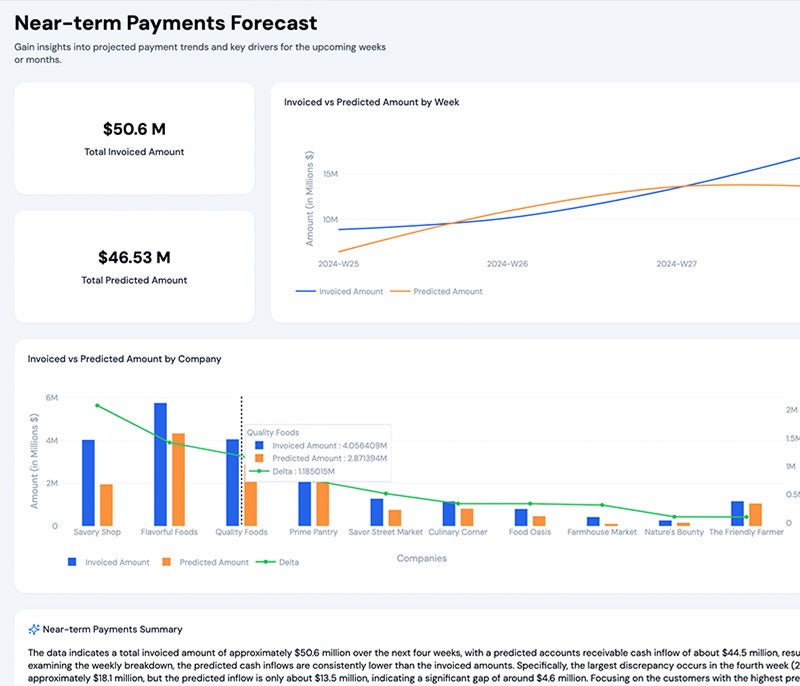
Building and scaling agentic AI applications is complex—requiring orchestration, governance, and seamless compute management. DataRobot streamlines the process, enabling AI teams to deploy, monitor, and optimize multi-agent workflows across cloud, on-prem, and hybrid environments.