Treasure Data CDP x DataRobot AI = 顧客データから価値を生み出す
はじめに
DataRobotでは先進的な外部ツールとの連携をすることで、ユーザー様がすでに構築された既存ツールの利用価値を更に高める取り組みを行っています。特にデータベース分野で最近注目されているTreasure Dataとの連携は、先日行われたAI Experience 2019 Tokyo でも大きく取り上げさせていただきました。

トレジャーデータ堀内氏と握手を交わすDataRobotプロダクトVPのPhil Gurbacki
企業には様々な顧客データがあり、Treasure Dataの提供するCDP(Customer Data Platform)の仕組みは、その収集と一元管理を容易に可能にしてくれます。一方でそういった顧客データから本当に価値のある顧客インサイトや、サービス向上の打ち手がどれだけ生まれているでしょうか?このブログでは、2つの製品の組み合わせがいかに顧客データの利用価値を広げてくれるのかを見ていきたいと思います。
Treasure Data CDP x DataRobot でどんな事ができるの?
CDPは、主にB2Cにおける、顧客データ(Customer Data)のプライベートDMP(Data Management Platform)として注目され、導入が活発になっているソリューションです。
近年、販売チャネルの多様化、顧客接点の多様化に伴い、顧客に関する大量のデータが様々な場所で発生するようになってきました。
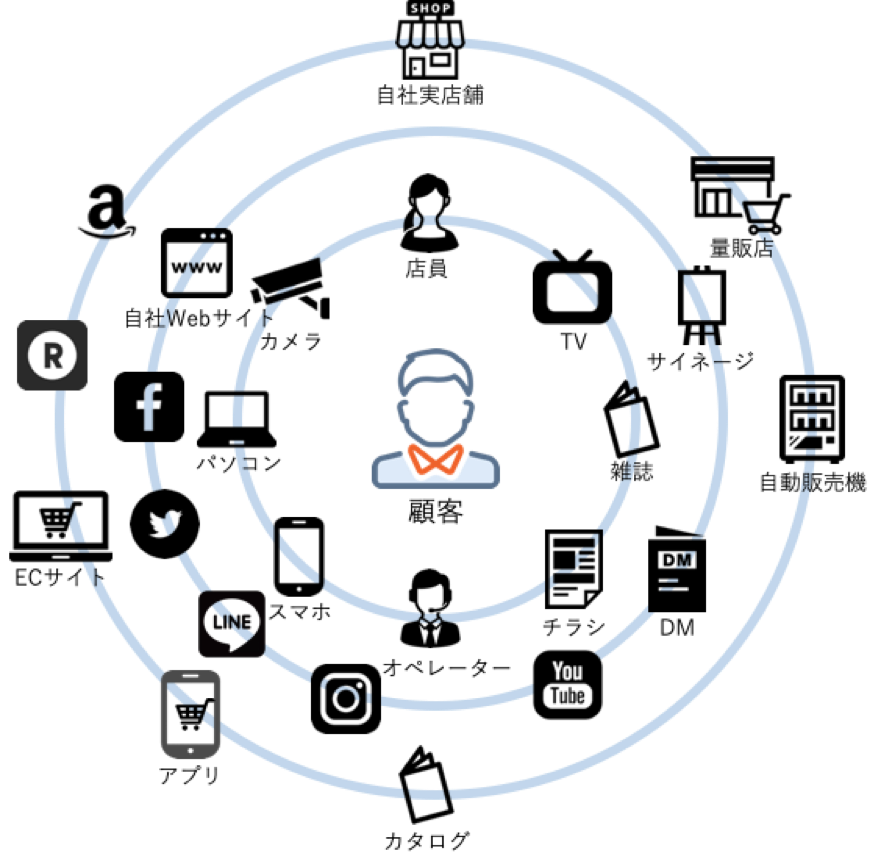
一人の顧客が、同じメーカー/ブランドの商品を、実店舗で購入したり、ECサイトで購入したりするようになってきました。また、アプリで商品に関していろいろと調べたあと、実店舗に来店して購入したり、逆に、実店舗で商品を試着したあと、ECサイトで購入したりすることもあります。
こうした変化に伴い顕著になってきた課題がデータのサイロ化です。一人の顧客のデータが、発生源ごとに別々に管理され、互いに共有されない状況が見られるようになってきています。実店舗の購買データ、ECサイトの購買データ、アプリのアクセスログなどがバラバラに管理されているのです。こうした状況を改善するのがTreasure Data CDPです。大量の顧客のデータを一箇所に収集し、共有することができます。
また、収集したデータを活用する場合、第3者が提供するデータ、第3者が収集した顧客データと組合せると効果的である場合が多いです。特に、旅行などのイベントや、進学・就職・結婚・出産などのライフステージの変化において、消費性向が大きく変わることがありますが、その時、第3社の顧客データと組合せるとそうした変化をとらえやすい場合があります。
Treasure Data CDPはCDPのデファクトスタンダードであるため、利用企業が非常に多く、互いの顧客データをtd_global_idをキーとして一人一人の顧客を一致させる形で、結びつけることができます。
更に、Treasure Data CDPと連携するサービス・プロダクトは非常に多種・多岐にわたるため、データを収取・分析した結果を、様々な施策に落とし込むことができます。
ここでDataRobotと組合せると、できることが一気に広がります。マーケティングひとつ取り上げても、以下のようなマーケティング施策をより精緻に実施できるようになるとともに、自動化によるコスト削減も期待できます。
- ターゲットセグメンテーション
- マーケティング反応予測(開封・クリック・コンバージョン予測)
- 解約予測・休眠顧客掘り起こし
- 顧客満足度予測
- LTV予測
- プロダクトミックス
- クロスセル・アップセル・レコメンデーション
- アトリビューション分析・マーケティングチャネル最適化
- 価格弾力性予測
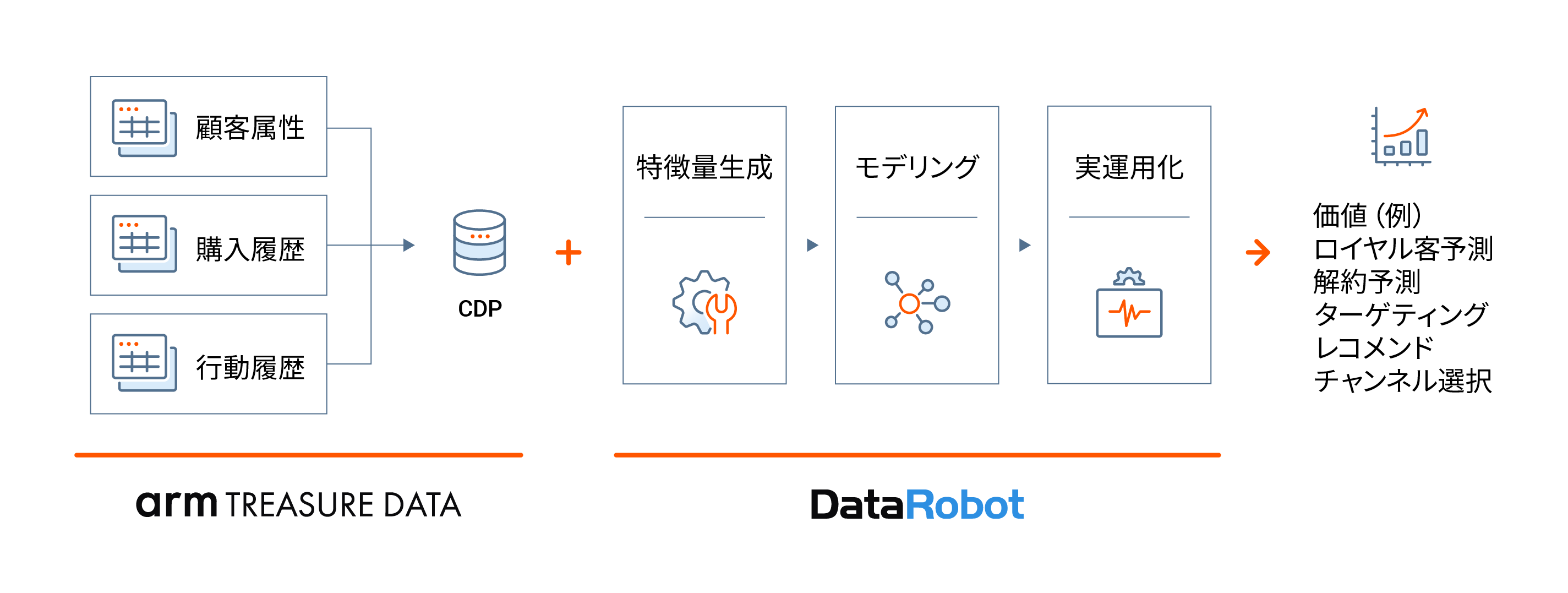
以下、仮想のアパレルメーカーを例に、Treasure Data CDPとDataRobotとを組み合わせて使う効果を示していきたいと思います。
A社は老舗アパレルメーカーです。従来は実店舗のみで販売しており、顧客はハウスカードで管理してきました。しかし、数年前からオンラインショップでも販売を開始し、こちらの顧客はデジタル会員証で管理しています。オンラインショップはWebだけでなく、独自アプリからもアクセスすることができます。実店舗は実店舗の販売履歴のみを使用して、アプリの利用者に対してはアプリ経由のオンラインショップの購入履歴のみを使用して、それぞれ個別にマーケティング施策を打ってきました。これからはOMO(Online Merged with Offline)を意識して、実店舗では実店舗でしか提供できない体験を提供することにより、総合的にマーケティングを打ちたいと考え、ハウスカードからデジタル会員証への移行(統一)を完了したところです。これから、新しいマーケティング施策を打つ予定であり、そのターゲッティングをしたいと考えています。
ここで、使用するデータは、以下の6つのテーブルです。
- 顧客別キャンペーン履歴
- 顧客マスター
- 商品情報
- 実店舗購入履歴
- App購入履歴
- Web購入履歴
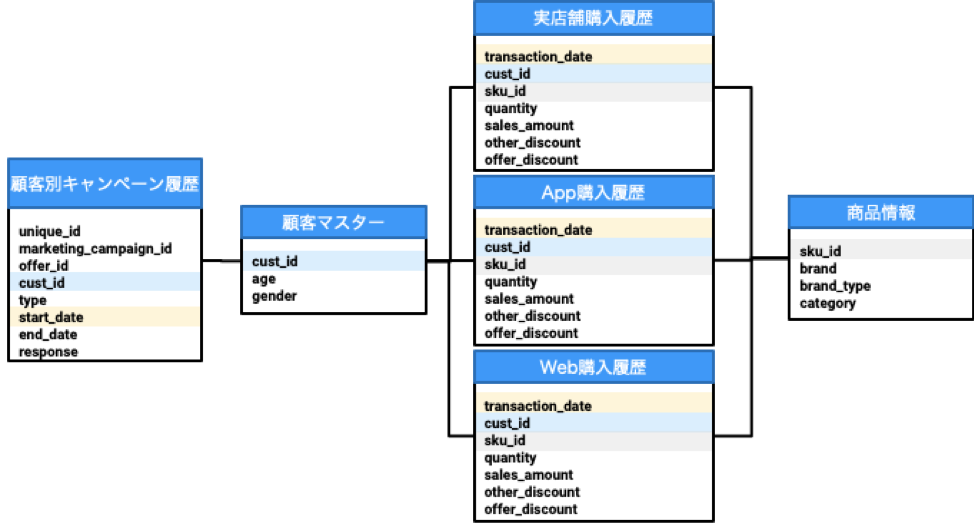
この6つのテーブルすべてがTreasure Data CDPに格納されているとします。
Treasure Data をDataRobotのAI Catalogに登録
まずDataRobotに Treasure Data のデータ接続を登録します。
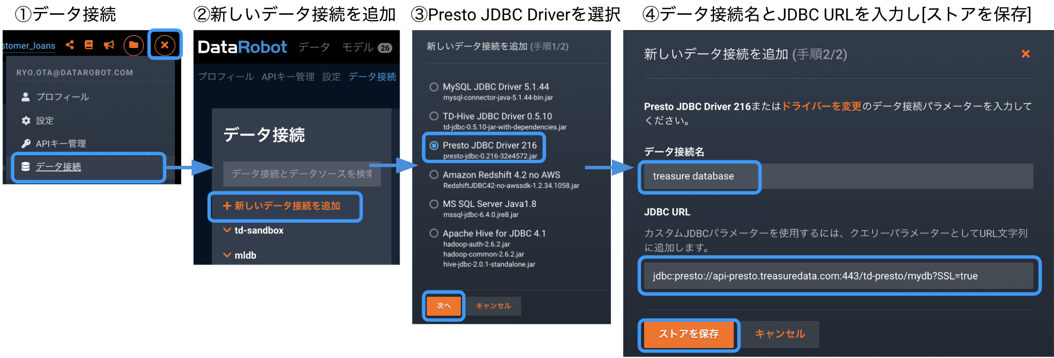
続いて、AIカタログからデータ接続を利用し、使用したいテーブルを登録します。ここでSQLを記述する必要はなく、テーブルをいくつかクリックし、まとめてカタログに登録できます。
AIカタログにテーブルが登録されると、新しいプロジェクトを作成できるようになります。
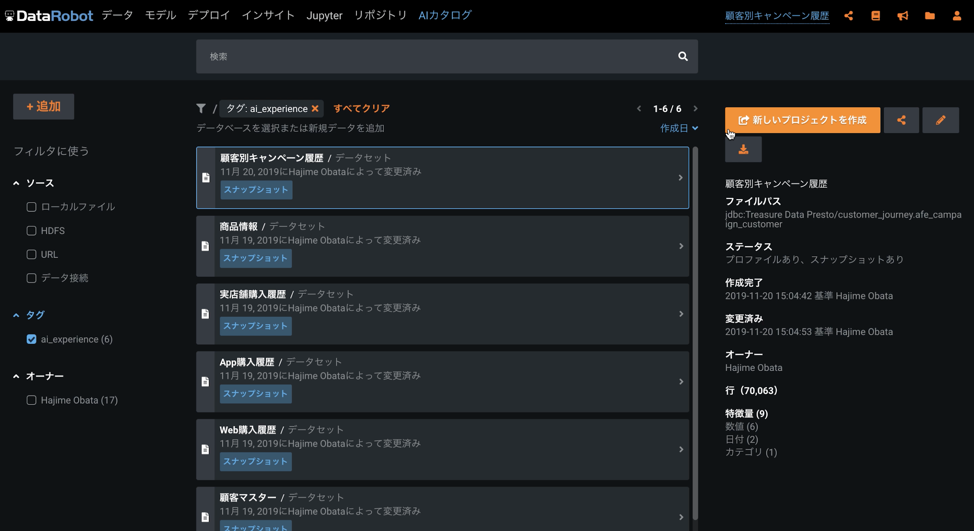
DataRobotの自動特徴量探索を経て予測モデルを構築
自動特徴量探索の設定は簡単です。プロジェクトデータ(ここでは「顧客別キャンペーン履歴」)をアップロードし、ターゲット(「redeem」)を指定すると、「特徴量探索」エリアのメニューを使用して探索設定を行うことができます。
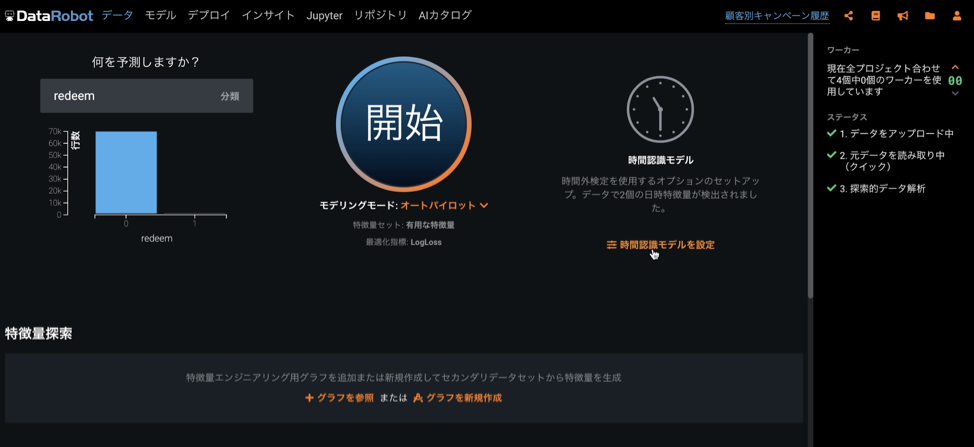
「グラフを新規作成」を使用してセカンダリーデータとの関係性を定義します。ここでの「グラフ」とは表や図といった意味ではなく、「関係性」を意味しています。例えば以下の例では、プロジェクトデータセットと「実店舗購入履歴」をそれぞれの「cust_id」列を使って結合し、さらに「実店舗購入履歴」と「商品情報」をそれぞれの「sku_id」列を使って結合するように定義していることがわかります。
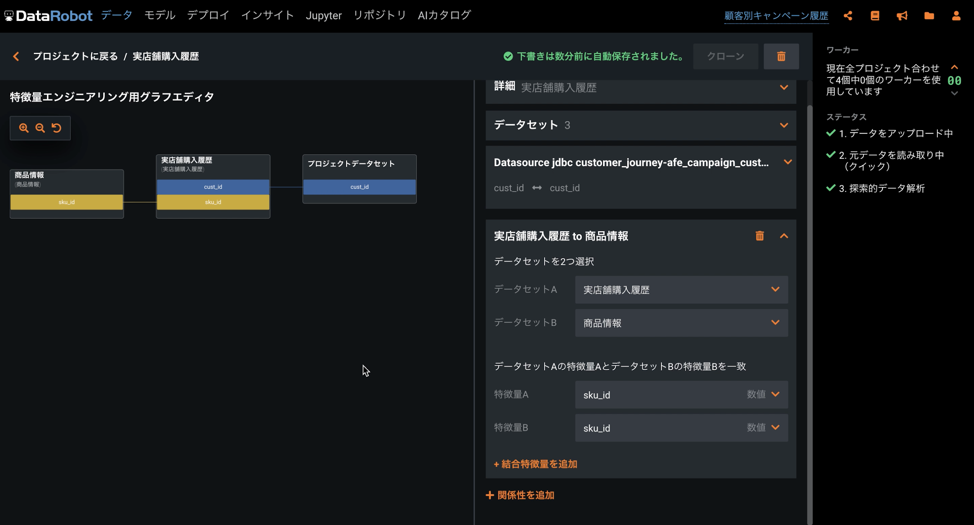
同様に他のデータに対してもグラフを作成しました。この例では時間を意識した結合も設定しており、プロジェクトデータの「start_date」列を見てそれより30〜0日前の購入履歴のみを集計・結合対象とするようにしています。
これでは準備は完了です。「開始」ボタンをクリックしてオートパイロットをスタートさせましょう。
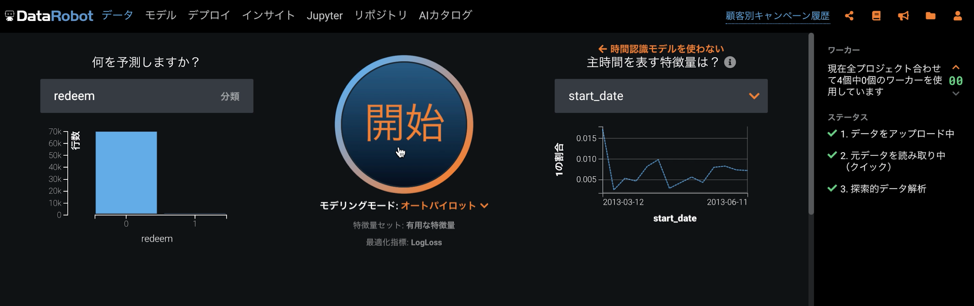
自動特徴量探索の設定を行っている場合、オートパイロット中に特徴量の探索や生成を自動実行するステップが追加されます。ここでデータの集計や結合が自動的に行われます。
この例ではプロジェクトデータには4つの特徴量しかありませんでしたが、特徴量探索により最終的には187の特徴量が使用されていることがわかります。
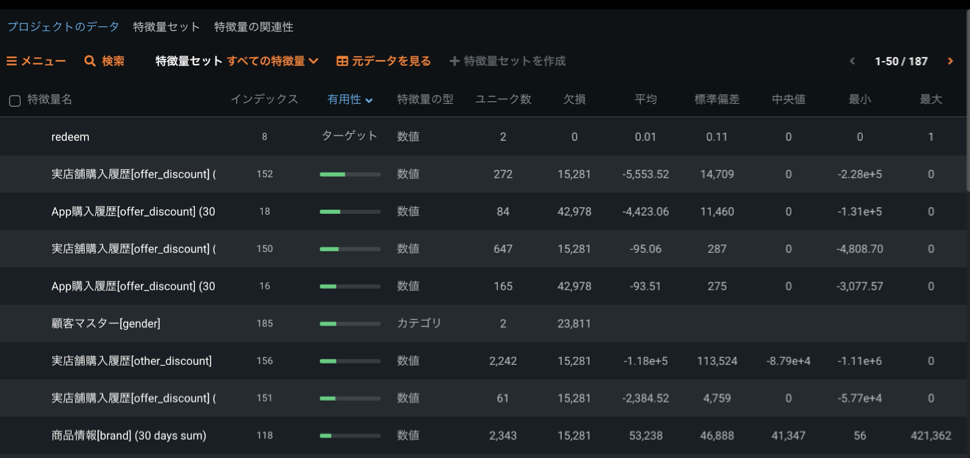
AIによる顧客インサイトと、予測のさらなる活用方法
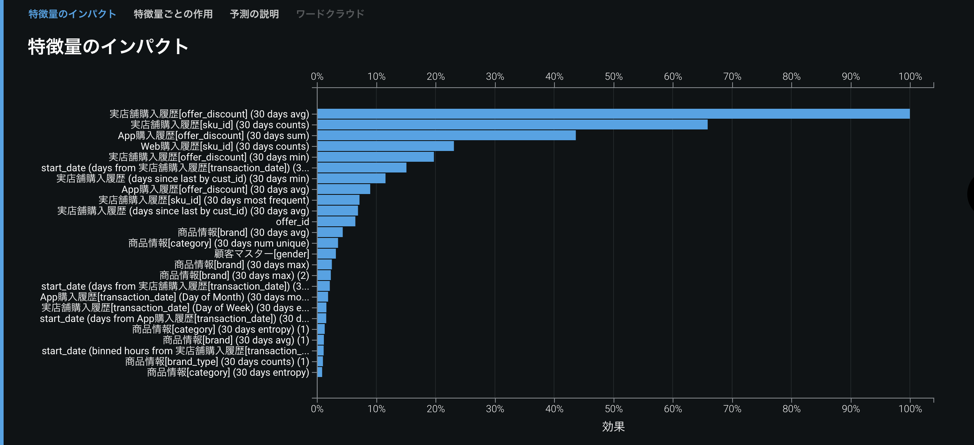
DataRobotが作成したモデルのうち、「デプロイ推奨」というバッジが付いたモデルを見てみましょう。下図はDataRobotの「特徴量のインパクト」という機能で、モデルの生成に用いられた特徴量を、ターゲットの予測に与える影響度の大きな順に並べたものです。一番上の特徴量の影響度を100%としたときの相対影響度で表示されます。
特徴量名の末尾に()で「30 days avg」とあるような特徴量はすべてFeature Discovery機能によって自動生成されたものです。この図で表示されている25個の特徴量のうち、元のテーブルにあった既存の特徴量はoffer_idとgnederのわずか2つです。それ以外はすべてFeature Discoveryによって生成されており、Feature Discovery機能がいかに強力かが分かります。これを自分で生成しようとすれば、膨大な時間がかかり、しかも、同じような特徴量をすべて見つけ出すのは至難の業でしょう。自動生成された特徴量が上位にきていることから、得られるモデルの精度にも大きく影響することが容易に想像できます。
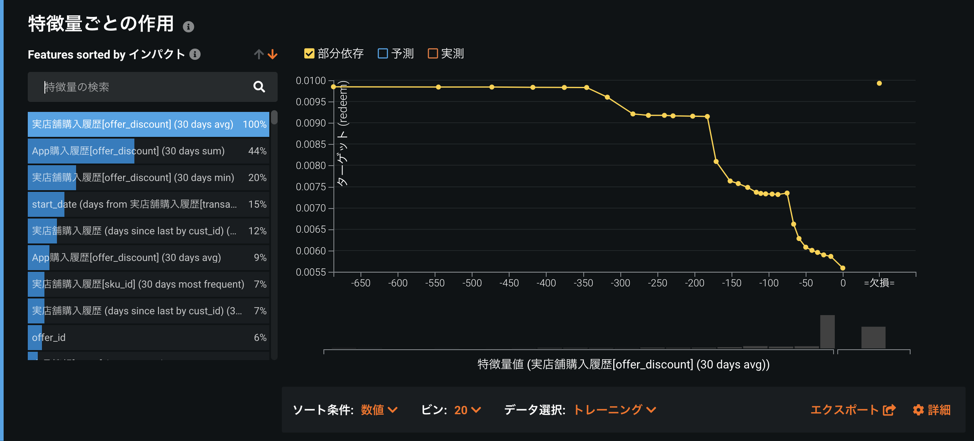
また、上位に来ている特徴量に関し、DataRobotの「特徴量ごとの作用」という機能を使って、その特徴量を単独で変化させたときのターゲット(今の場合はマーケティング施策の反応率)の変化を見ることにより、今後のマーケティング施策の設計を最適化できます。
例えば、実店舗購入履歴[offer_discount](30 days avg)を見ると、実店舗でのディスカウントは、たかだか350ドルまでとしても、なんら問題はないと考えられます(ただし、サンプル数が少ないことに注意する必要があります)。
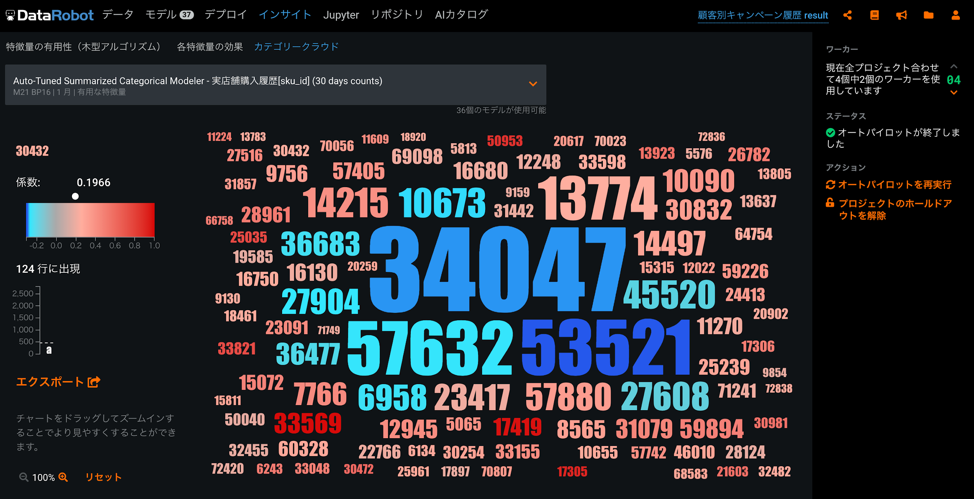
実店舗購入履歴[sku_id](30 days counts)の様子は、DataRobotの「カテゴリクラウド」という機能を使って見ることができます。この機能は、サンプル数の大小を文字の大きさで、ターゲット(今の場合はマーケティング施策の反応率)の予測値の高低を文字の色(赤いと高い)で表現するものです。この図から、既存の商品をキャンペーン対象とする場合、sku_id 53521の商品は今後キャンペーン対象とすべきではないことが分かります。代わりに、33569や17419を用いた方が反応率は高くなると見込めます。
以上のように、Treasure Dataに格納された大量のトランザクションデータから、DataRobotのFeature Discovery機能を使って、有用な特徴量を大量に自動生成することにより、精度の高いモデルが得られ、かつ、今後のマーケティング施策の設計に対するインサイトが得られることが分かります。

DataRobot Japan チーフ・データサイエンティスト。ロンドン大学高エネルギー物理学博士課程修了。ニューヨーク大学でのポスドク研究員時代に加速器データの統計モデル構築を行い「神の素粒子」ヒッグスボゾン発見に貢献。その後ボストン・コンサルティング・グループでコンサルタントとして、主に TMT/製薬業界でのデータ分析業務に従事。AI 型情報キュレーションを提供する白ヤギコーポレーションの創業者兼 CEO を経て2015年に DataRobot Japan の立ち上げに一人目のメンバーとして加わり現職。個人ブログにhttps://ashibata.com/、共著に「データ活用実践教室」(日経BP社)など
直近の注目記事
AI活用を成功に導く方法をサービス商品化した米AIベンチャーの狙い(ZDNet Japan)
シバタアキラ氏が伝授#01/データサイエンスって何?(日経ビジネスONLINE)
この人にはこれが売れる/実践!データサイエンス#09(日経ビジネスONLINE)
データサイエンティストになるには?社内で育てる方法は?わかりやすく解説(ビジネス+IT)

DataRobot データサイエンティスト。某ファミリーレストランチェーンにてデータサイエンティストとして、需要予測、出店計画、新商品の需要予測、退職者予測などのプロジェクトをデータ準備からデプロイまで実施した経験を活かし、主に流通・外食の AI 活用をサポート。
直近の注目記事
データサイエンティストでない人に、データサイエンティストっぽく働いてもらおう(atmarkIT)

DataRobot プロダクトマネージャー。2018年から DataRobot に参加。DataRobot 製品に関するフィードバック収集と新規開発計画への反映、新機能・新製品のベータプログラムやローンチ、トレーニングやマーケティングを通じた普及活動、ローカライゼーション管理、などを通じて、AI と DataRobot の価値を日本に広く広めるための業務に従事。
-
分類プロジェクトの評価でAUCよりも便利なFVE Binominal|DataRobot機械学習モデル評価指標解説
2024/04/05· 推定読書時間 4 分 -
RAG(Retrieval-Augumented Generation)構築と応用|生成AI×DataRobot活用術
2024/04/03· 推定読書時間 4 分 -
バリュー・ドリブンAI:予測AIから学んだ教訓を生成AIに応用する
2024/03/19· 推定読書時間 2 分
最近のブログ記事