

Data Science Under GDPR: What Will Change?
The European Union (EU) is about to introduce new obligations for companies handling and analysing data about EU citizens. The General Data Protection Regulation (“GDPR”) will take effect on May 25th, 2018, in order to keep pace with the modern digital information landscape. The regulation aims to reinforce the data privacy rights of consumers, and to simplify the flow of information between EU countries by standardizing the data protection framework.
 GDPR will take effect in the European Union on 25th May 2018
GDPR will take effect in the European Union on 25th May 2018Any company that stores or processes data from the 750 million European citizens must comply, including US or Asian companies selling goods and services in the EU. For example, if your company analyzes information about the EU citizens that have visited your website, then you must also comply with the regulation. The fines for not complying with GDPR could be up to 4% of their global annual turnover – or €20 million, whichever is greater. Given the magnitude of the penalties, GDPR compliance has been a priority on the agenda of the board at most global firms. In a survey issued by PwC in 2017, more than half of the IT executive respondents among American global companies considered GDPR among their top priorities.
A large impact on the AI-driven enterprise
Most of the commentary about GDPR focuses on how companies collect and store data, and govern access to data. However, this commentary has largely avoided the implications for AI solutions. In particular, how will machine learning applications be affected by GDPR?
The obligation of consent and the ability to opt out
GDPR now clearly defines automated data processing with the term “profiling” in the Article 4. Profiling is defined in the following way:
- It consists of an automated form of data processing.
- It uses personal data.
- Its purpose is to evaluate personal aspects about an individual.
Any profiling on EU citizens needs to comply with GDPR regardless of where the company is based.
According to the articles 21 and 22 of GDPR, any profiling activity that “significantly affect or has a legal effect on him or her” falls under these strict regulations:
- The profiling has to be legally authorized in the country where the consumer resides.
- The company and the consumer must enter into a contract, which includes legal consent from the consumer and the ability to opt out.
GDPR officialises the activities that fall under these agreements, expanding beyond industries like social media, mobile, and credit cards that already use similar forms. For example, pricing optimisation in insurance or retail, and personalised marketing or telecom network optimisation will require explicit consent from the customer and provide him or her the ability to opt out.
Transparency and the Right to Explanations
Providing reasons for automated decisions has existed for years in some regulated industries; for example, U.S credit providers must give explanations when a credit card application is declined.
The articles 13 to 15 of GDPR stipulate that the data subject possesses the right to access “meaningful information about the logic involved, as well as the significance and the envisaged consequences” of automated decision-making systems, such as profiling. This indicates that companies should attempt to provide sufficient transparency about the logic of their machine learning systems based on personal data.
There is controversy among scholars and lawyers about whether this language actually gives a full “right to explanations”, for each individual decision made by the system. The non-binding Recitals of GDPR, however, provide more insight to understand the regulation — profiling activities “should be subject to suitable safeguards, which should include […] the right to obtain an explanation of the decision reached after such assessment” (Recital 71).
Providing reasons for automated decisions has existed for years in some regulated industries; for example, U.S credit providers must give explanations when a credit card application is declined. Under GDPR, explainability is likely to become a standard for all profiling activities.
Discrimination and Model bias
Finally, one important aspect of GDPR is the type of personal data it disallows companies from using, in order to prevent discrimination:
“Processing of personal data revealing racial or ethnic origin, political opinions, religious or philosophical beliefs, or trade union membership, and the processing of genetic data, biometric data for the purpose of uniquely identifying a natural person, data concerning health or data concerning a natural person’s sex life or sexual orientation shall be prohibited.”
For automated profiling systems, the Recital 71 again gives more context:
- Companies “should use appropriate mathematical or statistical procedures for the profiling”.
- Data inaccuracies should be corrected and the risk of errors should be minimised.
- Personal data should be secured in a manner that prevents discriminatory effects.
However, discrimination and model bias cannot be entirely eliminated by excluding sensitive data since other related factors might be present in the data. For example, a consumer’s neighbourhood could indirectly indicate ethnic origin. Recent research shows that even excluding these related factors may not be sufficient to treat discriminatory effects. Therefore, it’s likely that regulators will mostly pay attention to how the data is used and interpreted. Making the algorithms as explainable as possible will become extremely important.
How DataRobot helps comply with GDPR
In summary, GDPR will have a profound impact on the way modern organisations build their automated decision systems. Teams using machine learning for profiling will, in particular, need to follow strict guidelines to ensure:
1. They provide explanations about the decisions from the models and document the logic.
With Reason Codes, DataRobot can explain any automated decision from machine learning models. If you build a profiling system with DataRobot, you can export the most influential factors affecting each individual outcome from the model. This allows the users to get clear explanations to anyone making decisions based on the model predictions. Even the most complex models built in DataRobot can leverage Reason Codes.
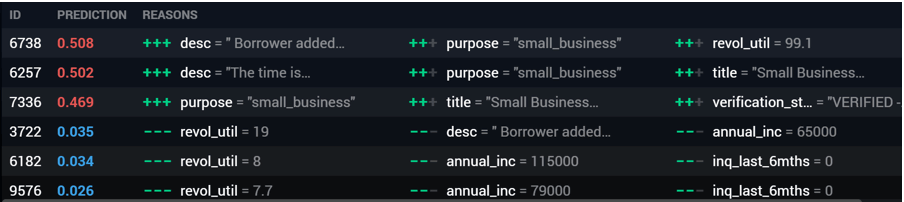 DataRobot Reason Codes can explain the main factors underlying individual model decisions
DataRobot Reason Codes can explain the main factors underlying individual model decisionsMoreover, if your organisation uses multiple profiling models under GDPR, the various modelling teams are likely to need a standardised way to document model logic in order to be GDPR-ready for their clients. DataRobot provides multiple tools to document and interpret the datasets used and the important factors in the models built, including the logic involved. The documentation process can then be customised for your organisation by leveraging the DataRobot API.
2. They can demonstrate to regulators that models do not use unfair discrimination
DataRobot developed Model X-Ray to solve this problem. Based on a technique called partial dependence analysis, Model X-Ray provides a visual display of the effect of a factor on the outcome of the model, after accounting for the effects of all other factors. The user can see immediately how a model behaves over the full range of possible values. Model X-Ray provides a straightforward way to demonstrate the behavior of a model to stakeholders and regulators. Model X-ray also helps control potential bias by showing the outcomes over different segments of the population in the dataset.
Moreover, a key aspect for regulators is to make the modelling approaches reproducible. Automation is a great way to achieve reproducibility. DataRobot, for a given dataset, uses automated blueprints that create models based on data science best practices. This helps modern organisations standardise model building, interpretation, and deployment at a large scale.
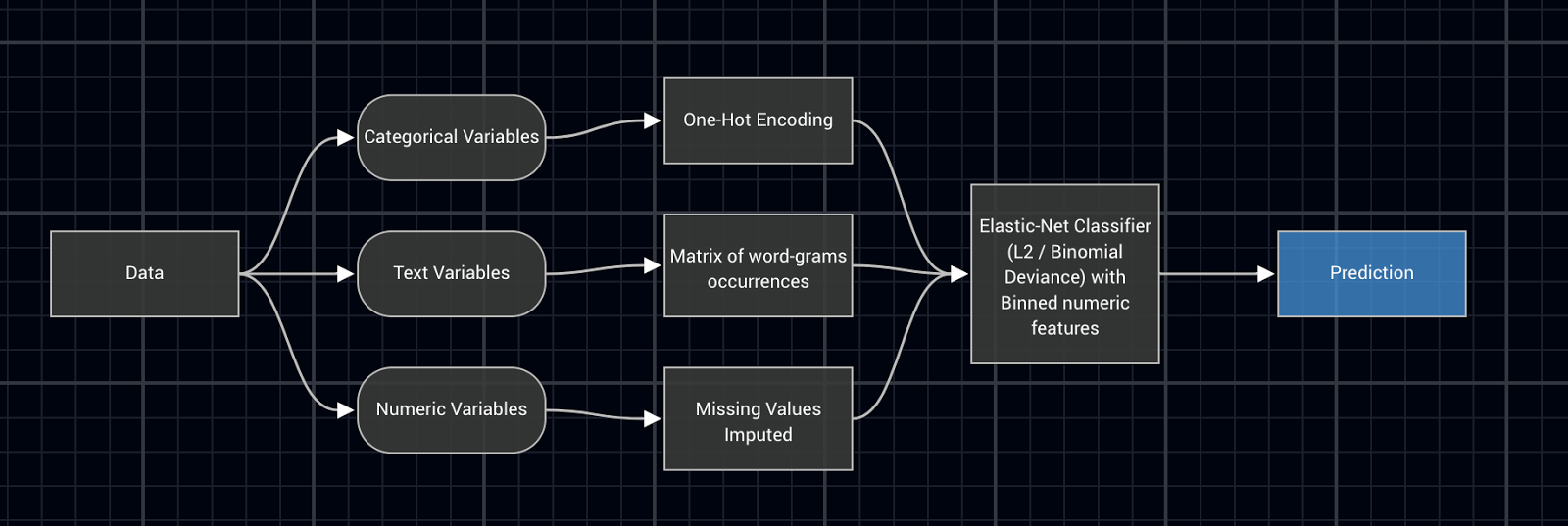 DataRobot blueprints automate the modelling process and ensure reproducibility
DataRobot blueprints automate the modelling process and ensure reproducibility3. The modelling approach is not biased and the risk of error is minimised.
Automated Machine Learning provides multiple safeguards to prevent bias from the modellers. DataRobot uses an agnostic approach to test dozens of predictive algorithms and minimizes errors by applying guardrails that are based on data science best practices. The modellers can now choose the most appropriate algorithms for each problem, instead of relying on their own individual (and potentially biased) experience.
In summary, if your organisation processes personal data from EU individuals, you will need to make an inventory of all the business processes and automated decision systems based on this data, and then develop a strategy for GDPR compliance. If DataRobot is your machine learning platform, you can relax a bit: your data science team is well on its way to complying with GDPR, when it comes to models. If not, you may have some sleepless nights in the coming year.
Any opinion expressed in this article may only be attributed to its Author, and as such may not reflect the opinions of DataRobot, nor of DataRobot’s board, editors, writers, and readers. Likewise, DataRobot is not responsible for the accuracy of any information posted by any Author.

About the Author
André Balleyguier is a Lead Client-Facing Data Scientist at DataRobot, based in London. He advises businesses across EMEA on how they can leverage Data Science and DataRobot to resolve some of their toughest business problems. André has worked with most of the early customers of DataRobot in Europe, and his experience ranges across various industries such as insurance, marketing, banking, and telecommunications. He initially joined the company as part of the core Data Science team, developing the algorithms inside the DataRobot platform.

-
How to Choose the Right LLM for Your Use Case
April 18, 2024· 7 min read -
Belong @ DataRobot: Celebrating 2024 Women’s History Month with DataRobot AI Legends
March 28, 2024· 6 min read -
Choosing the Right Vector Embedding Model for Your Generative AI Use Case
March 7, 2024· 8 min read
Latest posts
