

Successful CECL Compliance with Automated Machine Learning
Current Expected Credit Loss (CECL) compliance standards are extremely complex, with many moving pieces. CECL streamlines credit loss expectations across the industry by factoring in future expected losses into capital reserves. Ultimately, this will drive greater reliability of expected loss estimates and capital reserve targets across the industry. To put it simply, the CECL methodology is intended to capture the risk of your portfolio, whereas the current accounting standards simply capture the losses in your portfolio.
However, successfully implementing a CECL compliance process has many challenges. In this blog, I explain how automated machine learning will optimize your CECL process to give your bank a competitive advantage and how DataRobot can be used by your organization to effectively harness regulatory change as a strategic opportunity to drive tangible business value.

Building a CECL-Compliant Model With Automated Machine Learning
Regardless of an institution’s chosen methodology for estimating expected lifetime losses, there are common areas of consideration for any CECL-ready model and process. These include effective data management and governance processes, an adequate granularity of data (e.g., contractual life, segmentation), reasonable and supportable methodologies, forecasts, adjustments, and sound and robust documentation. Let’s dive into how automated machine learning will accelerate your CECL program and help your team produce more accurate EL forecasts.
Different modeling methods are typically used on different types of loans or assets to estimated expected credit losses, and different models are sometimes even combined to use on one asset type. However, the varying types of methods also vary in their methodological and theoretical complexity. There are simple methods that can be applied to estimate expected losses, such as the Discounted Cash Flow (DCF), Average Charge-Off, Vintage Analysis, or Static Pool Analysis methodologies, but these methods rely on oversimplified assumptions which greatly reduces their ability to produce accurate estimates and predict expected losses effectively.
I am going to focus on one of the most complex methods — Probability of Default (PD), Loss Given Default (LGD), and Exposure at Default (EAD) methodology — which is commonly referred to holistically as the Expected Loss (EL) methodology. EL is simply Loss Frequency multiplied by Loss Severity, which means that the EL method takes the sum of the values of all possible losses, where each loss is multiplied by the probability of that loss occurring.
The EL method is complicated because it requires the development and implementation of several interdependent supervised machine learning models for PD, LGD, and EAD. These models are trained using historical loan level portfolio data, and then used to score new data that was not used for training.
The target variable for each model will vary:
-
The PD model will use a binary indicator as its target, which identifies whether or not a loan has defaulted within the given time-frame. Therefore, the model will return a likelihood, or probability, that a given loan will default.
-
The LGD is commonly calculated as total actual losses divided by total potential exposure at default. An LGD model will predict the share of an asset that is lost when an asset has defaulted (1-LGD is known as the recovery rate, which is the proportion of a loan that is recovered when an asset has defaulted).
-
The EAD is the total exposure at default and it is equal to the current outstanding balance in case of fixed exposures, such as term loans.
-
The final EL projection is calculated by taking the sum of the values of all possible losses, where each loss is multiplied by the probability of that loss occurring: EL = PD x LGD x EAD.
The target for estimating PD is a binary, the loan either defaulted or it did not, which means that a binary classification algorithm should be used to model and estimate PD. However, since the target variables are continuous for LGD and EAD, a regression algorithm should be used to appropriately model and forecast their values. But, there are endless possibilities of models and preprocessing steps to implement when developing an EL model. How can you be sure you have decided to use the one best suited for your portfolio?
A smarter solution would be to strategically implement technology to expedite this process through automation, which will vastly reduce calculation complexity while increasing transparency and support of your expected loss forecasts.
One approach is to have your modeling teams manually test every combination of pre-processing and modeling algorithms. However, even if this was possible to do manually, manual processes are inefficient, unscalable, and prone to user error and bias, which greatly increase operational risk caused by unreliable forecasts. A smarter solution would be to strategically implement technology to expedite this process through automation, which will vastly reduce calculation complexity while increasing transparency and support of your expected loss forecasts.
Furthermore, because CECL requires expected losses to be estimated at the time of origination, manual processes are too computationally intensive and demanding to successfully implement and maintain. It is therefore imperative for any successful CECL process to integrate technology and automation into all aspects of their processes.
Automation is the Key
Compared to the existing Allowance for Loan and Lease Losses (ALLL) requirements, CECL requires more complex modeling inputs, assumptions, analysis, and documentation, making the option to automate key components of the process significantly more attractive for many institutions. Whether that automation is driving efficiencies into the modeling process through automated machine learning, the documentation process through automated documentation, or the productionalization process through flexible and scalable deployment options, it will certainly accelerate the value gained from strategic technology investments while also ensuring your CECL processes is maintainable and scalable.
An automated and streamlined impairment process will reduce audit and regulatory risk by ensuring consistent and process-driven methodology, which will eliminate “on the fly change” caused by manual processes. These process automations include automated machine learning for expected loss forecasting and analysis, a data governance and assurance program automation, and process documentation automation. External auditors will look at the evidence and documentation used by management in preparing the expected loss estimate to ensure they are based on reasonable and supportable forecasts.
Implementing technology to automate necessary compliance processes, such as automated documentation, alternative benchmark models, model tuning, independent model validation and model governance, model back-testing and performance, ongoing model performance monitoring, and so on, will provide incredible value for an institution in the form of added efficiency, reduced operational risk, and cost reduction, thereby driving value throughout the organization.
Figure 1: Using automation to build and maintain an effective loan loss impairment process.
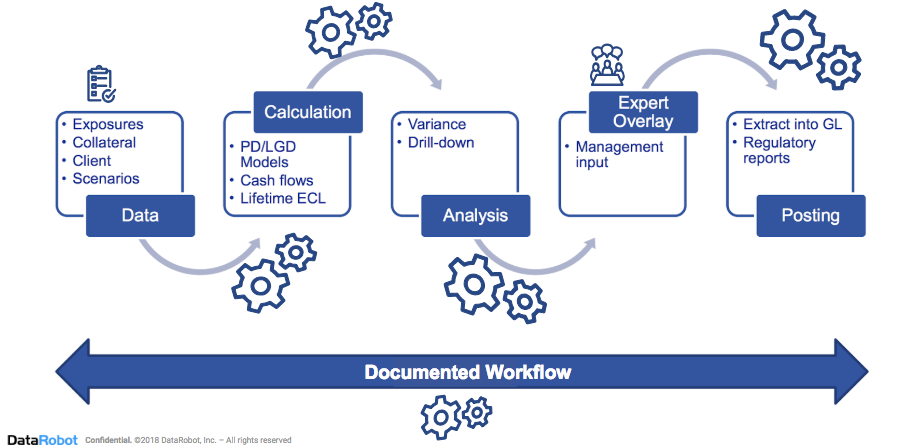
DataRobot streamlines your CECL process by fully automating the modeling process from data ingestion to calculation and analysis, and through the extraction of the model estimates into the General Ledger (i.e., deployment). Additionally, using DataRobot’s Automatic Documentation capability automatically documents the entire modeling process so the resulting process is transparent and easily interpretable by the business. This also provides a sufficiently detailed audit trail of the modeling process, meeting audit and regulatory requirements.
By leveraging industry leading automation, DataRobot enables banks to accurately and quickly predict the expected lifetime losses at origination, while also providing transparency into the model and its predictions to ensure your projections are both reasonable and supportable for auditors and regulators alike. The end result is a reduction of model risk, while also greatly improving operational efficiency and accuracy of your EL forecast.
- Opening the “Black Box AI”: The Path to Deployment of AI Models in Banking
- Automating Model Risk Compliance
- CECL banking. Are banks ready?
- What is Model Risk and Why Does it Matter?

About the Author
As the head of Model Risk Management at DataRobot, Seph Mard is responsible for model risk management, model validation, and model governance product management and strategy, as well as services. Seph is leading the initiative to bring AI-driven solutions into the model risk management industry by leveraging DataRobot’s superior automated machine learning technology and product offering.

As the head of Model Risk Management at DataRobot, Seph Mard is responsible for model risk management, model validation, and model governance product management and strategy, as well as services. Seph is leading the initiative to bring AI-driven solutions into the model risk management industry by leveraging DataRobot’s superior automated machine learning technology and product offering.
-
How to Choose the Right LLM for Your Use Case
April 18, 2024· 7 min read -
Belong @ DataRobot: Celebrating 2024 Women’s History Month with DataRobot AI Legends
March 28, 2024· 6 min read -
Choosing the Right Vector Embedding Model for Your Generative AI Use Case
March 7, 2024· 8 min read
Latest posts
