機械学習を応用して広告効果を正しく測定する
DataRobotのデータサイエンティスト、緒方良輔です。
私の担当領域は主に小売業やCPG業界なのですが、そういった業界ではマーケティングや販促がどのように売上高などのKPIに影響を与えたかを特定したいという因果効果の推定が分析課題に挙げられることが多くあります。
実はこの因果効果の推定、因果推論とは、機械学習が得意とする予測分析とは大きく異なる部分があります。正い知識に基づいた分析を行わないと、間違った分析とその結果から、ビジネスに大きな損害を与えてしまう可能性があります。
今回の記事では、特に店舗や地域レベルでの因果推論を可能にするシンセティックコントロール*という技術について、どうDataRobotを用いて実行するかを含めてご紹介します。
今回の記事はビジネスにおける広告効果測定への入門を目的としており、内容は厳密さよりも直感的であることを優先しました。前提知識は、機械学習モデリングの基礎を理解している事を想定しています。
予測分析と因果推論
まずそもそも、予測分析と因果推論は、どのように異なるのでしょうか。予測分析とは、読んで字のごとく何かKPIを予測するための分析です。機械学習はこの分野にとても強く、小売や流通ビジネスでは例えば需要予測に基づく在庫量の最適化であったり、web広告に対する反応率を予測してターゲティングを行う際に活躍します。対して因果推論は、KPIの予測が目的ではなく、何かアクションを行った際にKPIがどう変化するかを理解するための分析だといえます。この際に行うアクションを介入と言います。
一見するとこの二つに違いは無いように思うかもしれませんが、本質は大きく異なっています。例えばこんなマーケティングの世界の例で解釈をしてみましょう。予測対象Yをある商品の販売数、特徴量Xをチラシの配布枚数(1000枚単位)とします。そうしたとき、YをXを用いて回帰してみると、下記のような結果が得られたとします。
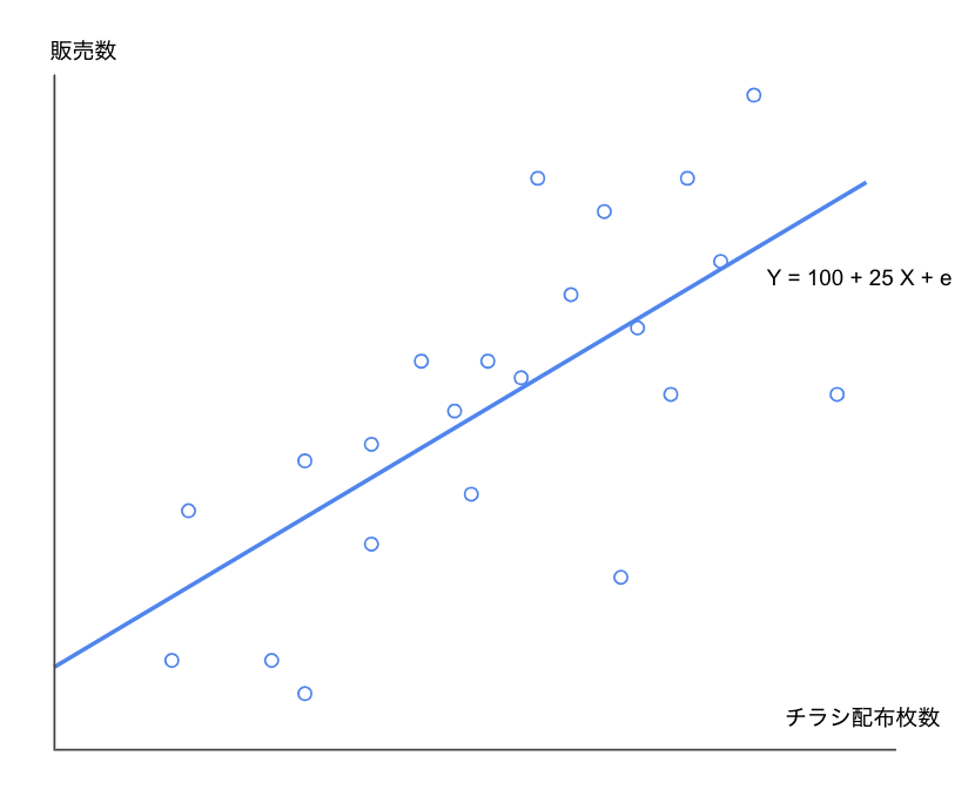
販売数は、チラシを撒いていなかった時に比べて1000枚撒いていた時の方が25個多く売れている、とモデルは説明しています。撒いていなかった時、撒いていた時、という表現がミソです。
もしかしたら、チラシは商品が売れそうな、近隣でイベントのある日に積極的に撒かれていただけかもしれません。そのような日にはチラシがなくても多く商品が売れるので、チラシには実は販売数量を上昇させる力が全く無いにも関わらず、チラシの枚数が予測に使えるという理由だけで、上のような回帰の結果になっているだけかもしれません。
上のモデルは必ずしも、チラシを今1000枚多く撒いたとしたら25個多く商品が売れるといっている訳ではないのです。
上記のような誤解の危険性は、 実は古くから相関と因果の違いという言葉で指摘されてきました。リンク先の論文のタイトルは ”Use and Abuse of Regression” ですが、回帰分析の結果を上記のように因果関係と解釈するのは、典型的なAbuse(間違った使い方)です。にもかかわらず、このような危険性はデータ分析がビジネスにも広く活用されるようになった昨今でもあまり正確に認識されていません。
重要な点ですが、現在広告効果の分析を行う際にビジネスで多く用いられているMMM (マーケティングミックスモデル) は本質的に上記の間違いを犯しており、正確に広告効果を測定することはできていません**。もしかしたら、今この記事をお読みの方も、上記のような予測分析のAbuse (間違った使い方) をしてしまった記憶があるかもしれません。
因果推論とは
ここまでお読みいただくと、「ではどうすればマーケティングの効果を正しく知ることができるのか」という疑問をお持ちになることかと思います。当然ながら統計学はこのようなニーズに応えるため、様々な方法を提案しています。詳しくは説明しませんが、簡単にまとめていきましょう。
実験計画に基づいた実験を行う
因果推論のゴールドスタンダードです。回帰分析における相関と因果の違いは、データのバイアス(偏り)によって起こりますが、因果推論のフレームワークはこのバイアスをどれだけ無くせるかというフレームワークだといっても過言ではありません。
実験計画に基づいて実験を行い得られたデータを分析することで、バイアスのない結果を得ることができます。このようなやり方の一部は、ビジネスでもRCTやA/Bテストという形で受け入れられ始めています。実店舗でのRCTも記事化されるなど、話題に上がるようにもなってきましたね。
実行できればこの方法に勝るものはありませんが、倫理やルールに鑑みて実行が難しかったり、実行のコストを受け入れてもらうことが難しかったりといった理由で選択肢として存在しない状況も多くあるようです。
バックドア基準を満たす
バイアスを除去するために、バイアスのない状況を作り出し、そこからデータを生成するのが実験計画の考え方ならば、これ以降の方法はバイアスのある状況で生成されたデータを元に、どうにかこうにかバイアスを除去していこうという立場にあります。
バックドア基準はその中でも、用いる特徴量を制限するこでバイアスを制限し、回帰分析から得れた結果が正しい因果と解釈できるようにする手法です。
これは疫学などの文脈から発展し今日でも利用されている強力な手法ですが、残念ながら工場や研究所といった高度な統制下にない環境で生成されたデータに利用することは非常に困難です。なぜならば、この方法は関連するKPI間の因果関係の有無を事前に網羅的に知っていることを必要とします。様々な要因が絡み合い、そして必ずしも網羅的にデータが取得できているわけではないマーケティング領域などでの活用は事実上困難です。
プロペンシティスコアによるマッチングを行う
対してバイアスのある状況で生成されたデータを元に、そのデータを用いてバイアスを制限しようとするのがマッチングの考え方です。プロペンシティスコアは、直感的には***、効果をみたい過去の介入への暴露確率です。例えば店頭で次回使えるクーポンをもらった人が、次回の会計額がどれくらい変動するかという因果効果をみたい場合を考えましょう。この時、例えばクーポンをもらっている人には来店頻度が高く、もらっていない人には来店頻度が低いというバイアスが含まれている可能性があります。そのためクーポンをもらった人ともらっていない人の会計額を比べただけでは、来店頻度によって会計額が変化する場合(頻度の低い人は一度に大量に買っていくなど)、フェアな比較になりません。そこで施策への暴露確率(この例の場合はクーポンをもらう確率)を手元のデータから計算し、その確率が同じ対象でマッチングし比較します。そうすることで、バイアスを除去し、フェアな因果効果の推定が可能になります。
この方法をDataRobotで実行するには、弊社のデータサイエンティストである伊地知、山本による機械学習を用いた要因分析(理論編1、理論編2、実践編)をご覧ください。
シンセティックコントロール
他にも外的要因(税制など)の変化を利用して因果効果を推定する回帰不連続デザインや、操作変数法など様々な状況に有利な性質を持つ手法が存在します。が、それらの紹介は別に譲り、本ブログの目的であるシンセティックコントロールの紹介に移りましょう。
シンセティックコントロールとは、本質的には介入がなかった場合のKPIの予測によるバイアスの統制です。元々は介入がなかった場合のKPIの、広い意味での加重平均を取ることで、介入がなかった場合のKPIを予測していました。そして、昨今の予測モデリング技術の向上を受け、介入から影響を受けない特徴量を用いて、影響をみたいKPIの予測を行うモデルを作るという考え方に発展してきています。この様なシンセティックコントロールの発想は、マッチングという考え方と、差の差分析と呼ばれる時系列を考慮した因果推論のフレームワークの流れを組んでいるものと筆者は理解しています。
さて、シンセティックコントロールを提案した Abadiなどの論文では、カリフォルニア州のタバコへの税率変更によるタバコの市場に与える影響を、他州のタバコの市場のデータを用いて分析しました。他州のタバコの消費量は季節性や社会的なタバコへのイメージの変化への情報を持っており、かつカリフォルニア州の税制変更の影響をほぼ受けないと考えられます。ですので、他州のタバコの消費量を用いてカリフォルニア州の税制変更前の消費量を時系列で予測できれば、税制変更後は同様の予測がカリフォルニア州が税制変更をしなかった場合の販売数を表現できていると解釈できます。ですから、予測と実測の引き算が、因果効果だと解釈できるのです。
イメージとしては下記の通りです。介入を受けた、実際の販売数データが青線、介入を受けていない地域の販売数を元に予測した、介入を受けた地域の販売数が灰線です。
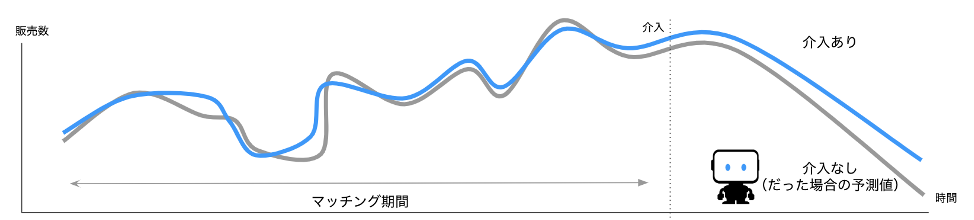
マッチング期間といわれる、介入を受ける前の期間で両者の差が十分に小さい事を確認しておきます。その状況では、介入後の予測値は「もしも介入先が介入を受けていなかった場合の販売数」として解釈できます。ですから、介入後の予測と実測の差が、この介入の因果効果であると解釈できるわけです。

ケーススタディーはこれだけではなく、他にも論文ベースで、バスク地方の一人当たりGDPがテロによってどのような影響を受けたかや、東西ドイツの統合が同じく一人当たりGDPに対して与えた影響などがシンセティックコントロールを用いて分析されています。
これをビジネスに応用するとどうなるでしょうか。この手法の拡張で、例えばGoogle社のメンバーが TV広告がもたらすオンライン検索数への影響の効果測定を行なっています。また少し余談ですが、一般的にこの様な分析を実行するための R パッケージである CausalImpact も彼らは提供しています。
他にもこのフレームワークを用いることでTV広告の影響だけでなく、例えば店舗の出店によるカニバリ効果を正確に測定したりすることも可能です。前述の実験計画、特にRCTと組み合わせれば、少ないコスト(実験店舗数)で、新商品導入による来客効果やクーポニングの影響を推定することもできます。
それでは具体的に、DataRobotを用いて何らかの介入効果を測定するためには、どのようにすればよいでしょうか。
まず、分析可能な状況として、効果を測定したい施策の介入、非介入が別れているような状況を特定します。これはマーケティングを例にとると、概ね下の様な2パターンに大別できるでしょう。
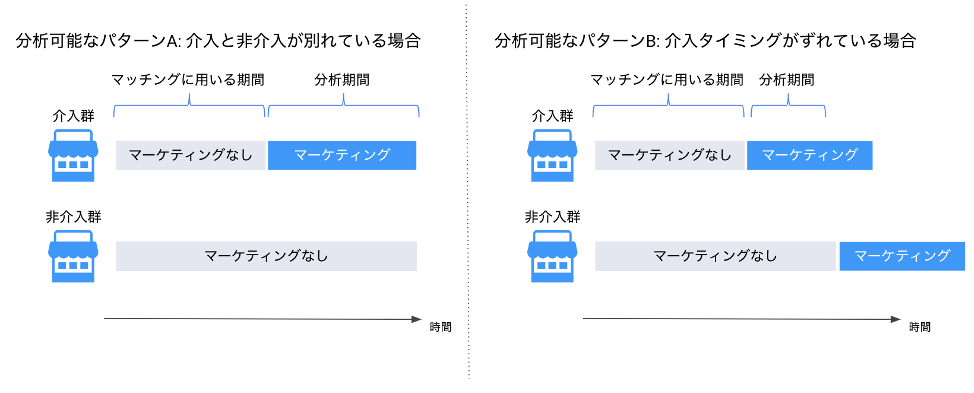
そして、介入群、非介入群の介入直前までのKPIそれぞれを取得して、下記の様なデータマートを作成します。
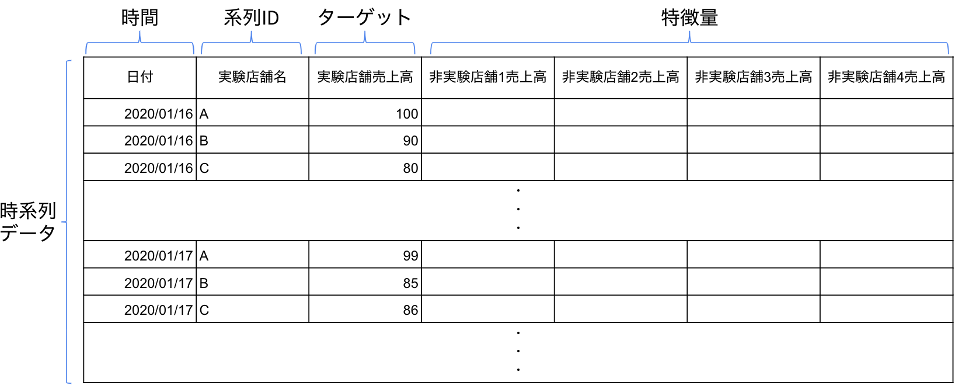
このデータマートを用いて、ターゲットの時系列予測モデリングを行います。出来上がったモデルを確認し、十分に予測値と実測値の乖離が小さいこと、予測値と実測値の差に何らかの傾向がないことを確認する様にしてください。
モデルの選択が終わったら、介入後の時期のKPIを予測します。この予測値と実測値の差をとったものが因果効果だと解釈できます。
シンセティックコントロールの何が優れているかと言うと、上記の通り予測分析のフレームワークを用いて分析が可能なこと、結果が単純明快なこと、RCTとの組み合わせが可能なこと、だけではありません。その真の力は、1店舗1店舗に対して効果の推定を行える点にあります。先の説明の様に、マッチング(介入なしの場合の予測)を介入群全ての店舗に対して行うので、十分な予測精度が担保できれば、どの介入先でどれほどの影響があったかを直接推定できます。
これを応用すると、さらに価値のあるビジネスクエスチョンにも答えることができます。すなわち「この施策は効果があるのはわかったが、どの店舗/地域で展開するのがもっとも投資対効果が高いのか」というようなものです。
この方法では、先に測定した1店舗ごとの介入効果をターゲットとして、店舗ごとの特徴(サイズや周辺の人口総数)などを用いてもう一度回帰モデルを作成します。これにより、どのような箇所でこの施策の影響が高いのか、逆に低いのかに答えることができます。このモデルを利用することで、ROIが最も高くなる様に地域ごとに施策の出しわけが実現できるのです。
シンセティックコントロールはコンセプトが単純明快であり、一般的に非常に難しい因果効果の測定をいくつかの注意点に気をつければ比較的簡単に行えます。ビジュアルアウトプットが豊富なDataRobotを用いると、より効率的に分析が行えると思いますので、ぜひチャレンジしてみてください。
*正確には、その応用。
**MMMがビジネス上無意味であることは意味していません。限られたリソースの中であれば、リスクを認識しながら、この様な分析を行う場合もあると思います。
***正確でない表現ですが、直感的にこの様にこの様に理解していただくのが当初は良いと思います。
-
分類プロジェクトの評価でAUCよりも便利なFVE Binominal|DataRobot機械学習モデル評価指標解説
2024/04/05· 推定読書時間 4 分 -
RAG(Retrieval-Augumented Generation)構築と応用|生成AI×DataRobot活用術
2024/04/03· 推定読書時間 4 分 -
バリュー・ドリブンAI:予測AIから学んだ教訓を生成AIに応用する
2024/03/19· 推定読書時間 2 分
最近のブログ記事