

A Business Analyst’s Journey into Machine Learning through Kaggle
‘Predictions and insights without a Data Scientist’
 By Ina Ko
By Ina Ko
Senior Product Manager
DataRobot
You do not need to be a data scientist to compete in a Kaggle competition. I know this because I did it. My name is Ina Ko, and I am not a Data Scientist. Instead, I stand on the shoulders of giants — that is, the data scientists and engineers who built the DataRobot machine learning platform.
As Product Manager and Business Analyst at DataRobot, I operate at the nexus of three areas: working with users (my personal passion), working with builders (typically engineers), and working with business interests (C-suite executives). I make arguments based on qualitative and quantitative data using business intelligence tools like Tableau, Spotfire, and Excel.
My challenge — what will help the product team at DataRobot understand and relate to a typical DataRobot end user’s experience? Becoming an end user. So, enticed by a little healthy competition from DataRobot’s VP of Product, Phil, we entered a Kaggle competition to empathize with our end users.
The Kaggle Journey
We joined the Kaggle competition Predicting Red Hat Business Value. Phil, after his first few submissions using DataRobot, lands himself in the top 2% (currently out of around 1000 competitors). The quiet, fiery competitor in me set my goal as finishing in the top 1.99%. Nothing personal Phil.
I asked Phil what he did to land himself in the top 2%; not because I question his technical skills, but because he too, is standing on the shoulders of giants. Below is the end-to-end workflow that I followed:
-
- Step 1: Prep the dataset.
Performed a left join, using mySQL, on the two training datasets provided by Kaggle. The datasets had a one-to-many relationship.
(Time spent: 5 minutes)
- Step 1: Prep the dataset.
- Step 2: Upload the dataset into DataRobot, select the feature that I want to predict, and, like the image below suggests, just click the Start button to kick-off an Autopilot run. (Time spent: < 1 minute)
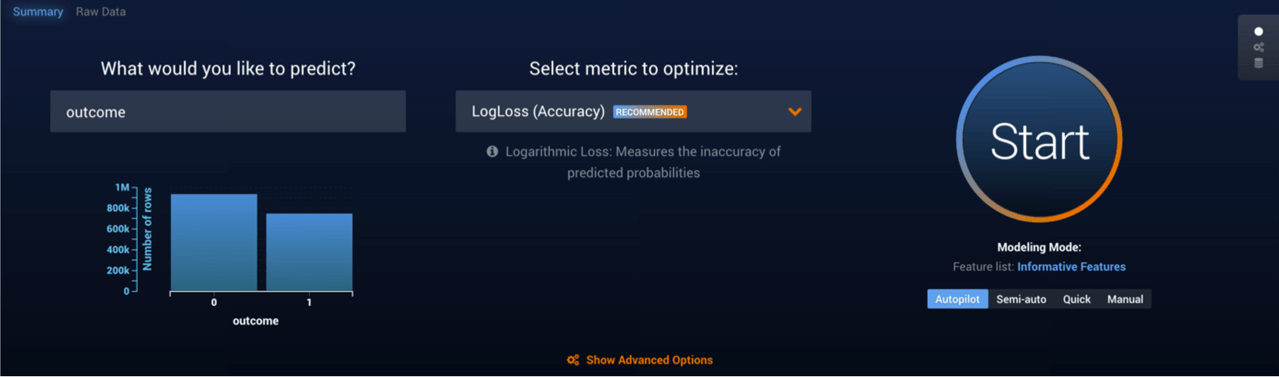
- Background: Autopilot mode, using DataRobot’s powerful parallel processing capability, runs thousands of different preprocessing steps on various algorithms. DataRobot then starts running about 40 algorithms, selected based on dataset characteristics and statistical problem type, with the goal of outputting the best predictive models for the specified feature. It then cuts down the list using a “survival of the fittest” methodology, running the top 8 performing models at a larger sample size. DataRobot ranks all the models, from highest to lowest performance, on its ‘Leaderboard’ (image below).
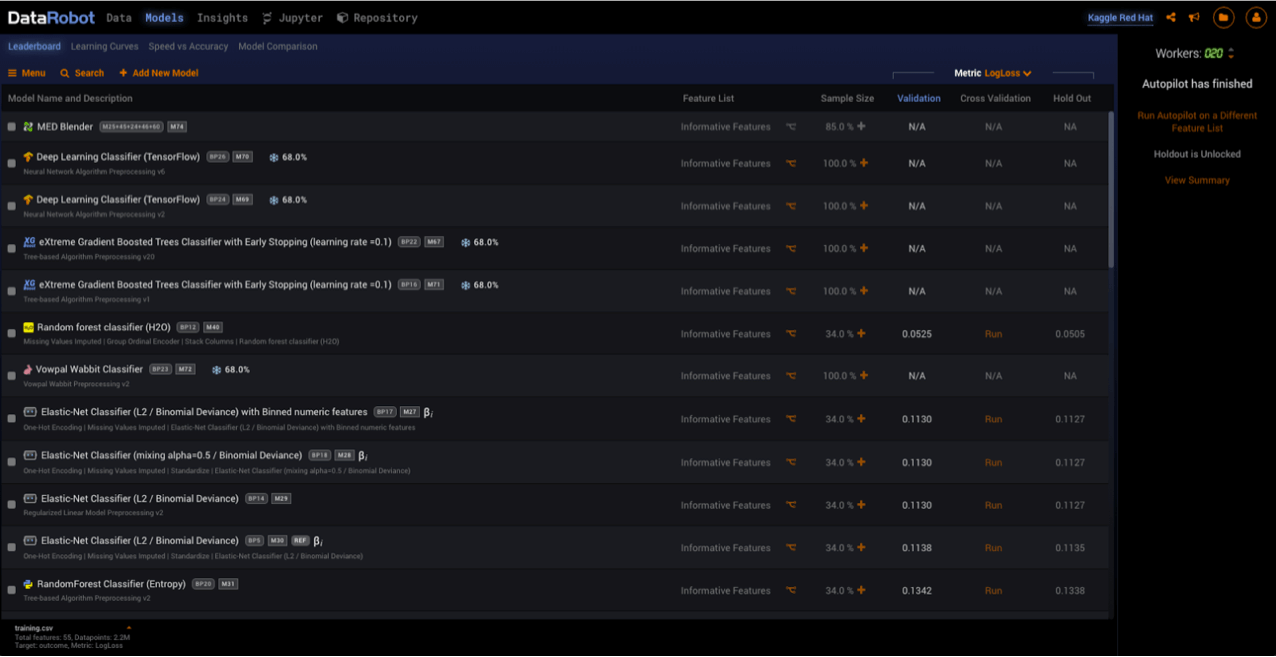
Step 3: Wait for my models to run on Autopilot.
The amount of time it takes to run through Autopilot is completely based on the size of your dataset. Me? I ran to my next meeting and then grabbed a coffee. Not sure what the time spent was, but it was ready for me on my return.
Step 4: From the Leaderboard rankings, pick the best model and run it using all of the training data.
(Time spent: 5 minutes)
Step 5: Select the best model trained on all of the data in the original dataset, upload the test dataset, and output predictions. I then apply a publicly posted leak method from Kaggle’s community forum and submit the results.
(Time spent: 15 minutes)
Results? Top 4%!

Must keep going. Another tip from Phil: run DataRobot’s TensorFlow deep learning models.
I run the TensorFlow models at 100% sample size (using all of the training data). Oops. (I’ll explain the oops in the lessons learned, below.) I then create a blend/ensemble model using my top model (XGBoost) along with the top two TensorFlow models. Perform Step 5 above again, and WAM! I’m in 27th place (Over 1000 competitors! Real data scientists!) and move up 19 places. Competing against the best data scientists in the world and I am in the top 2%. WHAT!?! I bust out into a silent victory dance at my desk.
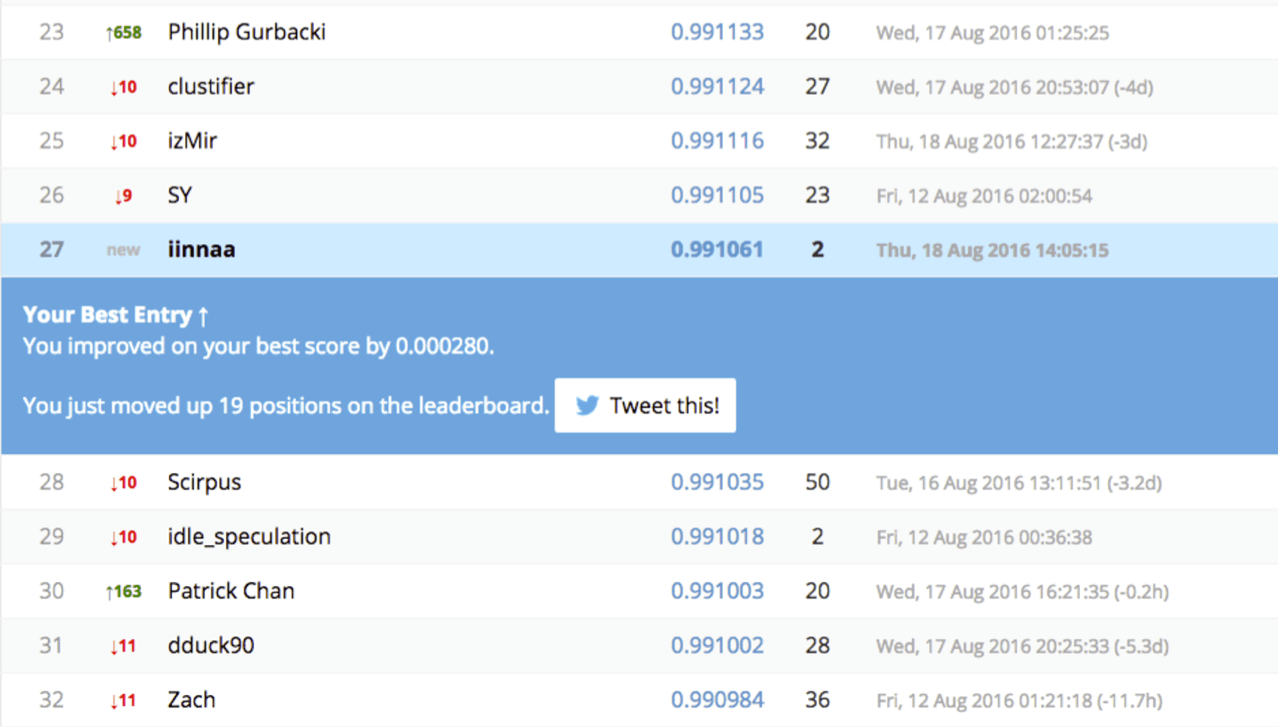
The point is, DataRobot is a powerful automated predictive modeling tool that landed a non-data scientist in the top 2% in a Kaggle competition. That’s insanely great.
Lessons Learned
First, I entered the competition and eagerly uploaded the data into DataRobot without understanding the business problem. That’s a BIG problem in the real world. Earlier in the year, I took a DataRobot University course that taught me the fundamental steps a Data Scientist should follow when solving a business problem. The first step is to define the project objectives, which involves specifying and understanding the business problem. How could I forget that?
The business problem this competition is trying to solve is to help Red Hat identify which customers have the most potential business value for Red Hat’s business, based on their characteristics and activities. Kaggle competitions are not the real world. Out of necessity, Kaggle competitions are somewhat contrived. In this competition, for example, all of the variables are encrypted, so it was difficult to interpret what, exactly, the columns/values in the dataset represented. In the real world, you really need to understand the business problem at hand in order to operationalize the model. But for Kaggle, accuracy is the most important, not how you would utilize the model in the real world.
Second, after running Autopilot, I decided to pick and choose some TensorFlow models that I wanted to manually run. Instead of following DataRobot’s fundamental flow of testing model results starting with a small sample size and then iteratively running the better performing models at a higher sample size percentage, I went all in and ran these at a 100% sample size. Because I ran this model using all the data from the initial dataset in one big bang, I wasn’t able to test the model against data that the model hadn’t seen before. This is a huge no-no in the real world. You should only run your model at 100% once you are done optimizing the model. Too excited, I guess. Another major reason not to do this is because running a complex model like TensorFlow can be computationally expensive; If you are unsure that this is the model you are going to operationalize, it’s not time to pay that computational price.
Third, I didn’t take advantage of another of DataRobot’s great strengths — the tools to visually identify important features I could have used to build better models and, as a result, provide better business insights. I could have viewed the importance of each feature in relation to the selected target or the model. The ranking measures how much each feature, by itself, is correlated with the target variable.
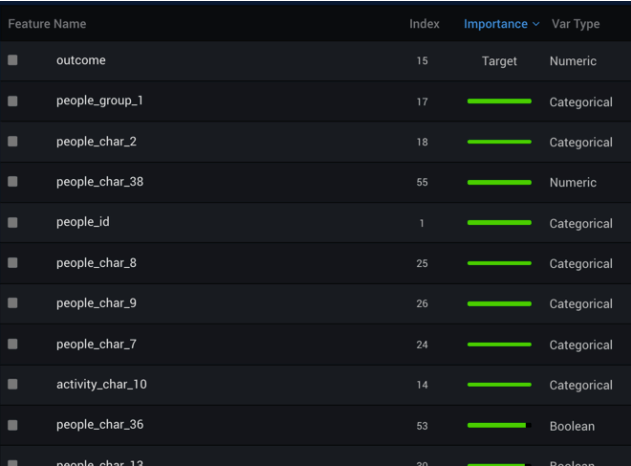
Or, the Feature Impact visualization, below, which measures how much each feature contributes to the accuracy of a model. Using those two, as a start (and there are many more) I could have tweaked my feature lists by seeing what what it is that really matters.
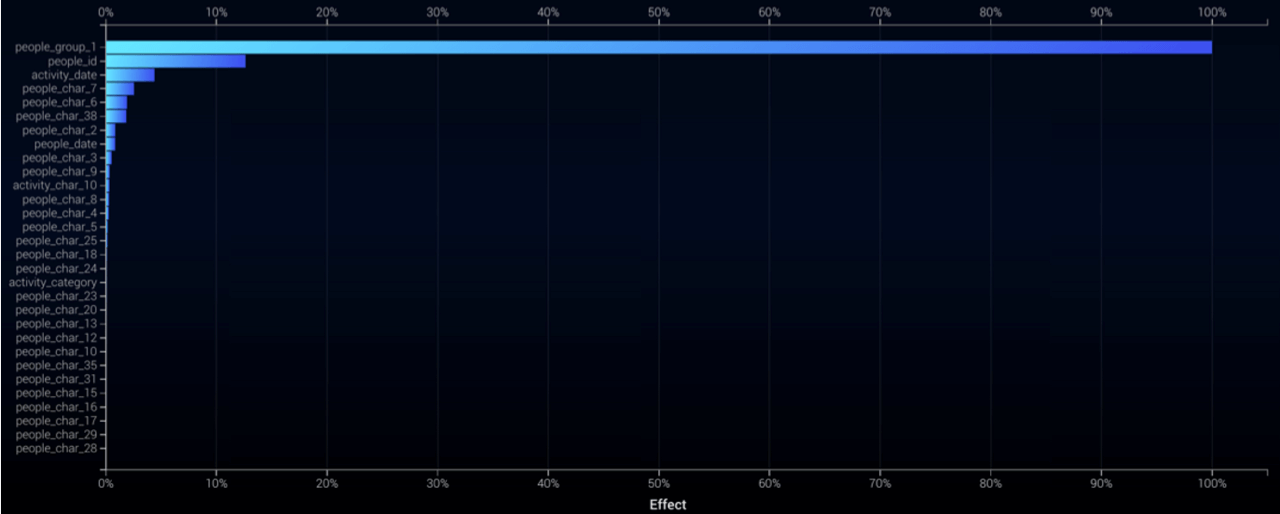
I didn’t do any of that. Essentially, testing and performing various feature engineering techniques hugely contributes to the best modeling results. Imagine how much better I potentially could have done if I had performed some basic feature engineering — easily done with the resources I had at hand.
What I Did Right
I am not by any means an expert R, Python, or SAS programmer. All I did was upload data, choose a feature/target to predict, and click Start. I was essentially able to “set it and forget it;” my models were complete and ordered on the Leaderboard when I returned from my afternoon meetings. I think maybe the best thing I did was to trust the giants that built DataRobot and provided me with a top 2% model against the Kaggle competitors.
I obtained my best model results by blending models. Easy to do, I just selected a few of the top models on the Leaderboard and created the blend from a dropdown menu.
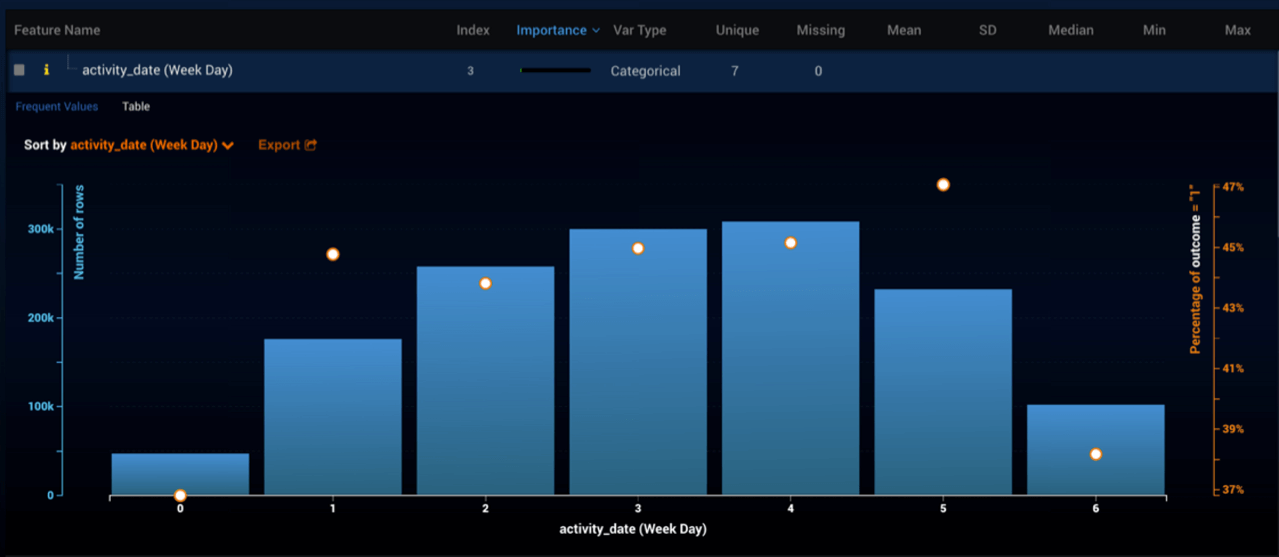
DataRobot has some neat visualizations which helped the business analyst in me understand the data I was working with while the fiery competitor in me could, in the same tool, build and tweak models. For example, a really simple and interesting visualization I used showed the distribution of data points across the days of the week (0 is Sunday, 6 is Saturday).
Conclusion
I’m a Business Analyst; I have knowledge of business intelligence tools but not of advanced analytics or machine learning. DataRobot provided me with the best practices of the world’s leading data scientists. It automatically tested hundreds of predictive models, found the optimal one for my Kaggle data, and vaulted me, in a matter of hours, to the top 2% of a renowned data science competition. I started this exercise to better understand my target end user and came away feeling really good about making space for you up on the shoulders of giants.
Notes:
- This blog post was written based on a submission made in mid-August 2016. Because I was not actively making submissions, my ranking in the Red Hat competition dropped. I finished in the top 7%.
- I did not beat Phil on the Kaggle public leaderboard. Even so, I did do really well for a person that does not code… cue the happy desk dance!


Ina is focused on building the product strategy, vision, and mission for new capabilities that help business users and executives realize tangible value out of AI. Ina is an analyst-turned-product manager with over 10 years of experience building and commercializing capabilities in artificial intelligence and enterprise performance management.
-
How to Choose the Right LLM for Your Use Case
April 18, 2024· 7 min read -
Belong @ DataRobot: Celebrating 2024 Women’s History Month with DataRobot AI Legends
March 28, 2024· 6 min read -
Choosing the Right Vector Embedding Model for Your Generative AI Use Case
March 7, 2024· 8 min read
Latest posts
