

Measure Once, Cut Twice: Moving Towards Iteration in Data Science
The process of software development has changed dramatically over the last 20 years. Eric Raymonds, a noted open source software developer, pushed back against software that was “built like cathedrals, carefully crafted by individual wizards or small bands of mages working in splendid isolation, with nothing to be released before its time.” This is known as the waterfall methodology, which is a metaphor for how water moves in one direction. In opposition to this method, Raymonds argued for a more iterative development process that emphasized releasing earlier and more often.
In this article, I suggest why all data science teams should adopt a more iterative approach that focuses on building a model quickly first, and then steadily improving it.
Raymond’s argument prevailed, and software development moved away from the waterfall methodology and towards the more iterative methodology. Though software development has made this switch, many data science teams continue to build models using the waterfall methodology. In this article, I suggest why all data science teams should adopt a more iterative approach that focuses on building a model quickly first, and then steadily improving it. Andrew Ng, a top artificial intelligence (AI) expert, discusses two approaches in his machine learning course. In this post, I have summarized these two approaches as: the waterfall approach and the iterative approach.
The Waterfall Approach
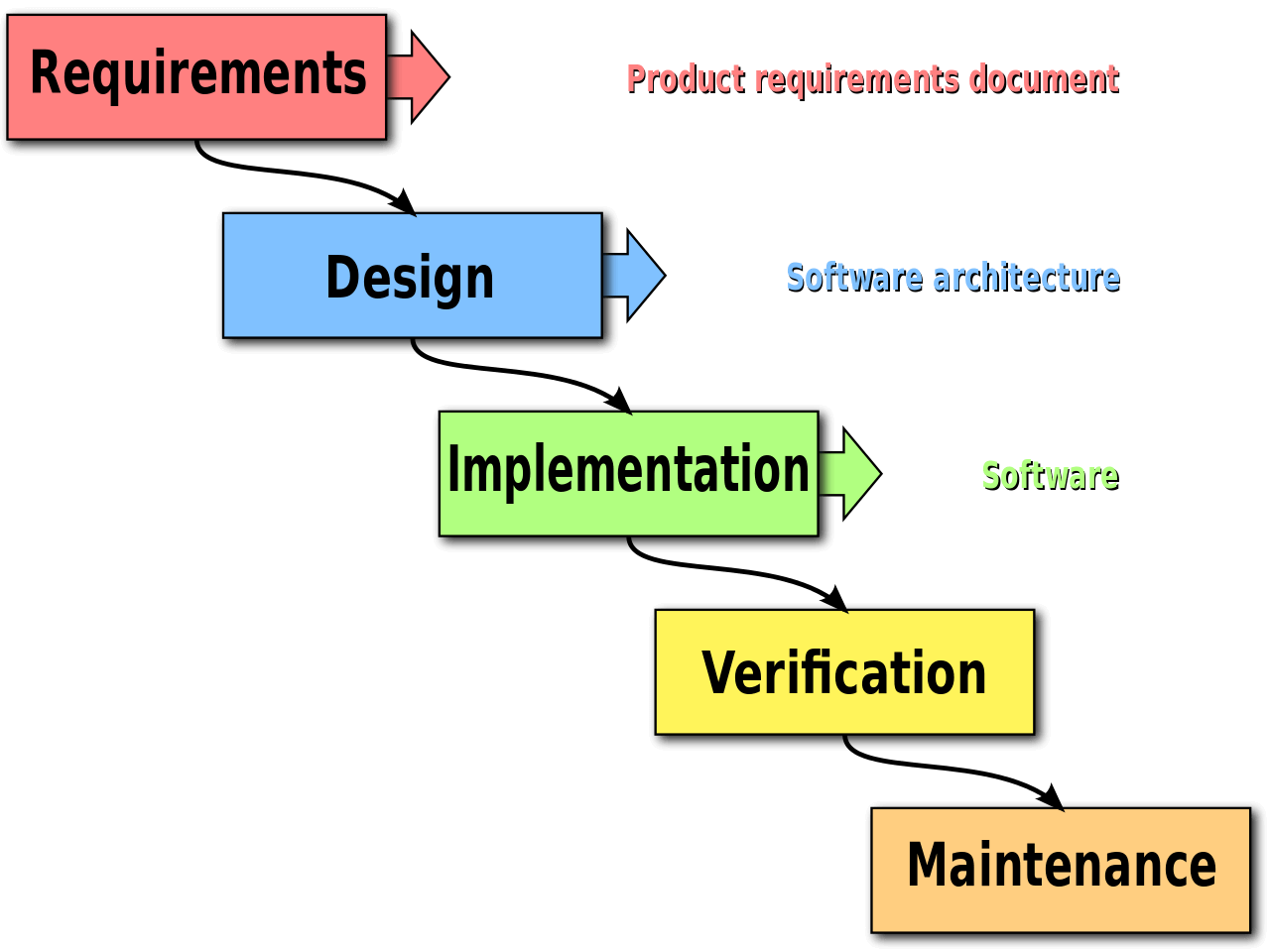
The waterfall approach sees model building as a set of discrete steps that move in a constant and uniform direction. At the start, the focus for the data scientists is to think about all of the best variables or features before the modeling event starts. Time is then spent collecting all these features, and carefully cleaning each one to ensure the dataset is perfect before the modeling begins. When it comes to modeling, the emphasis is on customizing the algorithmic architectures to exactly fit the problem. The final step in this approach is implementing the model and hoping it works. The typical data science lifecycle for modeling using a waterfall approach is measured in weeks and months.
The Iterative Approach
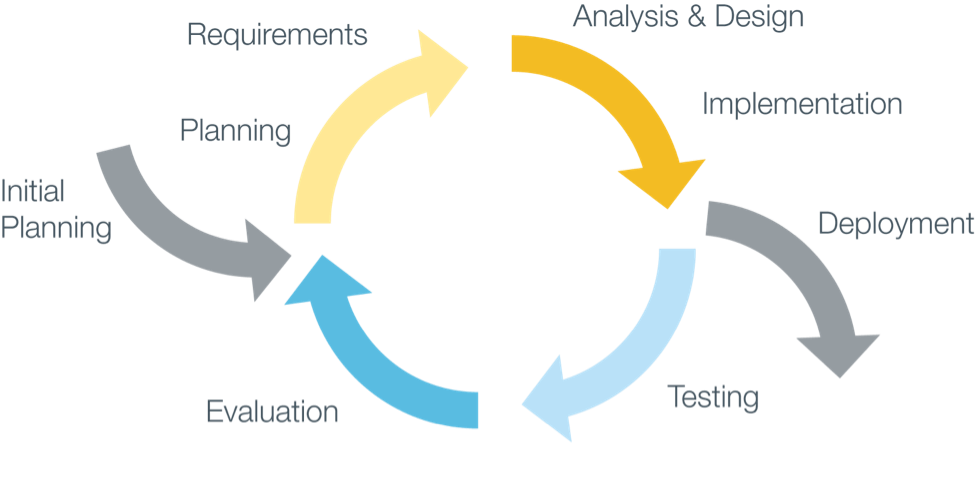
However, the iterative approach in data science starts with emphasizing the importance of getting to a first model quickly, rather than starting with the variables and features. Once the first model is built, the work then steadily focuses on continual improvement. Data scientists use model error analysis and diagnostics to find weak areas of the model. They will reach out to the domain experts to understand what the model is doing right and where it can be improved. The typical data science lifecycle for modeling using an iterative approach is much shorter, and ends when the model has improved enough to meet the business requirements.
Iteration and Waterfall in Action
The iterative approach is used by the winners of machine learning competitions. The winning strategy in these competitions is to start with a simple working model and then iterate. Iteration often involves bringing in domain knowledge and trying new data science techniques. These steady and continual improvements are what’s needed to build the best models and win competitions. In contrast, the waterfall approach is often best used for novel and extremely difficult problems that can’t be adequately solved through iteration.
In contrast, the iterative focus on continual improvement pushes data scientists to work with domain experts to more frequently improve their models.
Data science teams within enterprises often have changing timelines and need to interact with other domain experts. A waterfall approach with an emphasis on following a schedule means that the data scientists can’t respond to changing business needs whenever they may occur. In addition, the longer time required often means that projects, if they do finish, are out of date by the time they are complete. This may lead to a perception that the data scientists are out of touch with the business needs. In contrast, the iterative focus on continual improvement pushes data scientists to work with domain experts to more frequently improve their models. And when timelines run short, the iterative approach can offer a working model that is up to date with business needs
So, next time you talk to your data science team, take some time to understand their approach. Are they generally working in an iterative approach, or are they just moving in one direction? How much time is between the start of a project and building the first model? How much are they iterating along the way? How often are they talking to the domain experts? Is there a steady progression of improvement over time?
If you need assistance in moving towards an iterative paradigm, reach out to us at DataRobot. We have designed and created an automated machine learning solution that allows users to quickly build models and continually improve upon them. The timeline for building models shrinks down to hours and days.

About the Author:
Rajiv Shah is a data scientist at DataRobot, where he works with customers to make and implement predictions. Previously, Rajiv has been part of data science teams at Caterpillar and State Farm. He enjoys data science and spends time mentoring data scientists, speaking at events, and having fun with blog posts. He has a PhD from the University of Illinois at Urbana Champaign.
-
How to Choose the Right LLM for Your Use Case
April 18, 2024· 7 min read -
Belong @ DataRobot: Celebrating 2024 Women’s History Month with DataRobot AI Legends
March 28, 2024· 6 min read -
Choosing the Right Vector Embedding Model for Your Generative AI Use Case
March 7, 2024· 8 min read
Latest posts
