

Building the Models for Relationships by DataRobot
This is part 3 of a series of blog posts detailing the development of the Relationships by DataRobot web app. Here are Parts 1 and Parts 2.
Preliminary Notes on Optimization Criteria
There are many different reasons to build a predictive model. In some cases, predictive accuracy is the number one priority; i.e., getting predictions that are more accurate than any other model. In those cases, detailed feature engineering, complex ensembling methods, stacking, and other approaches are both common and effective.
In this case, though, for fun we’re trying to build a simple quiz application that a user can interact with in order to get a prediction. Of course, model accuracy is important — i.e., we want to make good predictions — but there are lots of highly accurate models that do not represent feasible solutions to this problem. Building a model with 50 features, for instance, might be accurate, but there’s little chance that someone is going to answer a 50-question survey just to get a prediction, so the main modeling task here was simplifying the feature pool down to a manageable number of features. Ideally, between five to ten features, while maintaining an acceptable level of accuracy.
Similarly, relationships are sensitive topics, so since we’re ultimately trying to create a survey that will be fun and informative at the same time, we avoided controversial or too-personal questions, even if it meant the models were a little bit less accurate. One of the necessary truths of data science is that building a model that people aren’t comfortable using is about as helpful as not building any model at all.
So, did we push DataRobot to its limits? No. Are we presenting the most accurate models possible? No. Did we produce an application that people will find enjoyable and informative? I hope so. Try it out, and send us some feedback.
Getting Started
Once I prepared the data (see here for how this happened), I was ready to get started with the modeling. (Quick reminder: the target in this project is a binary indicator of whether or not a relationship will break up within the upcoming two years.) This is pretty straightforward with DataRobot. I dragged the dataset into DR and ran autopilot — which automatically sets up cross-validation, considers various transformations of the data, imputes missing values, and a whole bunch of other preprocessing stuff. My plan was to run DataRobot, which is built to identify the most accurate model, on all of the data and use those results to determine the right next steps.
DataRobot’s autopilot automatically runs dozens of open source algorithms against the dataset, comparing the performance of XGBoost against GLM’s against random forests, and so on.
The best model on all the data
The modeling dataset is pretty small in this case. There are a little over 3,100 observations and 110 features. Because the dataset is super small, it’s not too surprising that the best models are mostly GLM’s. The best model out of DataRobot uses a Ridit transform to standardize the variables, does median imputation, and fits an elastic net in order to perform regularization. DataRobot does a grid search over the tuning parameters, and we end up with pretty strong models (out-of-sample AUC=0.897, for data scientists out there).
Because the model considers so many features, I knew I probably wouldn’t be able to use the best model in this set, but I wanted to see which features ended up being the most important. Remember, what I need is a very small number of interesting features that still produce a good result. Here is the relative importance for the top 40 features in the first model:

A few things stand out here to me:
- Living together and marital status are the top two variables. Lots of correlation between those two variables. As it turned out, as you start to reduce the number of features, marital status become a more important predictor than whether or not a couple is living together.
- There are lots of time-based variables. It turns out that age, age gap, duration of relationship, how long a couple dated before getting married, and so on are, not surprisingly, very predictive of relationship stability and duration. In fact, our first round of models after this focused a little too much on time. The survey questions became too repetitive, so we had to scale that back.
- Education, religion, and income variables all show up towards the top of the list. We were cautious of including some questions in this category. We wanted to be sure that we didn’t ask people to give us sensitive information that might make them feel uncomfortable.
What followed was a mixture of analytical — like ridge regression, for example — and subjective steps to reduce the complexity of the models down to just a few interesting, but non-invasive and non-offensive features.
Some interesting things that we learned along the way:
- Relationships are pretty robust. 94% of the people in the Stanford study that these models are based on stayed together. The folks involved in this study weren’t casually dating, but were instead involved in committed, monogamous relationships. Those tend to last. This was heartwarming to me.
- The more external acts of commitment that a couple makes, the more likely they are to stay together. I suppose this isn’t a surprise. The average prediction for a married couple in the holdout data was greater than 97%, while the average score for unmarried people was quite a bit lower,
- The data seems to support some very traditional sensibilities. For example, married couples that lived together before they got married are slightly more likely to break up than those that didn’t. This appeared to be true across all the models that we built — even though this feature didn’t make it into our final models.
- Having a big extended family that you interact with regularly appears to make your relationship last longer. This seems to make intuitive sense.
- Children are stressful, but only for a little while. The data included counts of children in the household of certain ages. It turned out that having more children between 2 and 5 years old in the house is correlated with an increase in break-ups. This wasn’t true for children of other ages. The message for parents here is HOLD ON for a few more years!
The final model
DataRobot makes it easy to iterate on different modeling approaches. In fact, I ended up writing a few lines of code in my jupyter notebook to just send the dataframe up to DataRobot to start the modeling. It looked like this:
import datarobot as drnewProject = dr.Project.create(df, project_name=’HCMST — final’)
ao = dr.AdvancedOptions(weights='weight1')
newProject.set_target(target='broke_up'
, metric='Weighted LogLoss'
, advanced_options=ao
, mode=dr.AUTOPILOT_MODE.FULL_AUTO
, worker_count=20)
The final model ended up being a relatively simple logistic regression model with elastic net with median imputation and simple standardization. The standardized model coefficients for the model look like this:
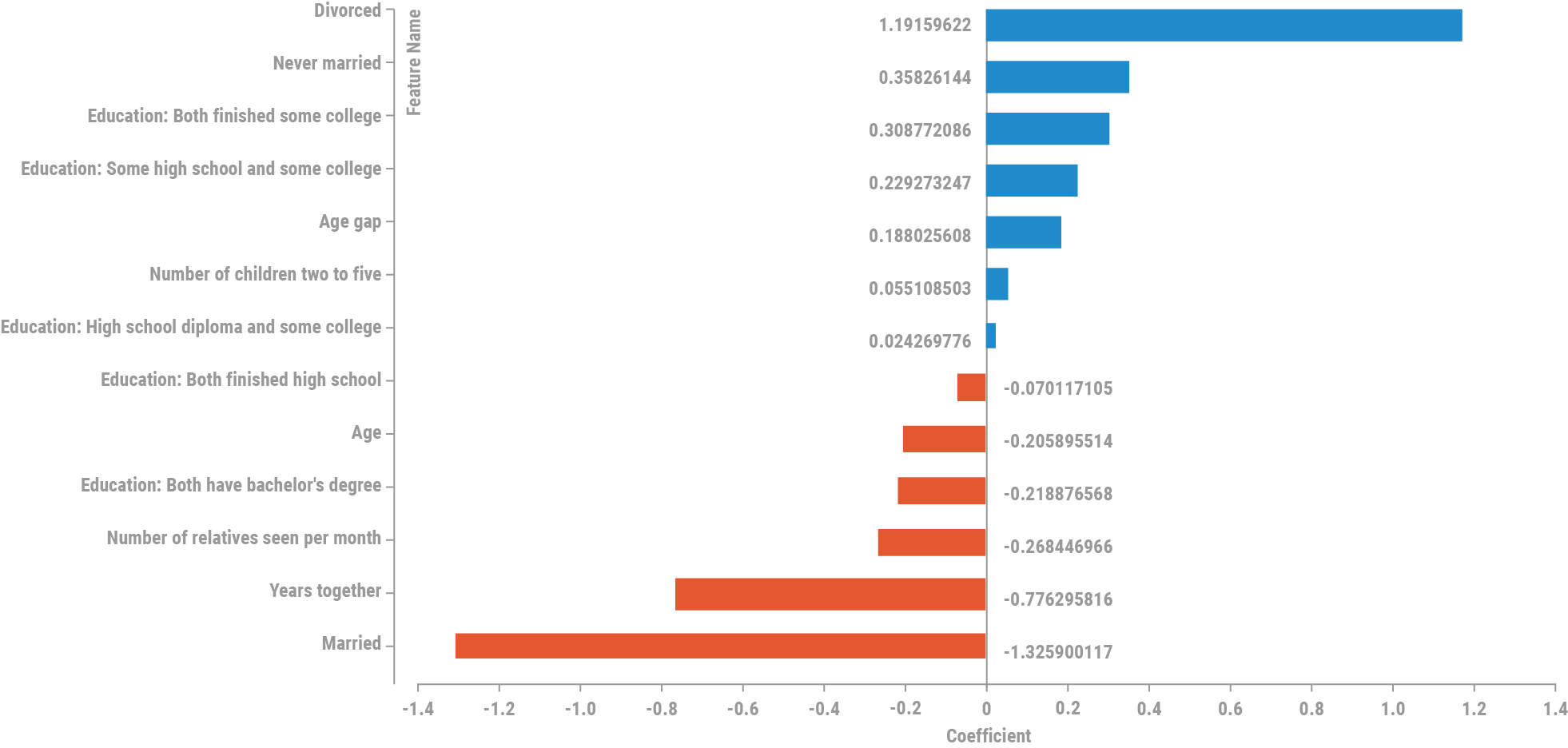
Keep in mind that the quiz converts all the break-up probabilities to stay-together probabilities, so a large coefficient here indicates a higher chance of a break-up in the next two years; i.e., a lower chance of staying together.
All in all, the process of building models in DataRobot is a pleasure. The literal hundreds of iterations that we did took moments to perform, and any data issues were easy to identify and eliminate. We were able to fit and evaluate nearly every model class, from XGBoost to deep learning to random forests to SVM’s, and in the end, as is often the case, simpler was better.

Final thoughts
DataRobot is all about making data science accessible to more people. The models that we built here aren’t going to win any awards for complexity or accuracy, and we didn’t come close to stretching DataRobot’s capabilities. That wasn’t the point of this exercise.
What’s interesting to me is that every model that we built could have been built by anyone with just a little bit of training. Data science has the power to transform the way business is done in every industry in the world today. Some organizations are further ahead than others, but the main obstacle to using data science is finding and retaining data scientists in most cases. DataRobot has the potential to increase the pool of people who are able to solve these kinds of problems, and that means more revenue, more efficiency, and better outcomes.
I hope that having walked through our thought process at a high level has been interesting and helpful. Please feel free to send us comments and questions with the link in the application. We’ll be monitoring these and watching for what you have to say!
Keep Reading!
- Introduction and Background to Relationships by DataRobot
- Preparing the Data for Relationships by DataRobot
- Building the Models for Relationships by DataRobot
- An Inside Look at the Design Process for Relationships by DataRobot
-
How to Choose the Right LLM for Your Use Case
April 18, 2024· 7 min read -
Belong @ DataRobot: Celebrating 2024 Women’s History Month with DataRobot AI Legends
March 28, 2024· 6 min read -
Choosing the Right Vector Embedding Model for Your Generative AI Use Case
March 7, 2024· 8 min read
Latest posts
