の1(True)が来るはずですが、もし予測値の精度が悪ければ、実測値の1はランダムに現れます。
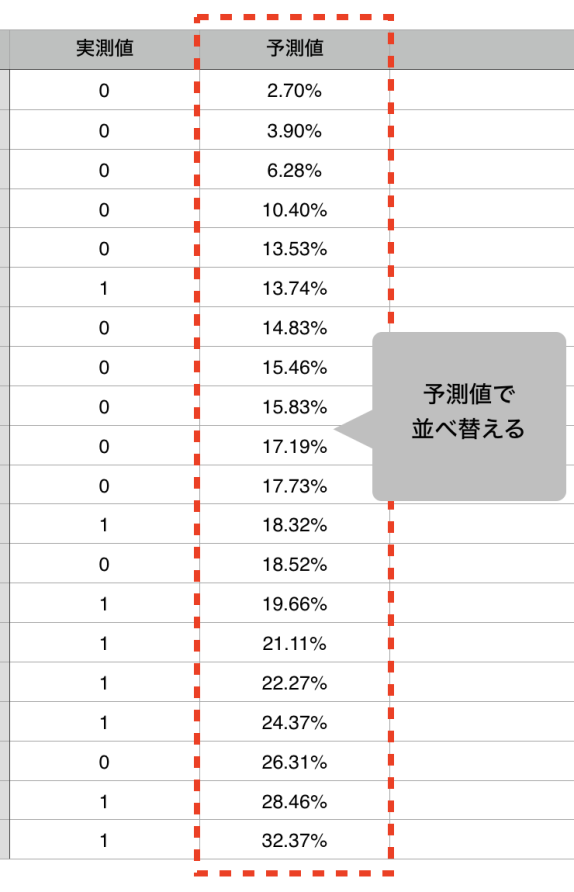
そして、上から等間隔2行ずつを一つの「ビン」にアサインします。そのそれぞれのビンの中で、実測値と予測値のそれぞれの平均を計算します。
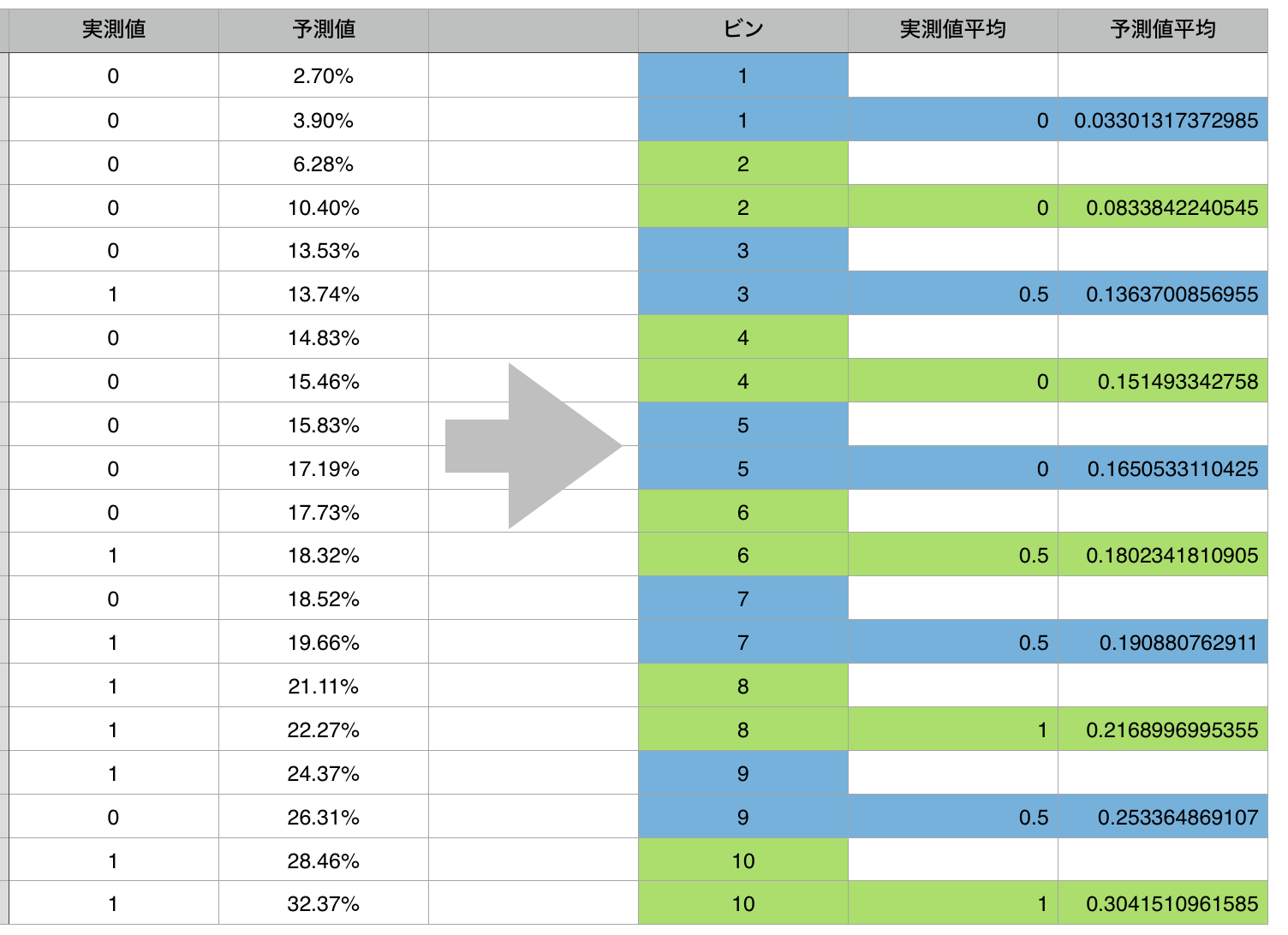
これをグラフにしたものがリフトチャートです。今回は20行のデータから、10のビンのリフトチャートを作ったため、実測値の平均はあまり滑らかにはならないですが、ざっくりと、実測値側も右上に向かっているように見えます。
リフトチャートの優れている点
複数のモデルを比較することが簡単
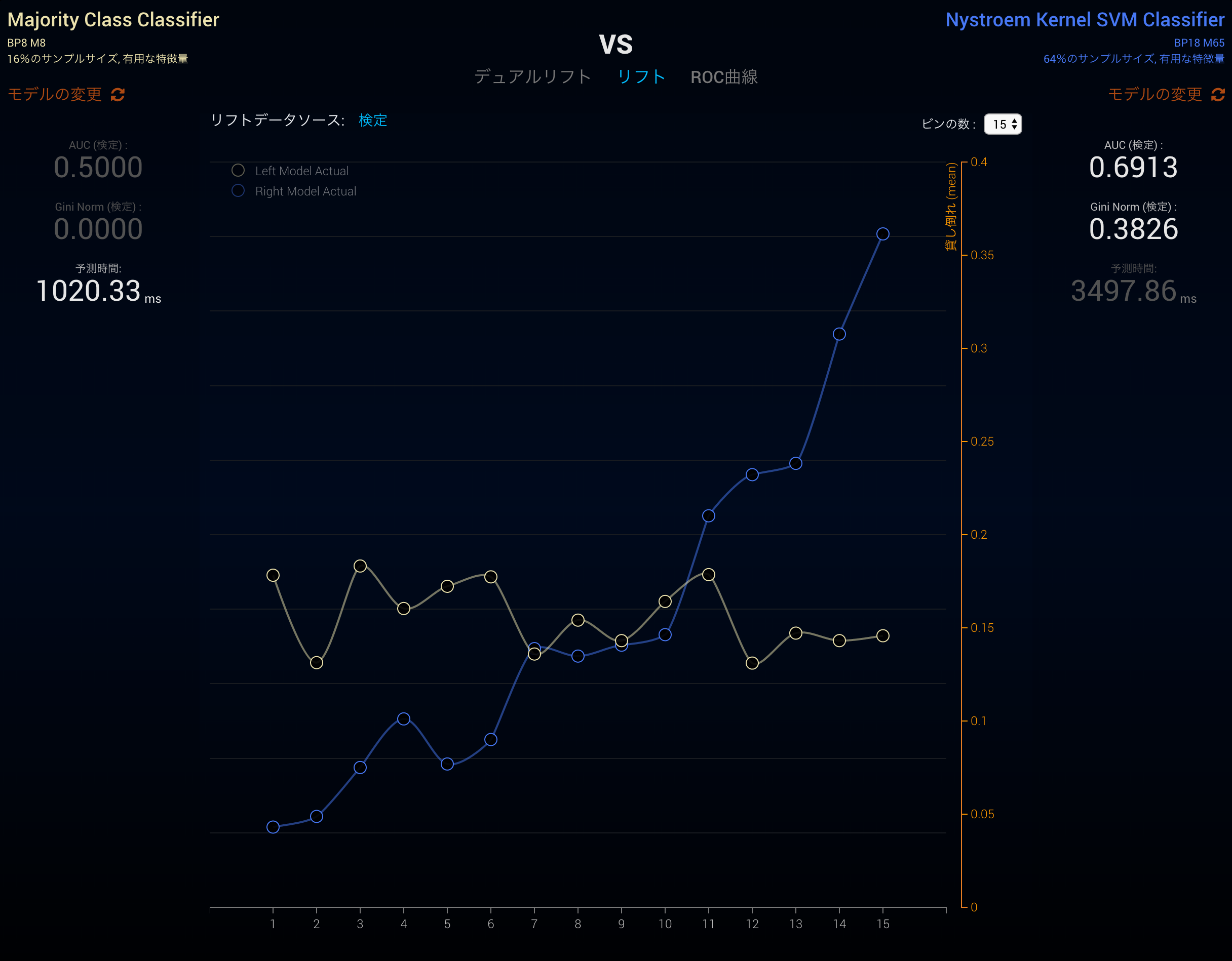
このようにして、リフトチャートは、予測値が実際に高い予測能力を持っているのかを線の角度で視覚化することができます。つまり、精度が良いモデルの場合は急な角度、精度が悪い場合にはフラットな線になります。DataRobotで精度の良いモデル(青)と、精度の悪いモデル(黄)を比べるとこのようになります。精度のないモデルのフラットな線に対して、精度のあるモデルは上に登る(Liftする)ことが、「リフトチャート」という名前の語源になっています。
視覚的にモデルの精度やバイアスを捉えることができる
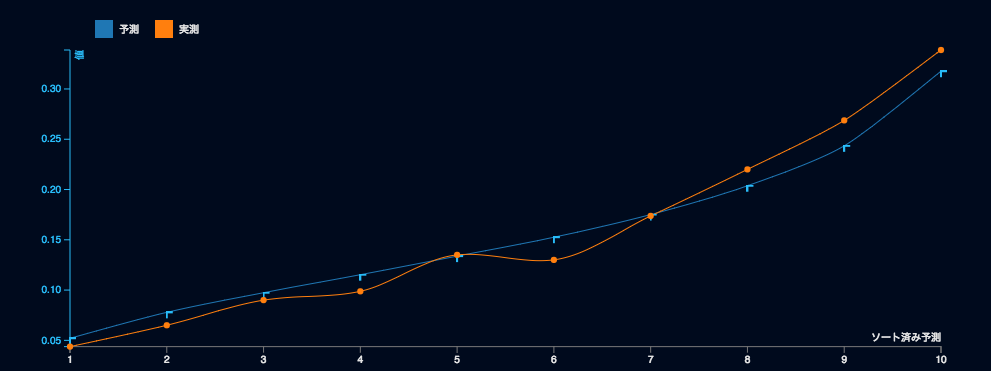
また、実測と予測を比較することにより、予測値が特にどの領域で精度が良い・悪いのか、また全領域に共通のバイアス(常に低い値で予測する傾向がある)など、を確認できます。具体的には、線の距離が近くて、何度かは交差しているのが健全なモデルということができます。
分類でも連続値の回帰の問題でも、どちらでも使える
さらにリフトチャートは、ROC曲線と違い、連続値の回帰(例えば売り上げの予測とか、乗客数の予測)の場合にも、上記の分類のケースと同じように使うことができます。その場合には、Y軸は確立ではなく、実際の予測対象となっている数値となります。例えば、今度は60のビンで計算したお菓子の売り上げ予測の結果を見てみましょう。
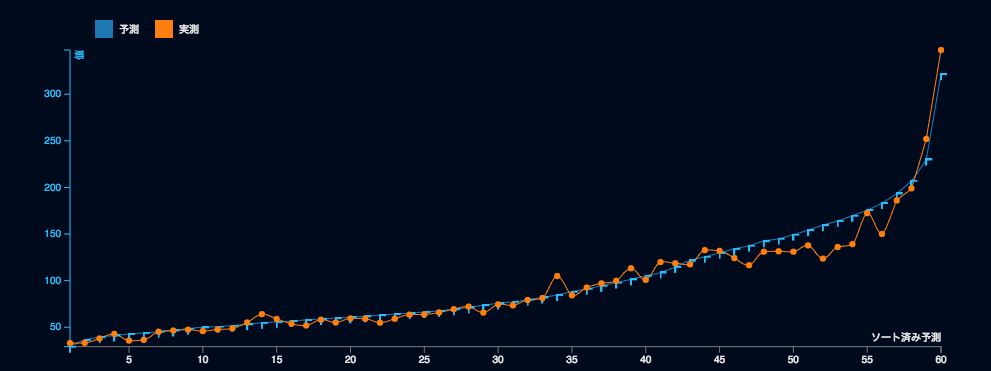
ここから、特に売り上げが大きい値の場合に、予測値が下振れする傾向にあることが見て取ることができます。
最後に、リフトチャートの利点は、ここでも見たように、計算が単純で直感的であるという点もあげておきます。
こんな時に使うと良い
基本の使い方:生成されたモデルの精度確認
上記でも触れてきたように、まずは生成された機械学習モデルの精度を視覚的に把握するために便利なリフトチャートですが、具体的に下記のような応用ケースにはさらに重宝します。
既存のモデルの精度がよく理解されていない場合
機械学習モデルの導入の前に、すでにルールベースのモデルが存在しているような場合があります。しかし、属人的なドメイン知識から「こうすれば分類できるだろう」という仮説だけでスコアが決定され、実際の運用上その精度がほとんど検証されていないようなことも見受けられます。このような場合には、新しいモデルの精度の検証に先立って、既存モデルのリフトチャートを計算しておくことが効果的です。これにより、既存モデルのスコアの精度(場合によっては右肩下がりになったり、変なピークがあったりということがある)を理解できるだけでなく、新しいモデルができた時の比較の対象をセットすることができます。
モデルの精度をわかりやすくかつ定量的に表現したいとき
例えば貸し倒れを予測する与信モデルの場合、モデルの精度を表す上で「この予測値を使って選ばれたもっとも貸し倒れリスクの高い上位10%の人たちは、35%の確立で貸し倒れる。これは平均の貸し倒れ率の15%に比べて非常に高く、また既存モデルのトップ10%のグループよりも5%もリスクが高い」そして、その分の精度向上分を利益率などのROI指標に読み替えることができます。
応用編:デュアルリフト
リフトチャートにおいては、複数モデルの比較が利用における重要な側面です。この点をさらに突き進め、二つのリフトチャートの際に着目した分析方法にデュアルリフト、という手法があります。この手法もDataRobot以外の文脈ではあまり知られていないものの、時にパワフルな手法ですので、別の機会にお話ししたいと思います(追記:ここに書きました)。

DataRobot Japan チーフ・データサイエンティスト。ロンドン大学高エネルギー物理学博士課程修了。ニューヨーク大学でのポスドク研究員時代に加速器データの統計モデル構築を行い「神の素粒子」ヒッグスボゾン発見に貢献。その後ボストン・コンサルティング・グループでコンサルタントとして、主に TMT/製薬業界でのデータ分析業務に従事。AI 型情報キュレーションを提供する白ヤギコーポレーションの創業者兼 CEO を経て2015年に DataRobot Japan の立ち上げに一人目のメンバーとして加わり現職。個人ブログにhttps://ashibata.com/、共著に「データ活用実践教室」(日経BP社)など
直近の注目記事
AI活用を成功に導く方法をサービス商品化した米AIベンチャーの狙い(ZDNet Japan)
シバタアキラ氏が伝授#01/データサイエンスって何?(日経ビジネスONLINE)
この人にはこれが売れる/実践!データサイエンス#09(日経ビジネスONLINE)
データサイエンティストになるには?社内で育てる方法は?わかりやすく解説(ビジネス+IT)
-
分類プロジェクトの評価でAUCよりも便利なFVE Binominal|DataRobot機械学習モデル評価指標解説
2024/04/05· 推定読書時間 4 分 -
RAG(Retrieval-Augumented Generation)構築と応用|生成AI×DataRobot活用術
2024/04/03· 推定読書時間 4 分 -
バリュー・ドリブンAI:予測AIから学んだ教訓を生成AIに応用する
2024/03/19· 推定読書時間 2 分
最近のブログ記事