

Four Steps to Take After Training Your Model: Realizing the Value of Machine Learning
So, you have successfully trained a machine learning model after choosing the best algorithm and high-quality training data. Time to celebrate, right?
Not quite!
The best machine learning algorithms and models are of no use until you actually apply them to make predictions on future outcomes. Then, you must incorporate those predictions into your decision making. The business value of machine learning is realized only when it alters behavior to produce positive outcomes.
In this blog post, we’ll look at how to derive value from a DataRobot model that is designed to answer the following question:
“Which patients are more likely to be readmitted to the hospital?”
Properly addressing this question requires you to periodically review new patients from the hospital’s systems, scrub them for quality, make predictions, and feed the results back into the hospital’s systems for driving action.
Training, testing, and fine-tuning your model is the first part. The subsequent four steps are as follows:
1. Deploy the model
Make the model available for predictions. In DataRobot, you do this by creating a deployment. This involves selecting an algorithm (usually the best performing model from the training process). You also specify the training dataset which is used as a baseline to detect model drift.
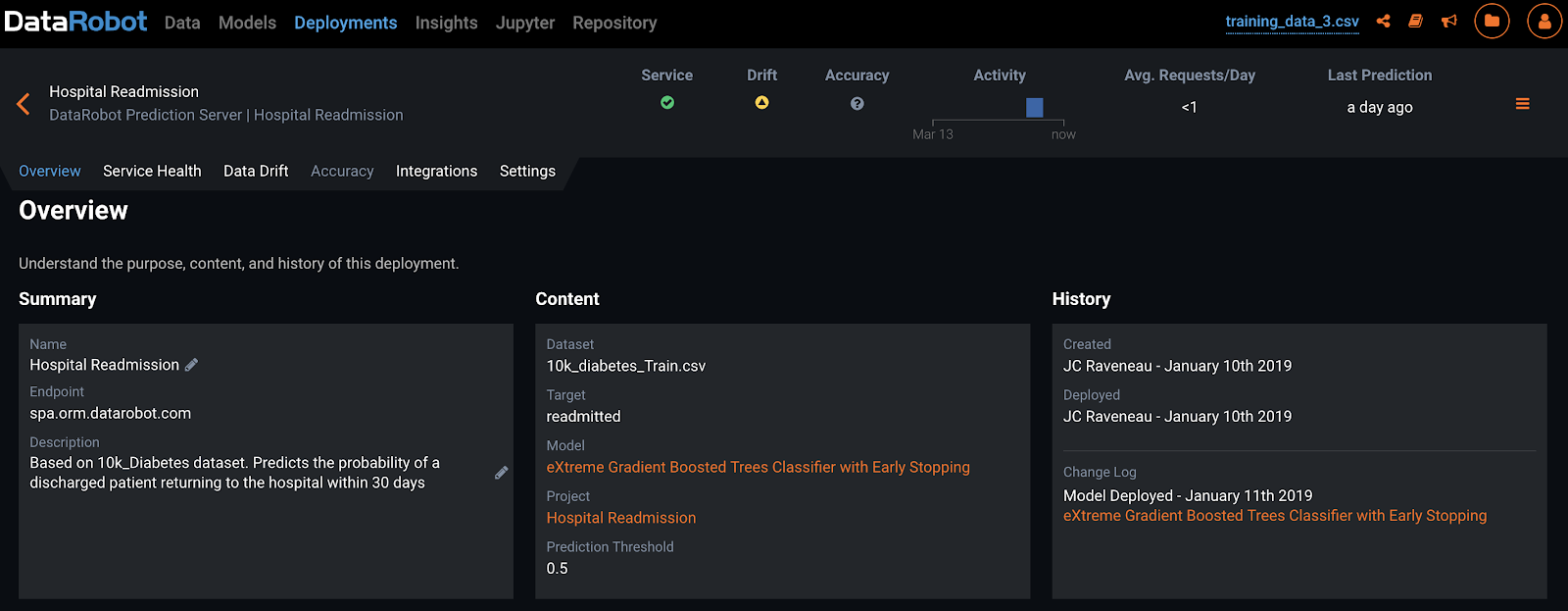
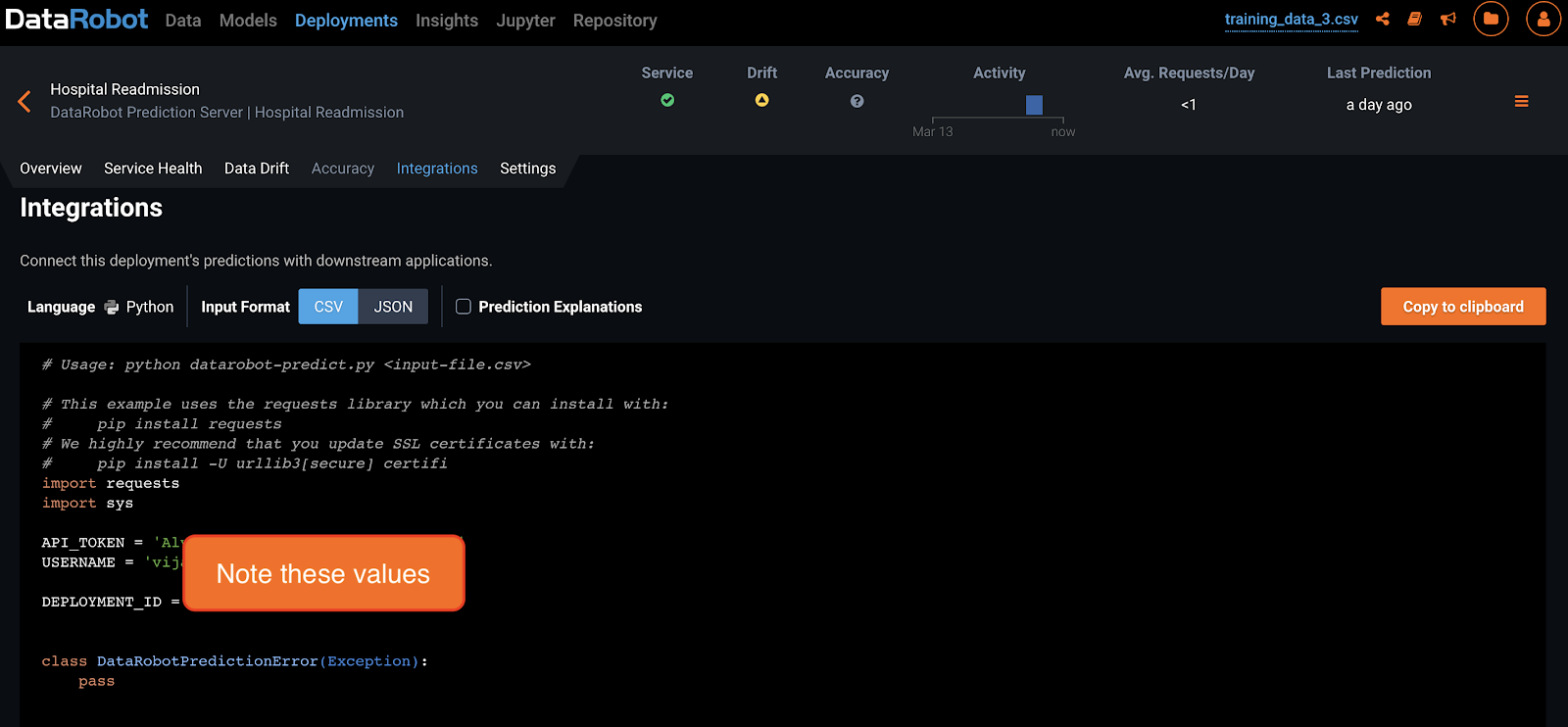
Switch to the “Integrations” tab and make a note of the deployment tokens and keys. You will need them in a later step.
2. Predict and decide
The next step is to build a production workflow that processes incoming data and gets predictions for new patients. We do this using Trifacta.
In Trifacta, create a new flow and import your data. In this case, we’ll load a CSV file containing details of new patients.
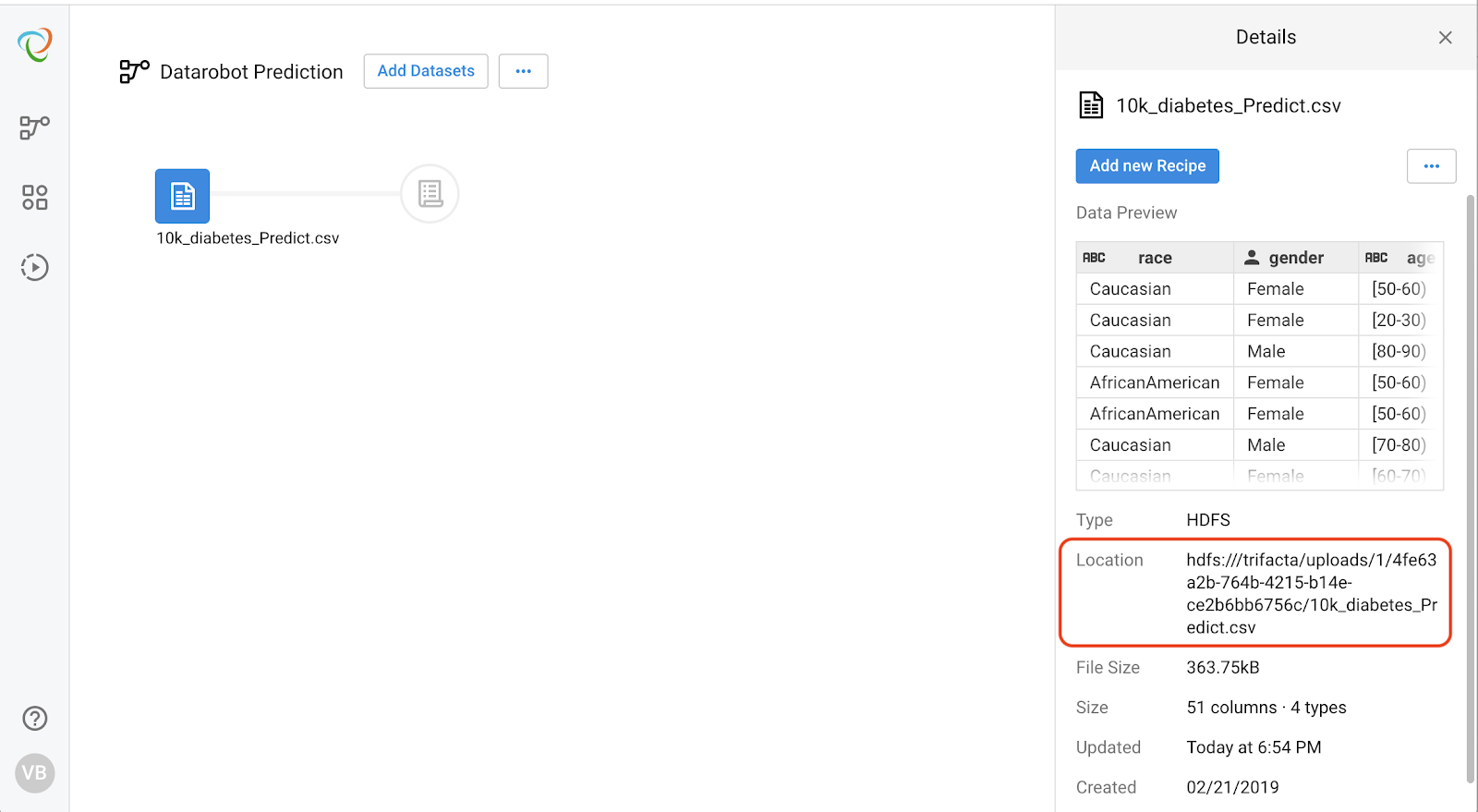
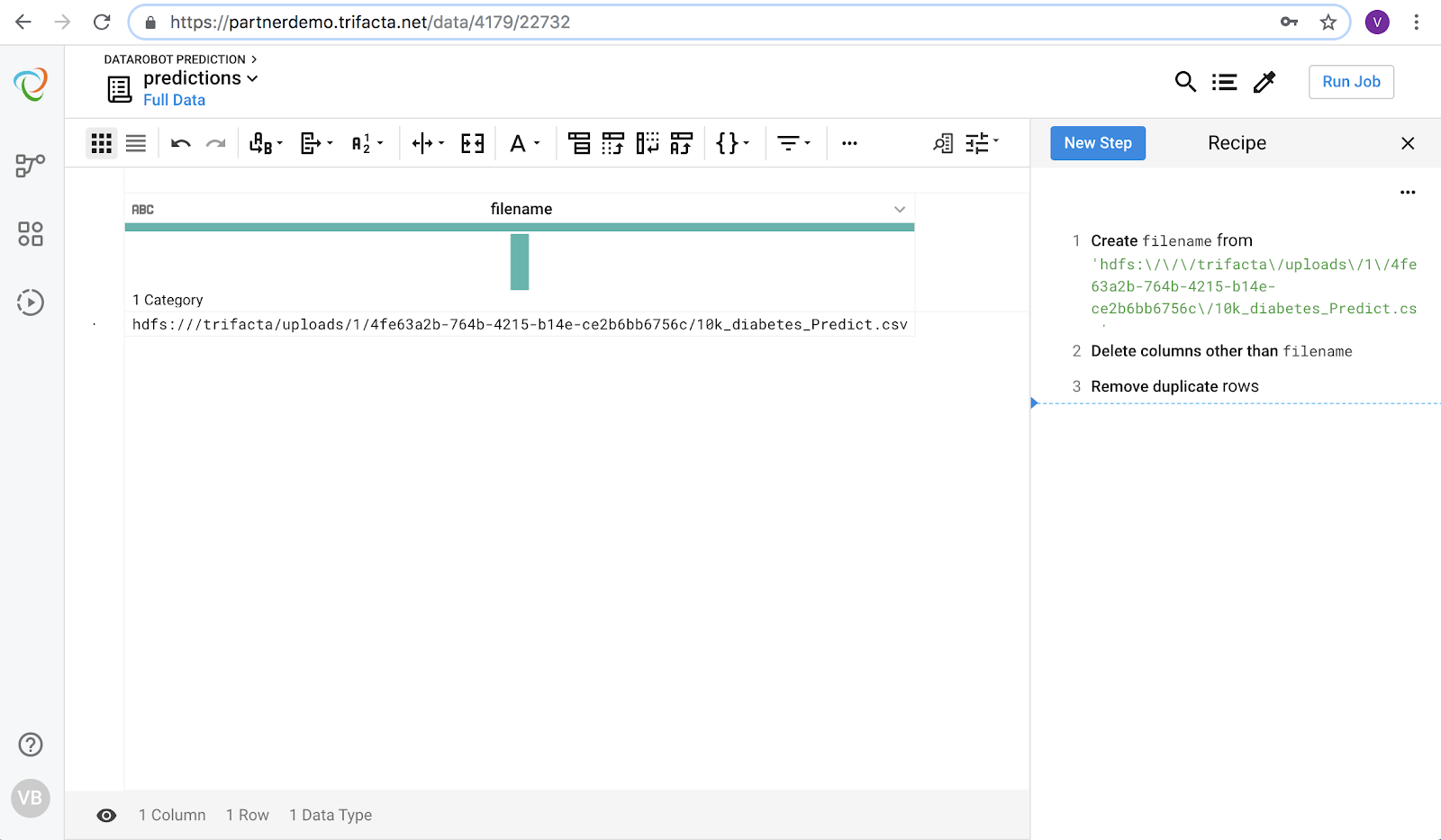
Once imported, you can access the URL path to the file. Copy the URL and insert it into the recipe as shown below.
To call the DataRobot API, you need the following information:
- API Token
- Deployment ID
- DataRobot Key
- Username
Add a recipe step for UDF (invoke external function) and choose “DatarobotPredict”. Choose the filename column and enter an argument in the form API_TOKEN=api_token,DEPLOYMENT_ID=deployment_id,DATAROBOT_KEY=datarobot_key,USERNAME=username
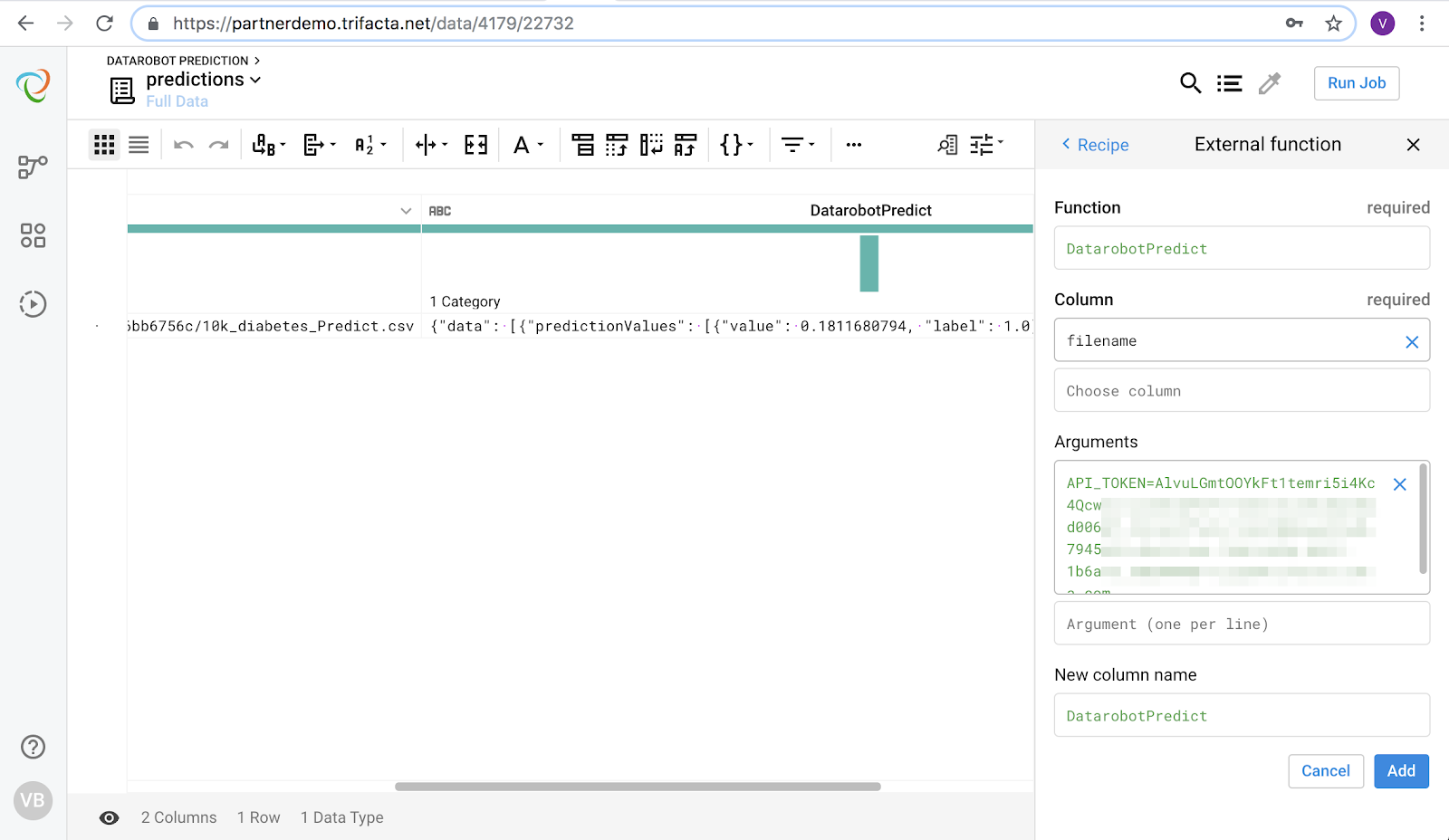
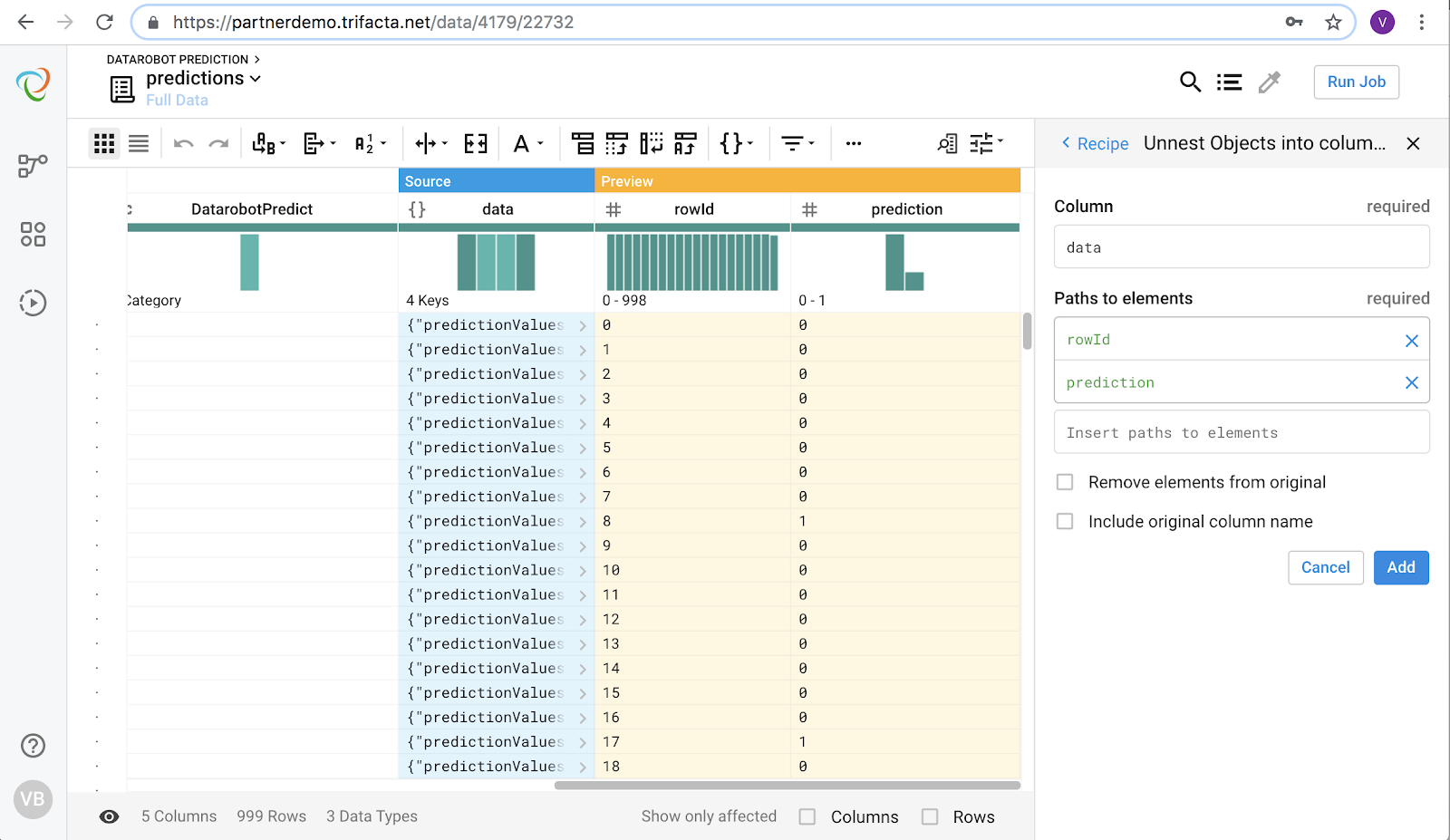
The results of the DataRobot API call are returned in JSON format. Now use Trifacta to parse out key pieces of information into their own fields. Use the flatten transformation to create individual rows in the output. Choose the prediction column along with a row identifier.
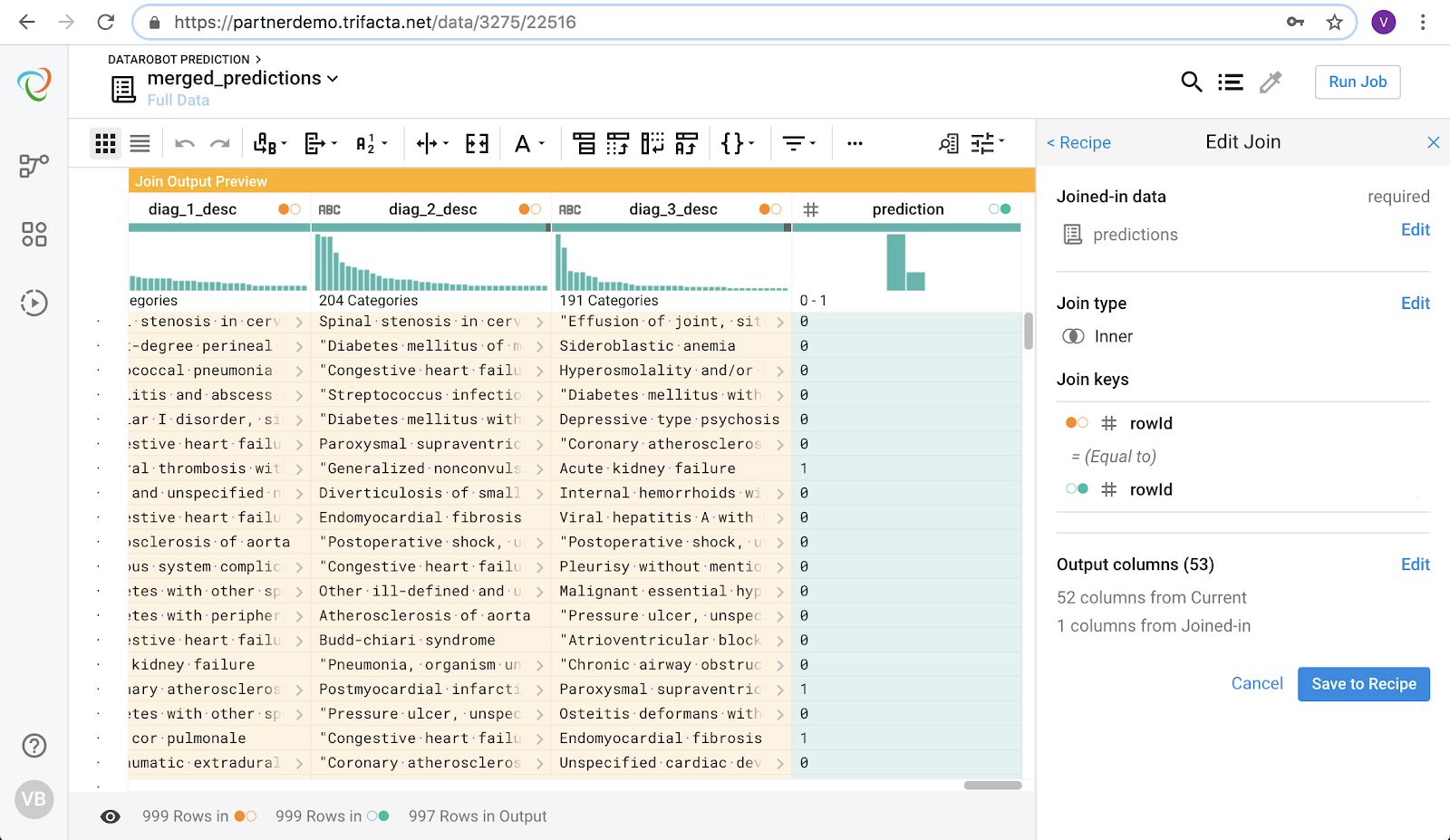
Now merge the prediction results with the original data to produce a combined output. This is accomplished by doing an inner join on rowId. If needed, you can perform additional transformations on this data to support analytics.
You can now use the output of this process to drive decision making. In this case, patients with a higher readmission risk may be assigned to a nurse for additional checkups and preventive measures. All decisions and actions should be carefully recorded for later analysis.
After building the flow, you operationalize it using Trifacta. You do this by setting up a recurring schedule to process new patients on a daily basis. This pipeline feeds data back into the hospital’s systems for the next step.
3. Measure
It is critical to measure the accuracy of the predictions, as well as the effectiveness of the decisions taken based on those predictions.
The first part of this measurement can be implemented in DataRobot, which can detect drift in model predictions. The second part is accomplished by further analyzing patient data from the hospital’s systems and analyzing trends in cost and health outcomes. This step is important to determine the ROI of the machine learning initiative in terms of cost savings as well as well-being of patients.
4. Iterate
The process doesn’t end here. To derive continued benefits from your machine learning initiative, you must iterate on your models to address model drift, as well as to incorporate new insights and additional data gained during the journey. Having a tight feedback loop will ensure that the machine learning initiative continues to provide ROI for a long time.
Additional Resources
- If you are interested in trying DataRobot with Trifacta, you can request a free trial here.
- The Trifacta recipes and source code used in this post are available on Github. A video recording of the process is available on YouTube.
- For more details on the hospital readmission risk model and its implementation in DataRobot, see this page.
Vijay has over 15 years of experience helping large organizations manage their data sets and produce insights.
-
How to Choose the Right LMM for Your Use Case
April 18, 2024· 7 min read -
Belong @ DataRobot: Celebrating 2024 Women’s History Month with DataRobot AI Legends
March 28, 2024· 6 min read -
Choosing the Right Vector Embedding Model for Your Generative AI Use Case
March 7, 2024· 8 min read
Latest posts
Related Posts
