

How to Understand a DataRobot Model: Comparing Models for Accuracy [Part 2]
When you hire a new employee you don’t just interview one job applicant. You invite several of the job applicants for interviews and you seek to find the highest performer, the one with the best credentials, the one with a solid track record of job performance. Well, it’s the same when you want to put an artificial intelligence (AI) into production. You shouldn’t just build a single algorithm. Instead, you should train multiple algorithms, and find the one that performs best on your data. This blog will tell you how to find that top-performing algorithm.
In the first blog in this series, we introduced the cheat sheet for how to understand a DataRobot model.
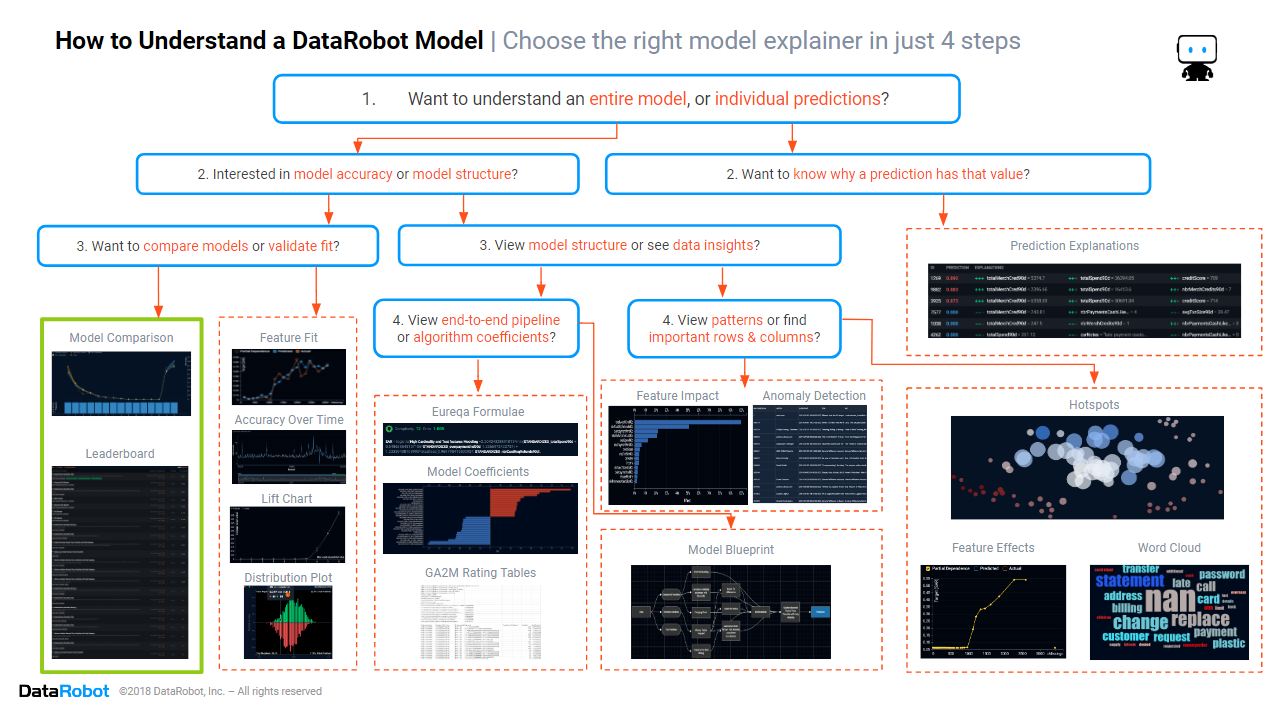
In this blog, we will focus on the section of the cheat sheet marked in green above.
Historically, if you wanted a new AI, the first step would be to build a machine learning algorithm (machine learning algorithms power most AIs). So a data scientist would choose a single machine learning algorithm and train it for you. Why only one algorithm? Well, that’s because of the time and effort it took to manually build, train and deploy these algorithms. And since you only had a single algorithm to choose from, you weren’t guaranteed to get the best. But the days of manually building AIs is ending. Automated machine learning makes it possible to quickly and efficiently build and train dozens or even hundreds of algorithms for you to choose from.
DataRobot Leaderboard
In the same way that competition is good for people, it is also good for AI and machine learning algorithms. According to the no free lunch theorem, no algorithm is always going to be the best. You may have your favorites, but step aside and let competition find the most accurate. DataRobot’s leaderboard does just that. The most accurate models are listed at the top, the least accurate at the bottom.
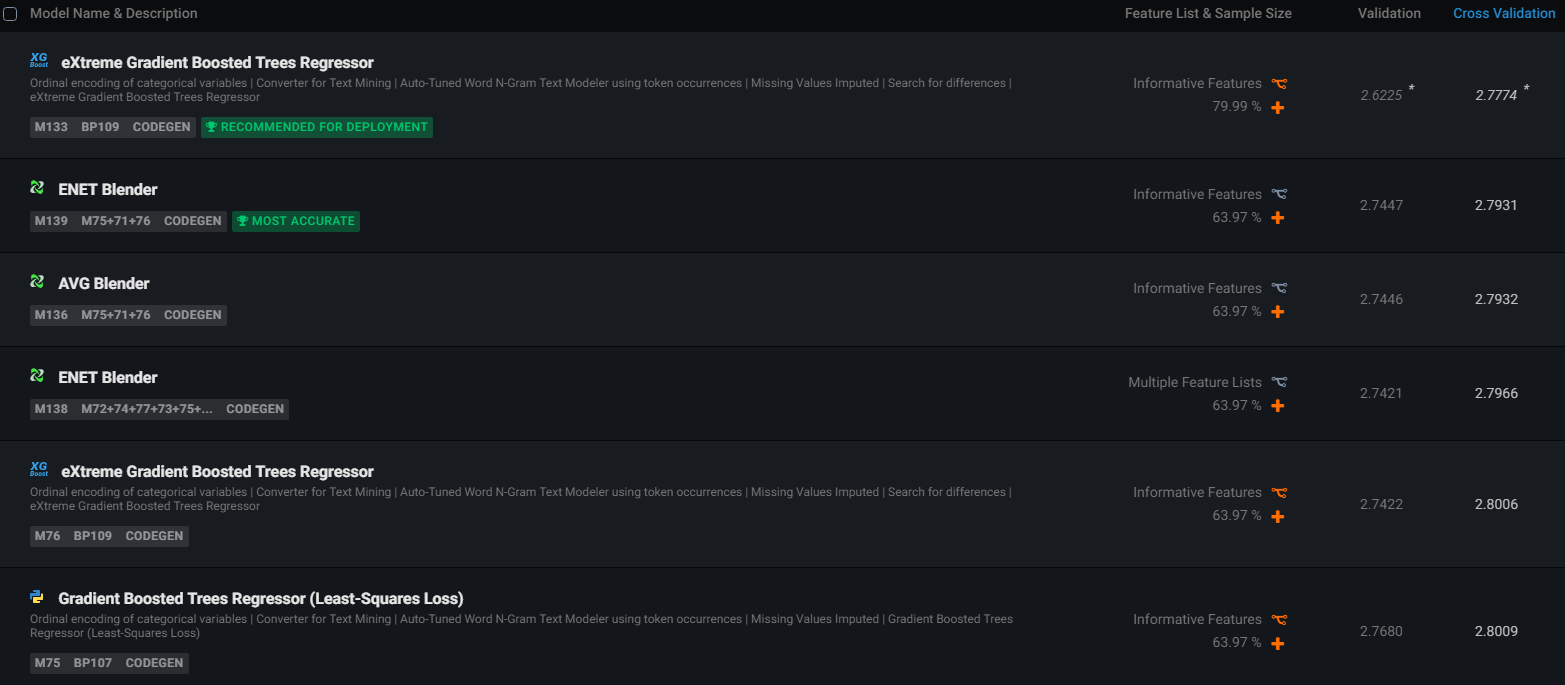
Above is a screenshot of the top six models from a leaderboard. The full leaderboard for this project contained 90 models, but the actual count of leaderboard models will vary from project to project. On the left of the leaderboard, each trained model is listed, along with its description. You can click on the model to expand it and learn more details. To the right are details about which features or input variables the model used, how much data it was trained on, and its accuracy scores. All models have a validation accuracy
To make it even easier for you to choose a model, DataRobot automatically flags which model is most accurate, and which model is best suited for going into deployment. But you may have more considerations than just accuracy. So you can choose to deploy any model from the leaderboard. You can even choose more than one! As each new blog is published in this series, you will learn how to understand more characteristics of a model, that better inform your choice of which is best for your specific needs.
How to Interpret the Leaderboard Above:
-
DataRobot has flagged the ENET Blender as the most accurate model on your data. The ENET Blender was trained on 64% of the rows and used the default list of input features (Informative Features).
-
DataRobot has flagged the eXtreme Gradient Boosted Trees Regressor as recommended for deployment, because it has accuracy almost equal to the most accurate model, but runs faster. This model was retrained on 80% of the rows, to give it an extra boost of accuracy, and it used the default list of default list of input features (Informative Features).
Model Comparison
If you’re more of a visual person than a numbers person, then model comparison plots are for you. These plots compare any two models of your choosing from the leaderboard, and visually compare their accuracy.
Model Comparison – Lift Charts
The first comparison we can make between any two models is by plotting the lift charts for each. Lift charts communicate accuracy by displaying how well a model can separate high values (e.g. finding those customers most likely to purchase your product) from low values (e.g. finding those customers not suited to a product offering). Here the blue line represents one model, and the yellow line represents a different model, both selected by the user.
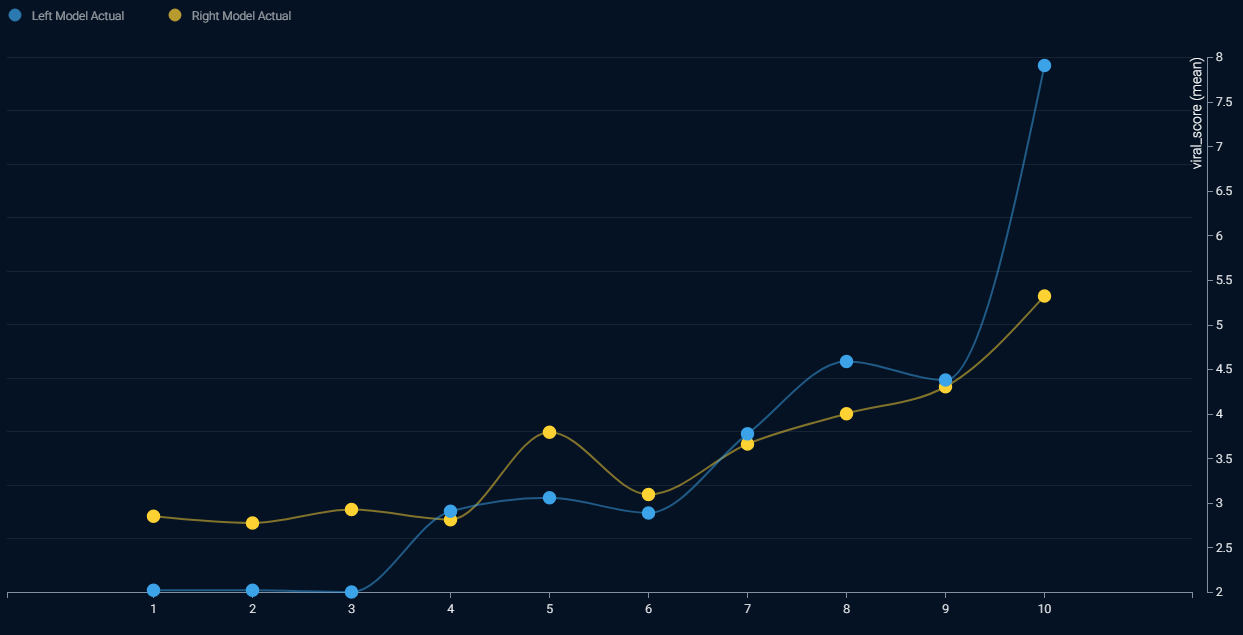
DataRobot makes predictions for each row, and then ranks each row from the lowest prediction to the highest prediction. Finally it plots average results from the rows with the lowest predictions (on the left), up to the rows with the highest predictions (on the right). The more accurate model is the one where the line has the steepest slope, and the widest vertical range, because that means the model is correctly separating high values from low values in its predictions.
How to Interpret the Lift Chart Above:
-
The blue line has a steeper slope than the yellow line.
-
The blue line is particularly lower for the first 30% and higher for the last 10% of rows ranked by predictions.
-
The model represented by the blue line is more accurate than the model represented by the yellow line.
Model Comparison – Dual Lift Charts
Sometimes, instead of comparing the overall accuracy of two models across all of the data, we want to understand how the predictions are different, and when the models have different predictions, which model is more accurate. Dual lift charts communicate accuracy by showing us how different the model predictions are, and which model is more correct when the predictions diverge. This can be important for certain types of modeling use cases where I want to know how much different models can diverge, in order to assess the risk of winner’s curse.
Once again the blue line represents one model, and the yellow line represents a different model, both selected by the user. This time there is an extra line, an orange line that represents the actual values for the target variable.
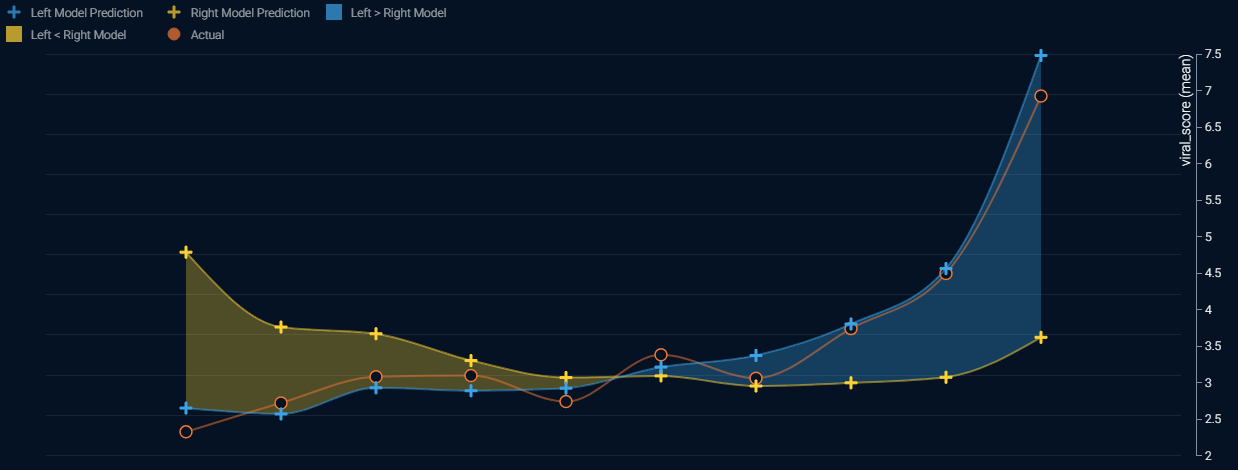
To do this we collect pairs of predictions, from the two chosen models, ranking the data rows by how much the first model’s prediction exceeds the second model. Then, we plot the predictions and actual results. On the left side of the plot are the rows where the yellow model has predictions that most exceed those of the blue model. On the right side of the plot are the rows where the blue model has predictions that most exceed those of the yellow model. The more accurate model is the one whose line is closest to the orange line.
How to Interpret the Dual-Lift Chart Above:
-
The two lines vary by up to 4.0 (the raw data values range from 1 to 10), indicating that the two models can have significantly divergent predictions.
-
Whenever the models have divergent predictions, the model represented by the blue line is typically closer to the actual results. In fact the more the two models diverge, the more accurate is the model represented by the blue line. This means that the model represented by the blue line is more accurate than the model represented by the yellow line.
-
Advanced: You may be able to get even more accuracy by combining these two models. Using a weighted average of the two models, mostly weighted towards the blue model, may give marginally higher accuracy because when the two lines diverge, the true result lies partway between the two lines but usually closer to the blue line.
Conclusion
The path to finding the best AI includes finding the one that is most accurate. You hold a competition between the algorithms to find the best, and let the results sort the most accurate from the least accurate. And the only practical way you can build and train so many is to use automated machine learning. DataRobot invented automated machine learning and provides the widest range of insights and diagnostics to help you to understand and trust the models you build. If your AI can’t build dozens of models and show you which is the most accurate, then it’s time to upgrade to DataRobot for models that you can trust. Click here to arrange for a demonstration of DataRobot’s human-friendly model interpretability.

About the Author:
Colin Priest is the Sr. Director of Product Marketing for DataRobot, where he advises businesses on how to build business cases and successfully manage data science projects. Colin has held a number of CEO and general management roles, where he has championed data science initiatives in financial services, healthcare, security, oil and gas, government and marketing. Colin is a firm believer in data-based decision making and applying automation to improve customer experience. He is passionate about the science of healthcare and does pro-bono work to support cancer research.

Colin Priest is the VP of AI Strategy for DataRobot, where he advises businesses on how to build business cases and successfully manage data science projects. Colin has held a number of CEO and general management roles, where he has championed data science initiatives in financial services, healthcare, security, oil and gas, government and marketing. Colin is a firm believer in data-based decision making and applying automation to improve customer experience. He is passionate about the science of healthcare and does pro-bono work to support cancer research.
-
How to Choose the Right LLM for Your Use Case
April 18, 2024· 7 min read -
Belong @ DataRobot: Celebrating 2024 Women’s History Month with DataRobot AI Legends
March 28, 2024· 6 min read -
Choosing the Right Vector Embedding Model for Your Generative AI Use Case
March 7, 2024· 8 min read
Latest posts
