特徴量ごとの作用を使ってモデルの中身を解釈する
DataRobotのデータサイエンティスト山本です。
今回はDataRobotの強力な機能の一つである特徴量ごとの作用についてご紹介したいと思います。DataRobotはモデルを解釈するための様々な機能を有していますが、特徴量ごとの作用を使うことでその名の通り、各特徴量がターゲットに対してどのような影響を及ぼしているか、そのモデルの予測値と実測値の関係がどうなっているのか、その中身を見通すことができます。
特徴量ごとの作用とは
特徴量のインパクトを見ることで、そのモデルにどの特徴量がよく効いているのかを知ることができます。しかし、どのように効いているのかを知ることはできません。そこでモデル特徴量ごとの作用の出番です。モデル特徴量ごとの作用を見ることで、その変数がプラスに効いているのかマイナスに効いているのか、どのように効いているのか依存性を定量的に理解することができます。さらにはどの領域でモデルの信頼性が高くて、どの領域では注意が必要なのかについてのインサイトを得ることも可能です。
まずはモデル特徴量ごとの作用を見てみましょう
モデル特徴量ごとの作用を見てみます。今回の題材はローンの申請データからの貸し倒れ予測で、年収入について見てみることにします。オレンジ色、青色、黄色の3つの折れ線グラフとその下にヒストグラムが表示されているのがわかります。このヒストグラムは年収入の分布を表すもので、データの画面で見ることができるものと同じものです。オレンジ色の折れ線はターゲットのそのビンにおける平均値の実測値を、青色の折れ線グラフは予想値を表しています。黄色の折れ線グラフは部分依存を表しますが、これについては後で説明することにします。
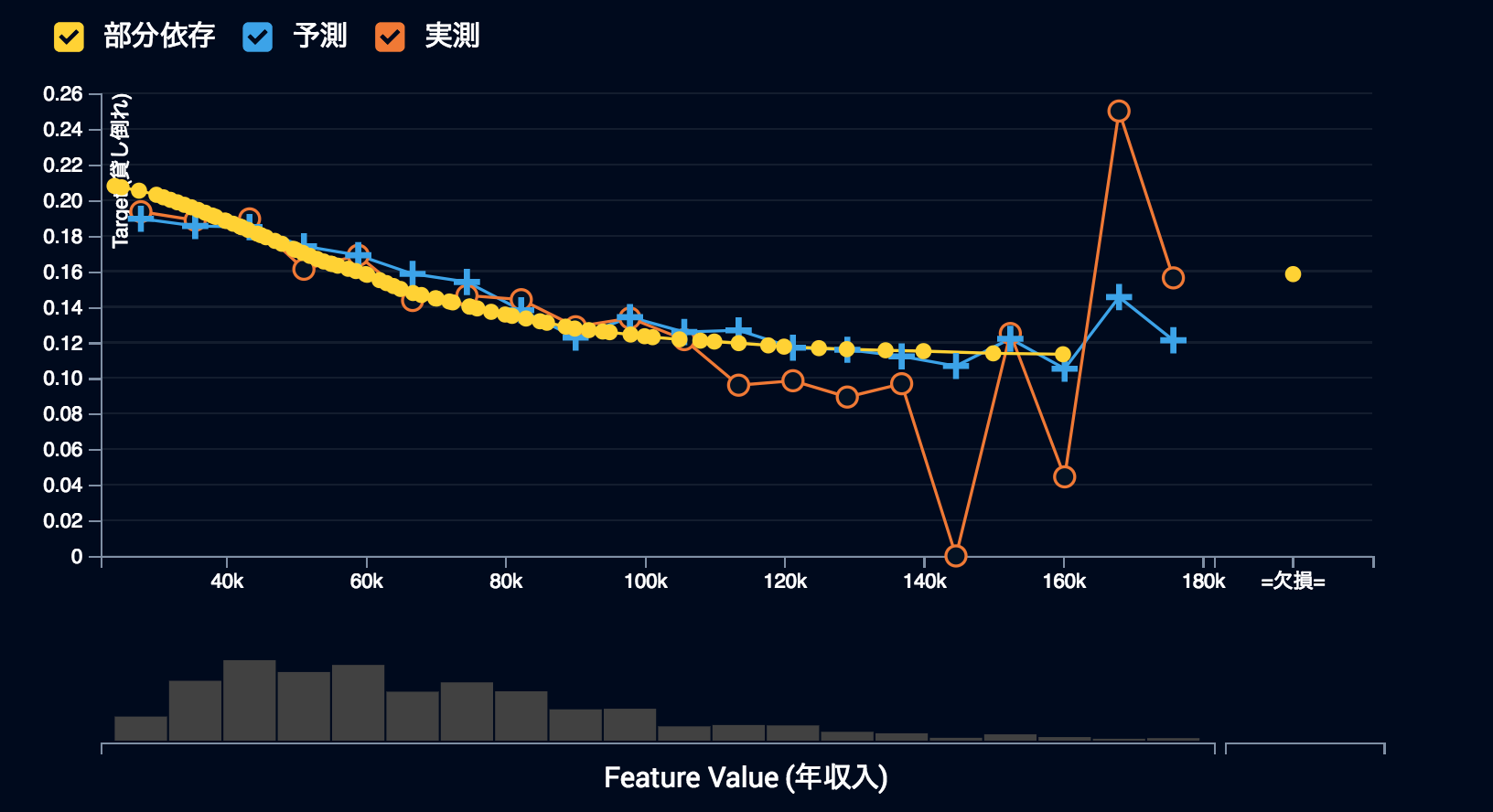
この折れ線グラフから例えば、「年収入が高い人ほど貸し倒れが少ない傾向がありそうだ」とか「年収入100k USDくらいまでは青色の予測とオレンジ色の実測の折れ線がほぼ一致しているので、この辺りまではモデルを信頼できそうだ」などのインサイトを得ることができます。さらには、「年収入100k USD以上では傾向が違うようだ。貸し倒れる要因が異なるのかもしれない。分けて別々のモデルを作ってみようか」などの考察も可能かもしれません。
部分依存はどのように計算されているのか?
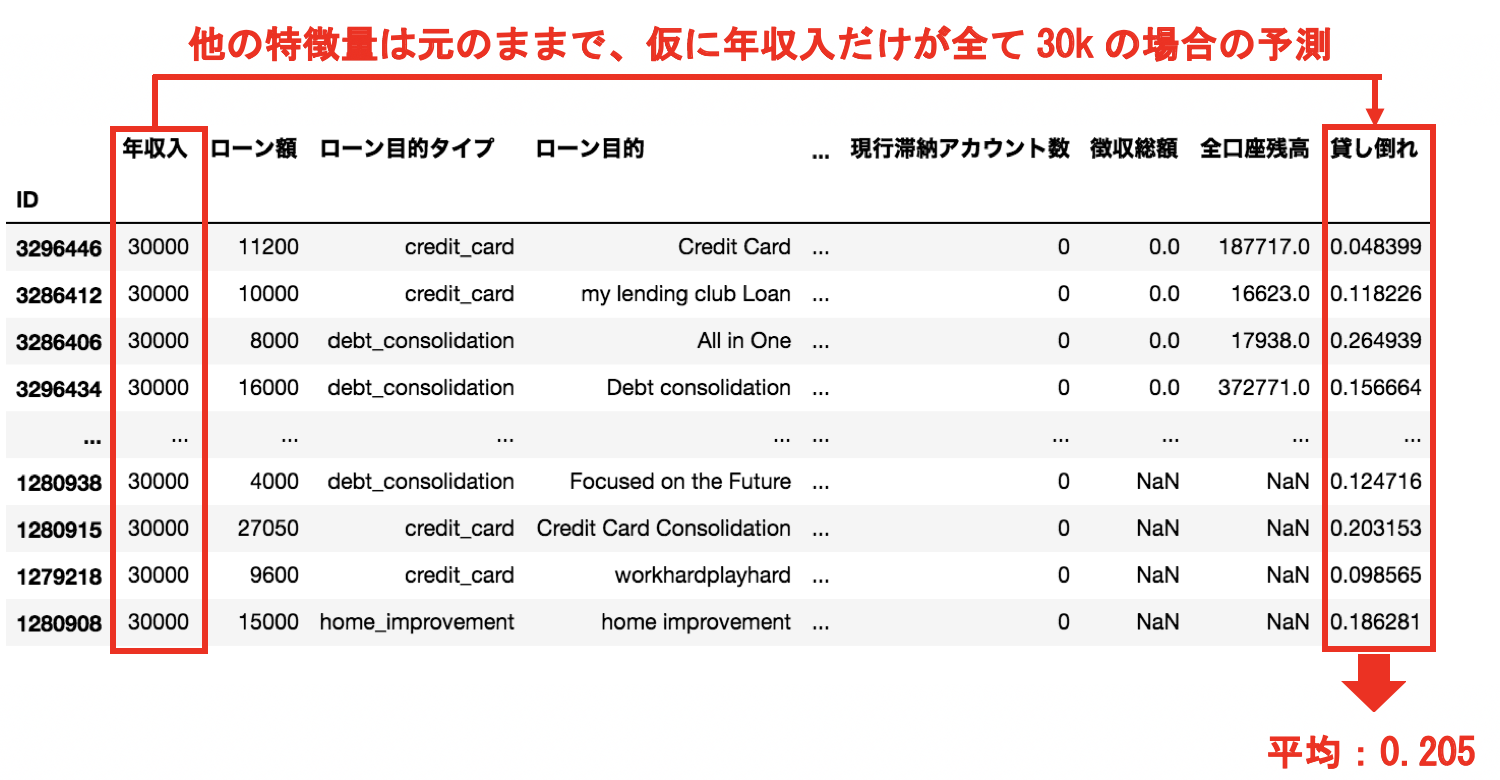
特徴量ごとの作用の部分依存(Partial Dependence)とは何なのかについては、お客様から最も頻繁にご質問を頂くポイントの一つです。実際、部分依存とは何なのかについては直感的にはわかりづらいため、ここでは実際にローン申請のデータを用いて、その導出過程を追いかけながら中身を一緒に理解していければと思います。それでは、以下のデータの年収入について部分依存を求めていきましょう。

まずは、他の特徴量はそのままで、年収入だけが全員30,000ドルだったと仮定して、対象のモデルを用いて貸し倒れ確率を求めます。そして得られた確率の平均をとります。
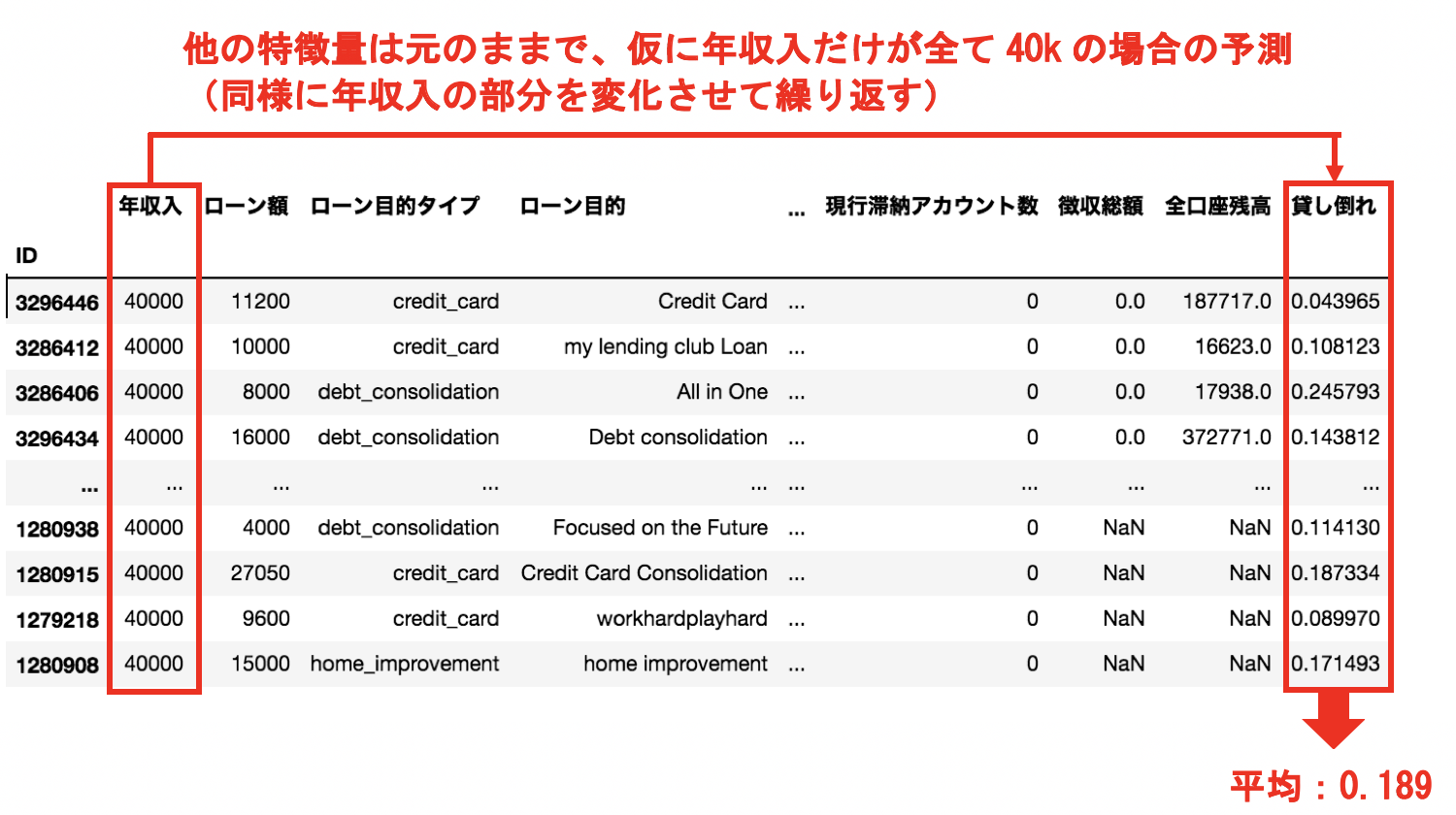
同様に年収入を40000ドル、50000ドルと変化させていって貸し倒れの予測を行い、それぞれの場合における貸し倒れ確率の平均値を求めていきます。
最後に得られた貸し倒れ確率の各平均値を年収入に対してプロットすることで、目的の年収入の部分依存が得られます。
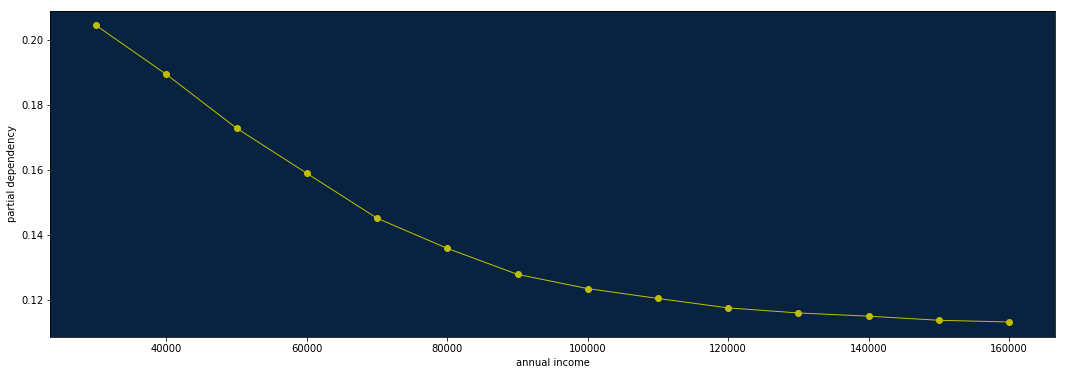
このように手動で計算すると手間と時間のかかる部分依存の計算ですが、DataRobotでは、特徴量ごとの作用のボタンを押すとすべての入力特徴量に対して部分依存を自動的に計算してくれます。
部分依存って何の役に立つの?
部分依存は、貸し倒れ確率が年収入の部分にどのように依存するかを他の特徴量の影響を平均化することで取り除いくれたものと言えます。そのため、その特徴量が単独でどのように予測結果に影響しているかをこのグラフから知ることができます。また、部分依存はこの特徴量を単独で変更した場合の効果と解釈することができ、例えば材料の開発における添加剤の効果やマーケティングにおけるターゲット層別の違いなどについて、単独の効果を把握して次のアクションに繋げることができるという点で実務において大変有用です。
実際に導出してみるとよくわかるのですが、部分依存の計算はモデルの部分はモデルの種類に依ることなく同様に行うことができることが出来る点で優れています。モデルの中身を詳しく知ることができる特徴量ごとの作用について、部分依存も含めてこれまで以上にDataRobotをご活用頂ければと思います。

DataRobot データサイエンティスト。Kaggle Master、博士 (工学)。東京大学大学院工学系研究科にて有機無機複合材料の研究で博士号を取得。学位取得後、大手化学メーカーにて液晶・タッチパネル関連先端化学材料の研究開発に従事。その後、大手食品メーカーで機械学習を用いた食品パッケージに関する予測モデリングと最適化に取り組むなど、BtB と BtC いずれにも深い経験を有する。余暇では機械学習コンペティションの Kaggle に精力的に取り組んでおり、 2020年現在も現役で活躍している。
直近の注目記事
もう失敗しない!製造業向け機械学習Tips(4):
偽相関の罠に陥らない、製造業における機械学習を用いた要因分析のコツ(MONOist)
もう失敗しない!製造業向け機械学習Tips(3):教師データが足りないと「異常予測」は難しい、ならば「異常検知」から始めよう (1/2)(MONOist)
もう失敗しない!製造業向け機械学習Tips(2):機械学習による逆問題への対処法、材料配合や工程条件を最適化せよ(MONOist)
もう失敗しない!製造業向け機械学習Tips(1):機械学習で入ってはいけないデータが混入する「リーケージ」とその対策 (1/2)(MONOist)
-
生成AIの取り組みが失敗する6つの理由とその解決策
2024/04/30· 推定読書時間 4 分 -
分類プロジェクトの評価でAUCよりも便利なFVE Binominal|DataRobot機械学習モデル評価指標解説
2024/04/05· 推定読書時間 4 分 -
RAG(Retrieval-Augumented Generation)構築と応用|生成AI×DataRobot活用術
2024/04/03· 推定読書時間 4 分
最近のブログ記事