

A Primer on Deep Learning
Deep learning has been all over the news lately. In a presentation I gave at Boston Data Festival 2013 and at a recent PyData Boston meet-up I provided some history of the method and a sense of what it is being used for presently. This post aims to cover the first half of that presentation, focusing on the question of why we have been hearing so much about deep learning lately. The content is aimed at data scientists who might have heard a little about deep learning and are interested in a bit more context. Regardless of your background, hopefully you will see how deep learning might be relevant for you. At the very least, you should be able to separate the signal from the noise as the media hype around deep learning increases.
What is deep learning?
I like to use the following three-part definition as a baseline. Deep learning is:
- a collection of statistical machine learning techniques
- used to learn feature hierarchies
- often based on artificial neural networks
That’s it. Not so scary after all. For sounding so innocuous under the hood, there’s a lot of rumble in the news about what might be done with DL in the future. Let’s start with an example of what has already been done to motivate why it is proving interesting to so many.
What does it do that couldn’t be done before?
We’ll first talk a bit about deep learning in the context of the 2013 Kaggle-hosted quest to save the whales. The game asks its players the following question: given a set of 2-second sound clips from buoys in the ocean, can you classify each sound clip as having a call from a North Atlantic right whale or not? The practical application of the competition is that if we can detect where the whales are migrating by picking up their calls, we can route shipping traffic to avoid them, a positive both for effective shipping and whale preservation.
In a post-competition interview competition’s winners noted the value of focusing on feature generation, also called feature engineering. Data scientists spend a significant portion of their time, effort, and creativity working on engineering good features; in contrast, they spend relatively little time running machine learning algorithms. A simple example of an engineered feature would involve subtracting two columns and including this new number as an additional descriptor of your data. In the case of the whales, the winning team represented each sound clip in its spectrogram form and built features based on how well the spectrogram matched some example templates. After that, they then subsequently iterated new features that would help them correctly classify examples that they got wrong through the use of a previous set of features.
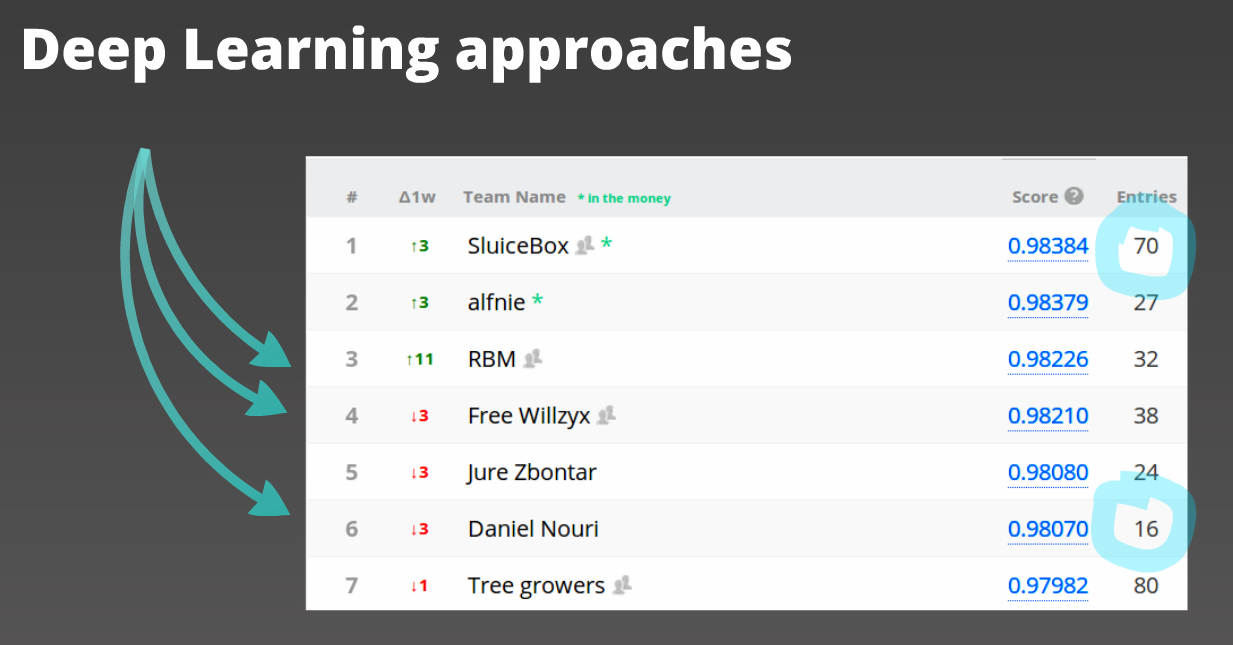
This is a look at the final standings for the competition. The results within the top contenders were pretty tight, and the winning team’s focus on feature engineering paid off. But how is it that several deep learning approaches could be so competitive while at the same time using as few as one fourth the submissions? One answer to that question arises from the unsupervised feature learning that deep learning can do. Rather than using data science experience, intuition, and trial-and-error, unsupervised feature learning techniques spend computational time automatically developing new ways of representing the data. The end goal is the same, but the experience along the way can be drastically different.

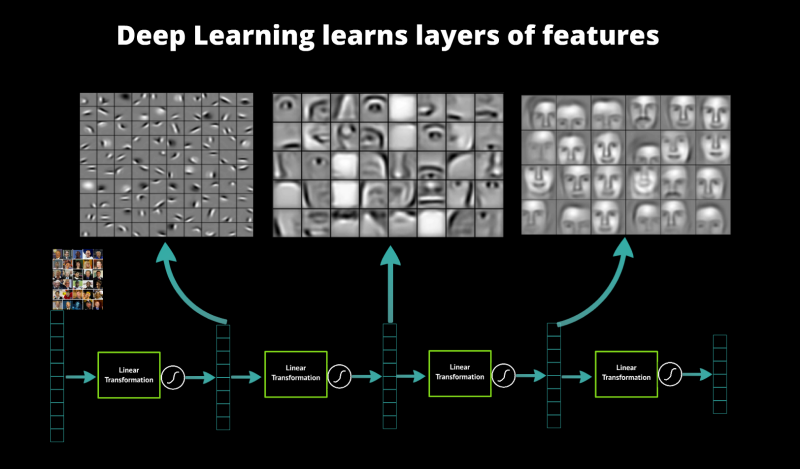
This is not to say that ‘deep learning’ and ‘unsupervised learning’ are necessarily the same concept. There are unsupervised learning techniques that have nothing to do with neural networks at all, and you can certainly use neural networks for supervised learning tasks. The takeaway is that deep learning excels in tasks where the basic unit, a single pixel, a single frequency, or a single word has very little meaning in and of itself, but the combination of such units has a useful meaning. It can learn these useful combinations of values without any human intervention. The canonical example used when discussing the deep learning’s ability to learn from data is the MNIST dataset of handwritten digits. When presented with 60,000 digits a neural network can learn that it is useful to look for loops and lines when trying to classify which digit it is looking at.  On the left, the raw input digits. On the right, graphical representations of the learned features. In essence, the network learns to “see” lines and loops.
On the left, the raw input digits. On the right, graphical representations of the learned features. In essence, the network learns to “see” lines and loops.
Why the new-found love for Neural Networks?
Is this old wine in new wineskins? Is this not just the humble neural network returning to the foreground?
Neural networks soared in popularity in the 1980S, peaked in the early 1990s, and slowly declined after that. There was quite a bit of hype and some high expectations, but in the end the models were just not proving as capable as had been hoped. So, what was the problem? The answer to this question helps us get around to understanding why this is called “deep learning” in the first place.

Neural networks get their representations from using layers of learning. Primate brains do a similar thing in the visual cortex, so the hope was that using more layers in a neural network could allow it to learn better models. Researchers found that they couldn’t get it to work, though. They found that they could build successful models with a shallow network, one with only a single layer of data representation. Learning in a deep neural network, one with more than one layer of data representation, just wasn’t working out. In reality, deep learning has been around for as long as neural networks have – we just weren’t any good at using it.
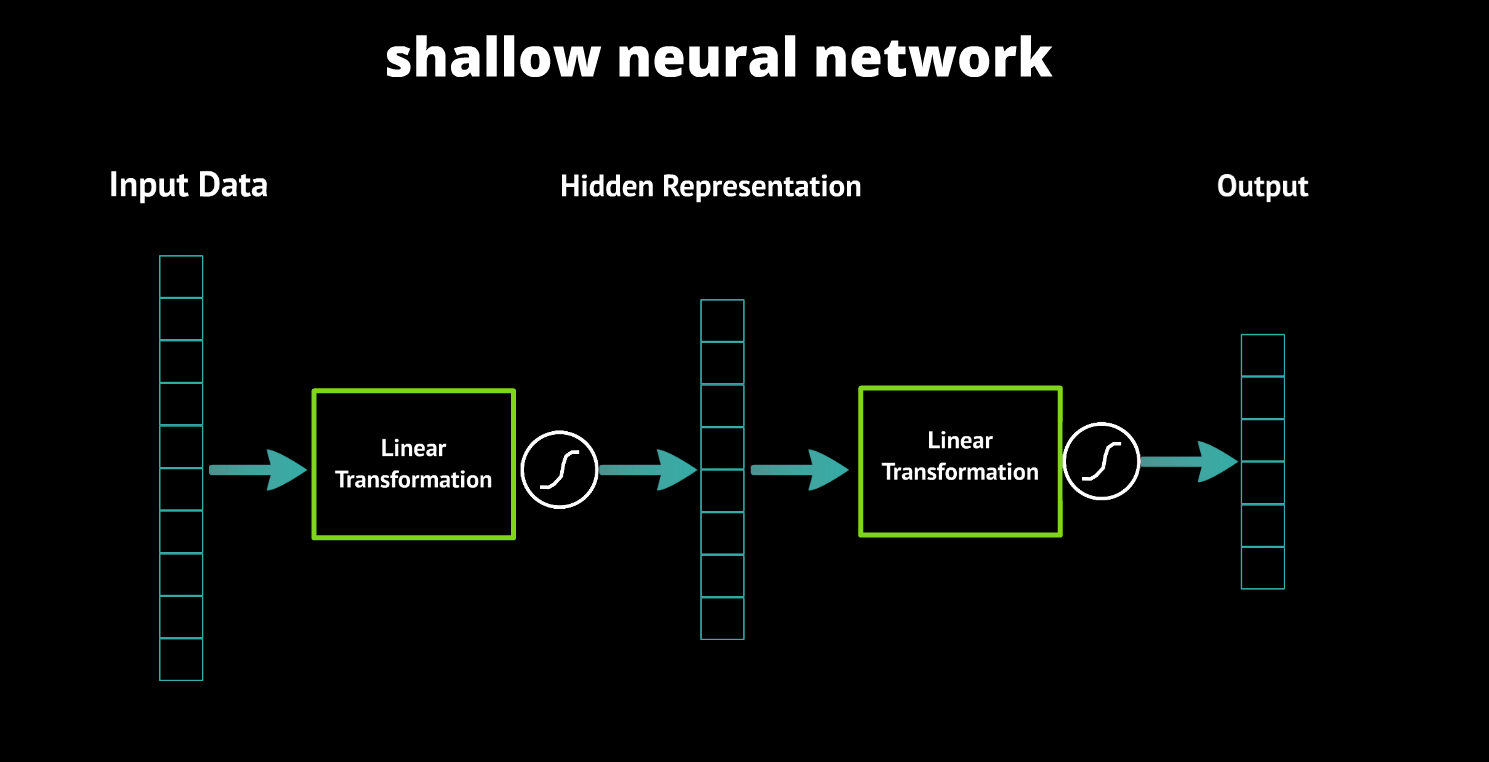
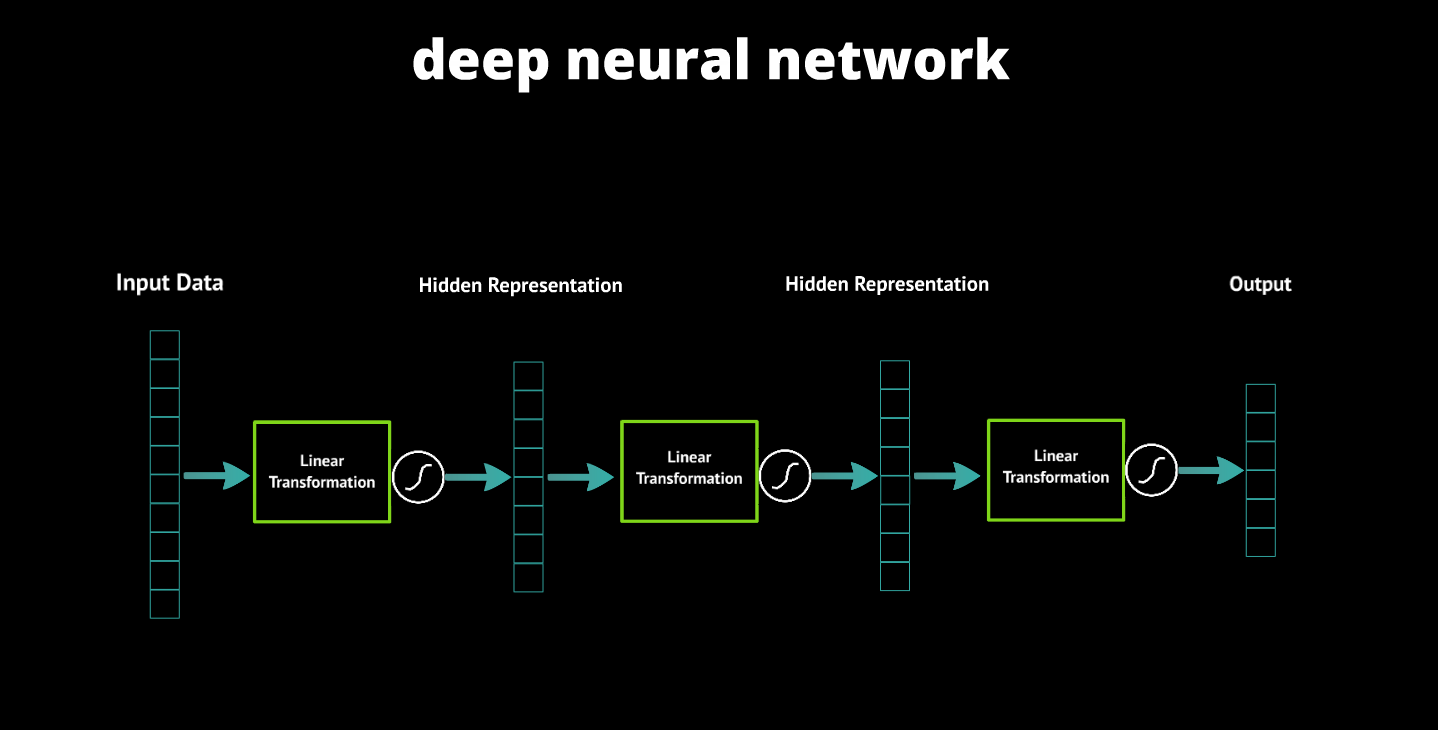 Deep neural networks have more than one hidden layer. It really is that simple.
Deep neural networks have more than one hidden layer. It really is that simple.
So, what changed?
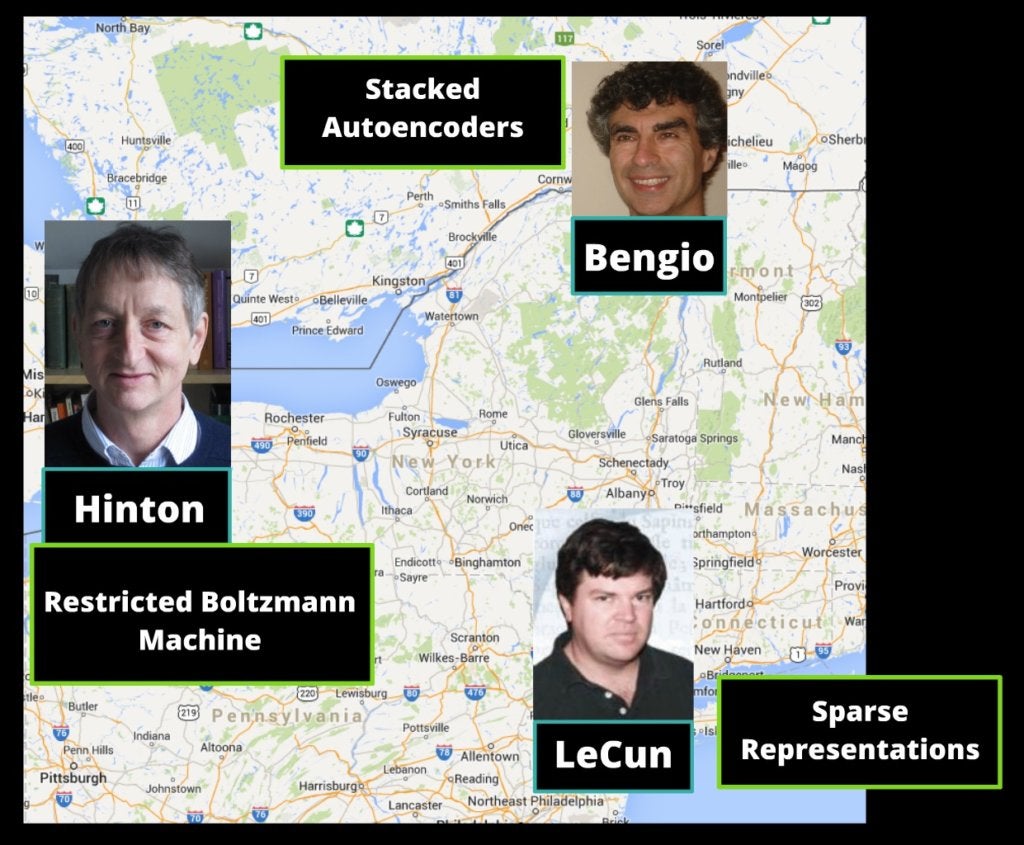
Finally in 2006 three separate groups developed ways of overcoming the difficulties that many in the machine learning world encountered while trying to train deep neural networks. The leaders of these three groups are the fathers of the age of deep learning. This is not at all hyperbole; these figures ushered in a new epoch. Their work breathed new life into neural networks when many had given up on their utility. A few years down the line, Geoff Hinton has been snatched up by Google; Yann LeCun is Director of AI Research at Facebook; and Yoshua Bengio holds a position as research chair for Artificial Intelligence at University of Montreal, funded in part by the video game company Ubisoft. Their trajectories show that their work is serious business.
What was it that they did to their deep neural networks to make it work? The topic of how their work enables this would merit its own lengthy discussion, so for now please accept this heavily abbreviated version. Before their work, the earliest layers in a deep network simply weren’t learning useful representations of the data. In many cases they weren’t learning anything at all. Instead they were staying close to their random initialization because of the nature of the training algorithm for neural networks. Using different techniques, each of these three groups was able to get these early layers to learn useful representations, which led to much more powerful neural networks. Each successive layer in a neural network uses features in the previous layer to learn more complex features.
Now that this problem has been fixed, we ask, what is it that these neural networks learn? This paper illustrates what a deep neural network is capable of learning, and I’ve included the above picture to make things clearer. At the lowest level, the network fixates on patterns of local contrast as important. The following layer is then able to use those patterns of local contrast to fixate on things that resemble eyes, noses, and mouths. Finally, the top layer is able to apply those facial features to face templates. A deep neural network is capable of composing more and more complex features in each of its successive layers.
This automated learning of data representations and features is what the hype is all about. This application of deep neural networks has seen models that successfully learn useful representations of imagery, audio, written language, and even molecular activity. These have been previously been some hard problems in machine learning, which is why they get so much attention. Don’t be surprised if deep learning is the secret ingredient in even more projects in the future.
The above touches on most of the points I made in the first half of the presentation, a presentation I hope makes for a useful primer on deep learning. The key takeaway is that the breakthroughs in 2006 have enabled deep neural networks that are able automatically to learn rich representations of data. This unsupervised feature learning is proving extremely helpful in domains where individual data points are not very useful but many individual points taken together convey quite a bit of information. This accomplishment that has proven particularly useful in areas like computer vision, speech recognition, and natural language processing.
The second half of the talk was a whirlwind tour through the topics that fall under the umbrella term of ‘deep learning’. Feel free to contact me by email or leave a comment below if there are any questions you have or if you’d like pointers on where to find additional material.

-
How to Choose the Right LLM for Your Use Case
April 18, 2024· 7 min read -
Belong @ DataRobot: Celebrating 2024 Women’s History Month with DataRobot AI Legends
March 28, 2024· 6 min read -
Choosing the Right Vector Embedding Model for Your Generative AI Use Case
March 7, 2024· 8 min read
Latest posts
