製薬企業での機械学習の利用 Part 1
DataRobotのデータサイエンスアソシエイトの菅原です。製薬業界はAI・機械学習を事業成長のため積極的に取り入れている業界の一つです。本稿では、製薬企業での機械学習活用についてご紹介します。
製薬企業を取り巻く環境
日本は少子高齢化が進んでおり、国民全体の医療費負担が急増しています。それを受けて、国の政策は医療費抑制の方向へと舵が切られています。
実際、2018年度薬価改定により新薬創出加算の見直しや四半期再算定など、抜本的な改革と言える変化が業界にもたらされました。これらの変化は国内製薬企業にとって業務改革・構造改革に取り組む重要な転換点となりました。
今年4月には費用対効果評価制度が本格実施され、2020年には次の薬価改定、そして翌2021年からは薬価改定の毎年実施への移行が決定しています。
これらの制度改定後、多くの製薬企業では国内市場での売上の減速と利益の下押しが実際に発生しており、またこの厳しい状況が続くと予想されています。そのため製薬企業各社は必然的に全社的な構造改革、業務改革に取り組んでいます。
DataRobotユーザーの国内製薬企業では実際に業務改革のドライバーとして戦略的に機械学習モデルが使われ、成果が生まれてきています。製薬企業における主な業務プロセスは ①創薬 ②製薬 ③営業 ④育薬に分けられますが、各プロセス毎に機械学習ユースケースをご紹介します。
(本稿では創薬/製薬プロセスをカバーします。営業/育薬プロセスについては、11/5に公開するブログをご覧ください)
創薬プロセスの概要
新たな市場を切り開くには新しい疾患をターゲットにした新薬が必要です。しかし、既に幅広い疾患で特に低分子医薬品は開発され尽くされ、新薬開発のターゲットとなる疾患は難易度が高いという現実があります。(20年前は1万分の1の候補化合物が臨床試験を通過していましたが、今は約3万分の1と言われています)
創薬プロセス全体の時間とコストも非常に大きく、約15年の期間と1000億円を掛けてようやく一つの新薬が患者さんに届けられています。
創薬プロセスでは、大きくは以下のように3段階の評価・試験が行われます。新しい化合物を作成して行う実験は非常に高コストなため、実試験を行う前に機械学習を活用して候補化合物やデザイン方向性のスクリーニングを行うことができれば開発期間の短縮や開発経費の削減に貢献できると期待されています。
①基礎研究段階の評価
②前臨床試験
③臨床試験
これら全ての評価・試験で有効性と安全性、品質が十分確認されれば、ようやく厚生労働省に申請をします。新薬として有用で適切と判断されれば、薬としての製造承認を得ることができ、一般の患者さんが使える薬として販売されます。
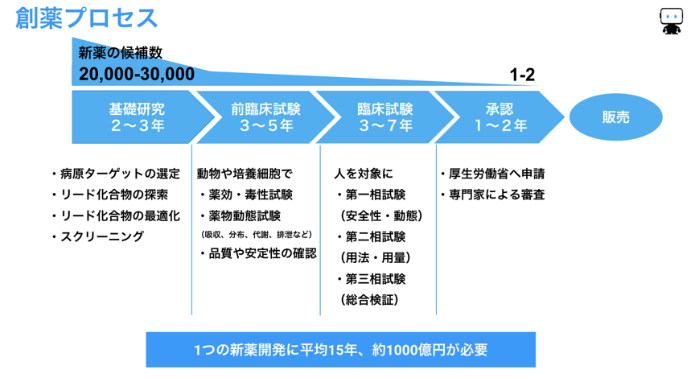
創薬プロセスにおける機械学習の活用
①基礎研究段階の評価
病気のメカニズムやゲノム情報の解析結果などから、薬の標的となるタンパク質を決めます。そして、そのタンパク質の原子構造を調べ、薬になりそうな化合物(リード化合物)をデザインします。機械学習による予測モデルを使って、あるリード化合物が薬理活性を見込めるか、もしくはどういった化合物が標的への活性を示すかのスクリーニング評価を行うことができます。
②前臨床試験
実際に化合物を合成し、期待した効き目があるか、毒性はないかなどの薬理作用を調べます。また、投与した薬がどのくらいの濃度で血中に現れるか、体の中でどう化学変化して排泄されていくかなどの薬物動態も調べられます。このように薬物が体内に取り込まれてから体外に排泄されるまでの”ADMET”と呼ばれる様々な薬物動態特性や毒性の予測に機械学習が活用されています。
③臨床試験
人間を対象に試験を行います。健康な人や患者さんを対象に同意の下で行われる、いわゆる“治験”です。GCPと呼ばれる厳しい規準に基づいて、第一相から第三相までの試験が行われますが、このフェーズでも今までの治験結果データに機械学習を適用して作成した予測モデルを活用して、新薬候補であるリード化合物に優先順位を付けることが可能です。
創薬プロセスで扱うデータ
創薬プロセスで機械学習を行う時のポイントは、化合物構造をどのように機械学習で扱えるデータに落とし込むかです。化合物の薬理活性や薬物動態はその構造と密接な関わりがありますが、化合物構造を記述するために様々な方法が提案されています。例えば著名なオープンソースライブラリのRDKitでは、desclistに196 に及ぶ記述子が保存されています。
よく使われているのはその化合物に含まれる原子や結合、部分構造の有無を1また0とおいた特徴ベクトルとして表現する「フィンガープリント」です。この定義の仕方は一意ではなく、原子の記述に周囲の原子の影響の重みを含めて取り扱う方法や原子配置の3次元構造情報を取り入れる方法など、様々な方法が考案されています。実際にRDKitには、RDKit/MACCS/Morgan/Avalonなど様々なフィンガープリントが実装されています[1]。
下図はフィンガープリントのイメージです[2]。 各記述子のルールに基づき、特定の分子構造がある場合は1、無い場合は0として、ベクトルとして表現しています。
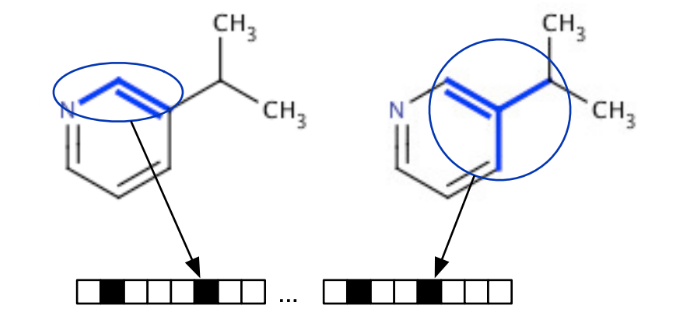
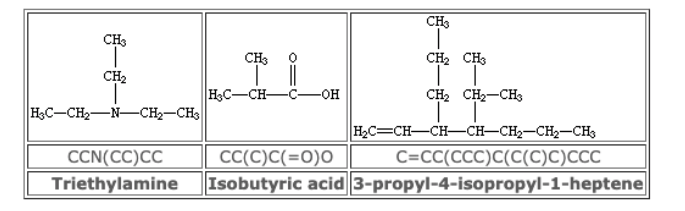
また、全く別の観点による分子の記述法に、文字列による表現があります。広く用いられているのはSMILESと呼ばれる記述子です。原子間の結合の種類および結合のつながり方を表現したものであり、比較的単純なルールで決定できます。代表的なルールを紹介します[3]。
①元素記号を利用する(水素原子は省略)
②構造式上で隣合う原子は隣に書く
③原子間の結合の種類を記号で表す(二重結合は=、三重結合は#など)
④分岐は()で表す
⑤環を形成する原子同士に数字のラベルをつける。
SMILSの表示例 [4] 。(中段がSMILES表記)
このように化合物を記述子として特徴量に入れた上で、さらに化合物の製造パラメータ、実験時のパラメーター、量子化学計算による化学反応の安定性など、様々なパラメータを加えたデータを用いて、機械学習による解析が行われています。
製薬プロセスの概要
医薬品は生命関連製品であるため、医薬品の製造管理および品質管理の基準である”GMP”に則って厳密に管理されています(下図)。製造プロセスでは衛生的で高い品質を保ち続けられる設備と環境が必要です。
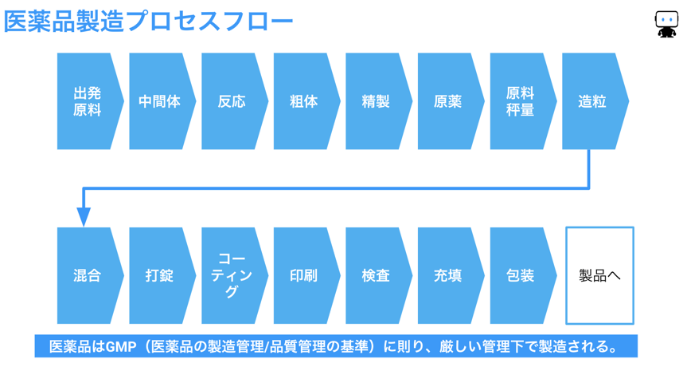
製薬プロセスにおける機械学習の活用
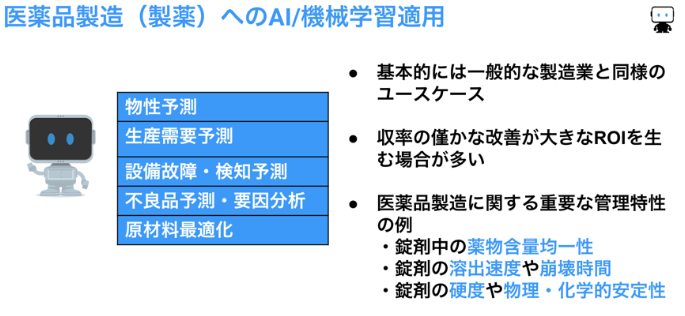
最適化:医薬品を量産する製薬プロセスでは、重要な管理特性である錠剤中の薬物含量均一性、錠剤の溶出速度や崩壊時間などの予測モデルを機械学習で作ることで、製造パラメーターを最適化し、ひいては歩留まりの向上を期待できます。
要因分析:品質のばらつき原因を探る要因分析にも機械学習が使われています。製薬プロセスはすでにGMPの要求を満たす高い管理レベル・品質レベルにありますが、生産量が多い医薬品の製造では小さなばらつきに対する僅かな改善を積み重ねることで大きな効果を期待できます。
また、実際に医薬品を製造する前には生産需要予測に基づいて生産計画が立てられますが、過去の実績データから機械学習による予測モデルを作成して需要予測が行われています。その他、製造業に一般的なテーマ、例えば設備故障検知などにも機械学習モデルが使われています。
以上、製薬プロセスでの機械学習ユースケースをまとめると、下記のようになります
本稿では ①創薬 ②製薬 プロセスでの機械学習活用についてご紹介しました。次回は、③営業 ④育薬 プロセスでの機械学習活用についてご紹介いたします。
[1]参考:rdkit資料
https://www.rdkit.org/docs/GettingStartedInPython.html#list-of-available-fingerprints
[2]図の引用:rdkit資料
https://www.rdkit.org/UGM/2012/Landrum_RDKit_UGM.Fingerprints.Final.pptx.pdf
[3]畑中美穂(2019):”化学におけるマテリアルインフォマティクスの現状と課題”, 「人工知能」, 34, [3], 351-357
[4]表の引用:DAYLIGHT
https://daylight.com/dayhtml/doc/theory/theory.smiles.html
その他参考:
京都大学大学院医学研究科編(2017):「くすりをつくる研究者の仕事」, 化学同人
じほう編(2019):「薬事ハンドブック2019」, じほう

DataRobot データサイエンティスト。主に製薬企業様の AI 活用をサポート。社内での AI プロジェクトの推進や、DataRobot を有効に活用するための Python スクリプトの顧客への提供なども行っている。機械工学をバックグラウンドにしており、携帯電話や自動車部品などの製造業に精通。JDLA のディープラーニング E 資格所持。
-
分類プロジェクトの評価でAUCよりも便利なFVE Binominal|DataRobot機械学習モデル評価指標解説
2024/04/05· 推定読書時間 4 分 -
RAG(Retrieval-Augumented Generation)構築と応用|生成AI×DataRobot活用術
2024/04/03· 推定読書時間 4 分 -
バリュー・ドリブンAI:予測AIから学んだ教訓を生成AIに応用する
2024/03/19· 推定読書時間 2 分
最近のブログ記事