

Interpretability and Accuracy, or How to Have your Cake and Eat it Too
I love chocolate cake, chocolate mud cake to be precise. But I have a dilemma because I can’t enjoy chocolate cake and keep my doctor happy. I must choose one or the other. Until recently, it has been the same with machine learning. If you work in a regulated industry such as banking, you couldn’t use the most accurate machine learning models and keep the regulator happy. You had to choose one or the other, accuracy or regulatory compliance. Actually, it isn’t even a choice: You must keep the regulator happy by using models that are interpretable.

When the global financial crisis unfolded a decade ago, banks discovered that their black box algorithms were based on flawed assumptions. So financial system regulators decided that additional controls were needed and introduced regulatory requirements for “model risk” management on banks and insurers. For example, in April 2011 the Board of Governors of the Federal Reserve System in USA published Supervisory Guidance on Model Risk Management (SR 11-7), saying “Model risk increases with greater model complexity, higher uncertainty about inputs and assumptions, broader extent of use, and larger potential impact. Banking organizations should manage model risk both from individual models and in the aggregate.” Banks had to prove that they understood the models they were using, including an “evaluation of conceptual soundness” of their models. So banks have deliberately limited the complexity of their models, and embraced the use of generalized linear models because of their simplicity and interpretability.
During the past several years machine learning techniques have made leaps in accuracy. We have seen the adoption of support vector machines, random forests, boosted trees, deep learning, and ensembling. But banks have been slow to adopt these techniques due to the lack of interpretability of these new algorithms. I know of one banking regulator that requires banks to send it the formula for each and every algorithm the banks use. For an ensemble model the algorithm formula could be hundreds or thousands of pages long!
Recently there has been a new development. In their paper “Accurate Intelligible Models with Pairwise Interactions,” Caruana et al. describe high-performance generalized additive models with pairwise interactions (GA2M) that “have almost the same performance as the best full-complexity models on a number of real datasets” and “that for many problems, GA2M-models can yield models that are both intelligible and accurate.” They achieved this by developing “a novel, computationally efficient method called FAST for ranking all possible pairs of features as candidates for inclusion into the model”. FAST quickly finds the feature interactions that are of most value.
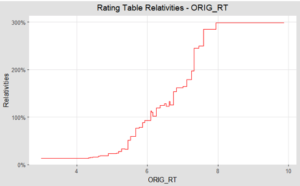
When I applied GA2Ms to Fannie Mae mortgage loan data, it fitted step functions across each numeric input, and the model formula could be viewed as a simple lookup table and plots, such as shown above.
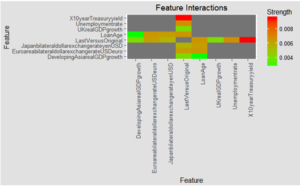
The FAST algorithm also found and ranked possible feature interactions for me, as shown above. Each of these interaction effects can also be viewed as a simple lookup table. As you can see, the strongest feature interaction was between the proportion of loan paid off, and the 10 year treasury yield. In fact, both the proportion of the loan that has been paid off and the age of the loan each have several interaction effects with other features. This made sense to me – the impact of economic factors is expected to be lower on older loans, where much of the principle has already been paid off.
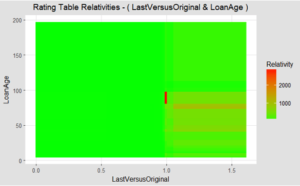
The interaction effects in interpretable models can create actionable insights. As seen above, there is a striking hot spot for loan default risk management when a Fannie Mae mortgage is 7 to 8 years old, yet the outstanding balance has not reduced versus the original balance.
With the recent release of version 3.1 of DataRobot, GA2M models have been made available to DataRobot users. Now banks and other regulated entities have access to “intelligible models with state-of-the-art accuracy.”


Colin Priest is the VP of AI Strategy for DataRobot, where he advises businesses on how to build business cases and successfully manage data science projects. Colin has held a number of CEO and general management roles, where he has championed data science initiatives in financial services, healthcare, security, oil and gas, government and marketing. Colin is a firm believer in data-based decision making and applying automation to improve customer experience. He is passionate about the science of healthcare and does pro-bono work to support cancer research.
-
How to Choose the Right LLM for Your Use Case
April 18, 2024· 7 min read -
Belong @ DataRobot: Celebrating 2024 Women’s History Month with DataRobot AI Legends
March 28, 2024· 6 min read -
Choosing the Right Vector Embedding Model for Your Generative AI Use Case
March 7, 2024· 8 min read
Latest posts
