


DataRobot Automated Feature Discovery
Feature engineering is a critical part of the data science lifecycle that, more often than not, determines the success or failure of an AI project. At DataRobot, we know how hard it is to get started with AI, so we decided to take our automated feature engineering capabilities to the next level.
DataRobot’s Feature Discovery accelerates feature engineering by generating hundreds of valuable new features using the relationships between your primary and multiple secondary datasets. This enables you to build better models from a wider range of more relevant features. You can also do this in less time than you ever thought possible, thereby increasing the pace of innovation with AI for your entire organization.
Background
The difference between the models of legend and those of mediocrity lies in one place: feature engineering. Enterprises adopting machine learning often experience significant challenges going from raw data to a deployable model. There are many reasons for that:
- Finding the Data: Data is rarely in one place. It’s usually spread out across multiple source systems and tables and requires integration before it can even be used.
- Feature Engineering: Transformations are often needed to make features useful for models. This “feature engineering” often requires engineering skills and significant trial and error to get right.
- Domain Expertise: Beyond engineering skills, your team needs a keen understanding of the business and data. For example, in medical use cases, domain expertise is needed to know that two alternatively named pharmaceuticals are actually the same drug.
- Deployment: When deploying a model, the feature engineering process needs to be adapted for a live production environment. This means that in order to support model monitoring and maintenance, these features have to be recomputed (often periodically) with fresh data. It is common to see a new team becoming responsible for this effort.
Simply put, feature engineering is a labor-intensive, human-driven process that is extremely time-consuming, repetitive, and prone to error. Given its importance, a different approach is clearly needed.
Better Models Using Next-Gen Automated Feature Engineering
Current approaches to feature engineering can be greatly accelerated using AI and automation. By allocating the arduous and repetitive tasks to machines, humans can focus on managing the process, intervening when business understanding needs incorporating.
At DataRobot, we have always believed in automation first, which is why we’ve invested so much in automated feature engineering throughout the DataRobot AI Cloud platform. These capabilities take the form of:
- Exploratory data analysis to prepare basic features from raw data.
- Specialized automated feature engineering and reduction for time series data.
- DataRobot blueprints that optimize features for the unique requirements of each and every algorithm in our library.
As confirmed by our customers, this combination of approaches achieves incredible results for every individual model evaluated, but we have not stopped there.
Over the last few years, we looked at revolutionary ways to inject an even higher level of automation into feature engineering. After exploring the best products in the market, we realized our vision could only be realized by building something in-house. With that, we formed a team, led by our Head of R&D in Singapore, Kenny Chua, focused entirely on building the next generation of automated feature engineering.
Feature Discovery is All About Relationships
DataRobot enables users to access a shared catalog of data assets from a wide variety of source systems and locations. Users can now access all the datasets they need for their projects in one place. Not only can they access all of this data but they can also use their domain expertise to inform DataRobot of known relationships between the datasets via a simple and intuitive UI. From these relationships, users can also leverage different data types such as transactional, text, images and geospatial data. It simplifies the collaboration process between different teams and departments for getting the data you need for your AI project.
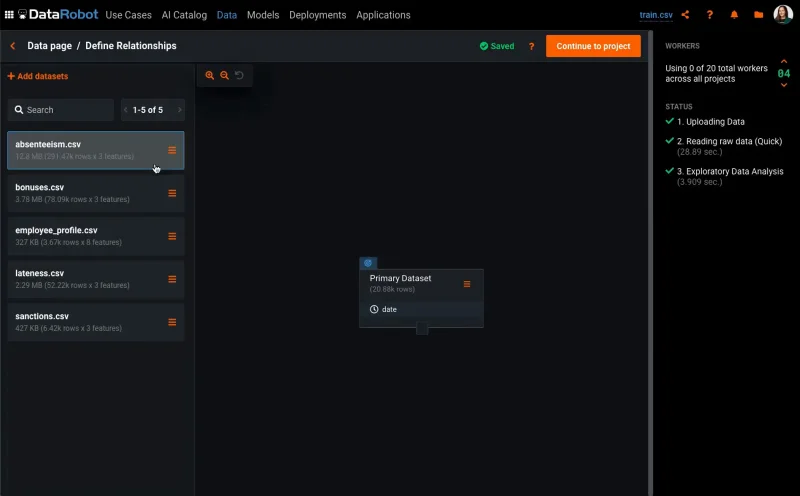
Above: How DataRobot incorporates several related datasets into a single AI project
DataRobot Feature Discovery uses these often complex relationships to intelligently generate large numbers of new and useful features from all the datasets in play. This gives each and every model tested a much broader set of relevant features upon which to base predictions with staggering results. When possible Feature Discovery operations are pushed into the database to minimize data movement and get faster results (read more on snowflake integration).
For more advanced users, Feature Discovery and relationship definition are available via the DataRobot API to support further automation and complex workflows.
Feature Discovery Is Transparent
The transparency of a model depends on understanding not only the model building process but also its training and prediction data. With automated feature engineering where multiple data sources are involved, data lineage becomes increasingly complex, and hence requires that each individual feature can be clearly explained in order to support user confidence and trust. DataRobot Feature Lineage allows users to audit the full data lineage in a simple and fully documented graphical representation.
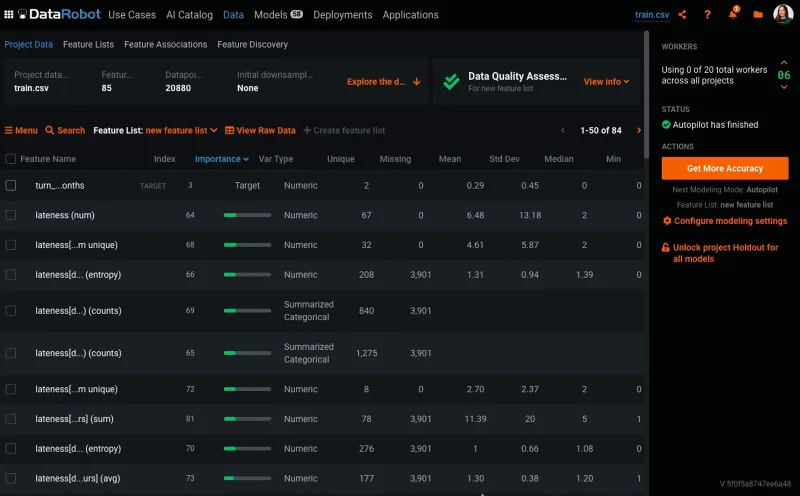
Above: Feature Lineage maps data sources and applied transformations for feature generation.
Ease of Deployment
DataRobot models that use Feature Discovery to leverage multiple datasets are as simple to deploy as models that use a single data source. This way the user doesn’t have to deal with the traditional complexities of feature engineering when the model goes into production. DataRobot Feature Discovery integrates seamlessly with DataRobot deployment/MLOps capabilities. These MLOps capabilities include model monitoring, management, and governance.
We Beat Other Tools on Accuracy and Performance
Throughout our journey, we’ve constantly measured the performance of our engineered features against other products in the market. We compared our capabilities with feature tools from Feature Labs. DataRobot has better accuracy, is 85% faster, and uses less than half the number of generated features for a variety of different models. This is because DataRobot intelligently focuses on creating the right features for each and every model evaluated, versus a one-size-fits-all approach that creates large numbers of valueless and redundant features. In addition, DataRobot Feature Discovery is able to operate on datasets that have complex, multi-key, or manny-to-many relationships to support a wider variety of real-world use cases. We strongly believe that DataRobot’s Feature Discovery, and all of its additional automated feature engineering capabilities, will be the new bar to beat in the market.
Summary
Feature Discovery is automated feature engineering taken to a new level. DataRobot automatically discovers, tests, and creates hundreds of valuable features and helps you build better models with less time and increase your pace to innovate with AI. Learn more about recent product updates in the 7.0 Release.
DataRobot is the leader in Value-Driven AI – a unique and collaborative approach to AI that combines our open AI platform, deep AI expertise and broad use-case implementation to improve how customers run, grow and optimize their business. The DataRobot AI Platform is the only complete AI lifecycle platform that interoperates with your existing investments in data, applications and business processes, and can be deployed on-prem or in any cloud environment. DataRobot and our partners have a decade of world-class AI expertise collaborating with AI teams (data scientists, business and IT), removing common blockers and developing best practices to successfully navigate projects that result in faster time to value, increased revenue and reduced costs. DataRobot customers include 40% of the Fortune 50, 8 of top 10 US banks, 7 of the top 10 pharmaceutical companies, 7 of the top 10 telcos, 5 of top 10 global manufacturers.
-
How to Choose the Right LLM for Your Use Case
April 18, 2024· 7 min read -
Belong @ DataRobot: Celebrating 2024 Women’s History Month with DataRobot AI Legends
March 28, 2024· 6 min read -
Choosing the Right Vector Embedding Model for Your Generative AI Use Case
March 7, 2024· 8 min read
Latest posts
