

The Problem with “Accuracy”: Kaggle’s Petfinder.my Adoption Prediction Competition
A few days ago, Kaggle–and its data science community–was rocked by a cheating scandal.
Kaggle is a popular online forum that hosts machine learning competitions with real-world data, often provided by commercial or non-profit enterprises to crowd-source AI solutions to their problems. For every competition, the host provides a training and test set of data. Everyone from expert data scientists to aspiring amateurs can participate. Competitors train models and submit their predictions for the test set, and then are scored against the hidden ground truth using an accuracy metric that the host has determined. Their accuracy is then ranked on a public leaderboard. At the end of the competition, the top submissions are frequently eligible for cash prizes, and the winning solutions are meant to be incorporated into the host’s real-world processes.
In March 2019, Kaggle’s “Petfinder.my Adoption Prediction Competition” concluded with the team “Bestpetting” as the 1st place winner of $10,000. The competition’s host was the Malaysian animal welfare platform Petfinder.my, which is dedicated to getting homeless and stray animals in Malaysia adopted. The goal was to design a solution that used information about a pet’s profile to predict when it would get adopted, allowing Petfinder.my to create more appealing profiles and home their animals faster. There were no issues with Bestpetting’s winning solution until Petfinder.my tried to implement it. Bestpetting had cheated. This discovery led to a deep investigation by Kaggle user Benjamin Minixhofer, who uncovered just how it was done.
Bestpetting intentionally leveraged a technique called “target leakage” to artificially inflate their accuracy scores on Petfinder.my’s test dataset. In target leakage, information that could not be accessed at the time of prediction “leaks” from the future into the training dataset. In this case, the input data was supposed to represent only the information you’d have on the pet’s profile, and the target was to predict the pet’s adoption. Bestpetting scraped information off Petfinder.my’s website to know in advance which animals in the hidden test set of data had been adopted, then encoded it in what looked like a unique random identifier for each row. They designed the rest of their solution to mask the fact they already had access to the answers, limiting their accuracy to something realistic and nesting the process of reading the encoded identifier within routine-looking functions.
While far from a typical example, these events open the door to having a broader conversation about accuracy in machine learning. Bestpetting cheated by exploiting limitations to the scope of accuracy as defined in a Kaggle-like environment, which consists of pre-established, often pre-processed and cleaned datasets, and a single metric measuring success. “Kaggle accuracy”, while useful, is only an approximation of real-world accuracy, which drives value–in this case, finding stray animals homes.
Instead, real-world accuracy is best defined as observed production accuracy. That is, for a productionalized model that is being actively used to inform decision-making, how often are you “getting it right”? It was by that metric that Bestpetting’s solution failed, and by that metric the true value of any solution resides. In this larger perspective, Kaggle accuracy represents only a theoretical ideal. We should expect Kaggle accuracy to be the upper limit of performance of a machine learning model in the real world.
Machine learning is a tool for solving complex problems, which originate within complex human-involved processes. The machine learning lifecycle, in practice, begins with the identification of an appropriate problem, its careful framing, and its definition. The cycle doesn’t end when you have a working model, but continues on as long as that model is used to inform decision-making in a production environment. Kaggle accuracy sits squarely in the middle of the machine learning lifecycle: when a problem has been set-up, but before it has been deployed into production. Over-emphasizing Kaggle accuracy may blind us to other, greater sources of error in the process.
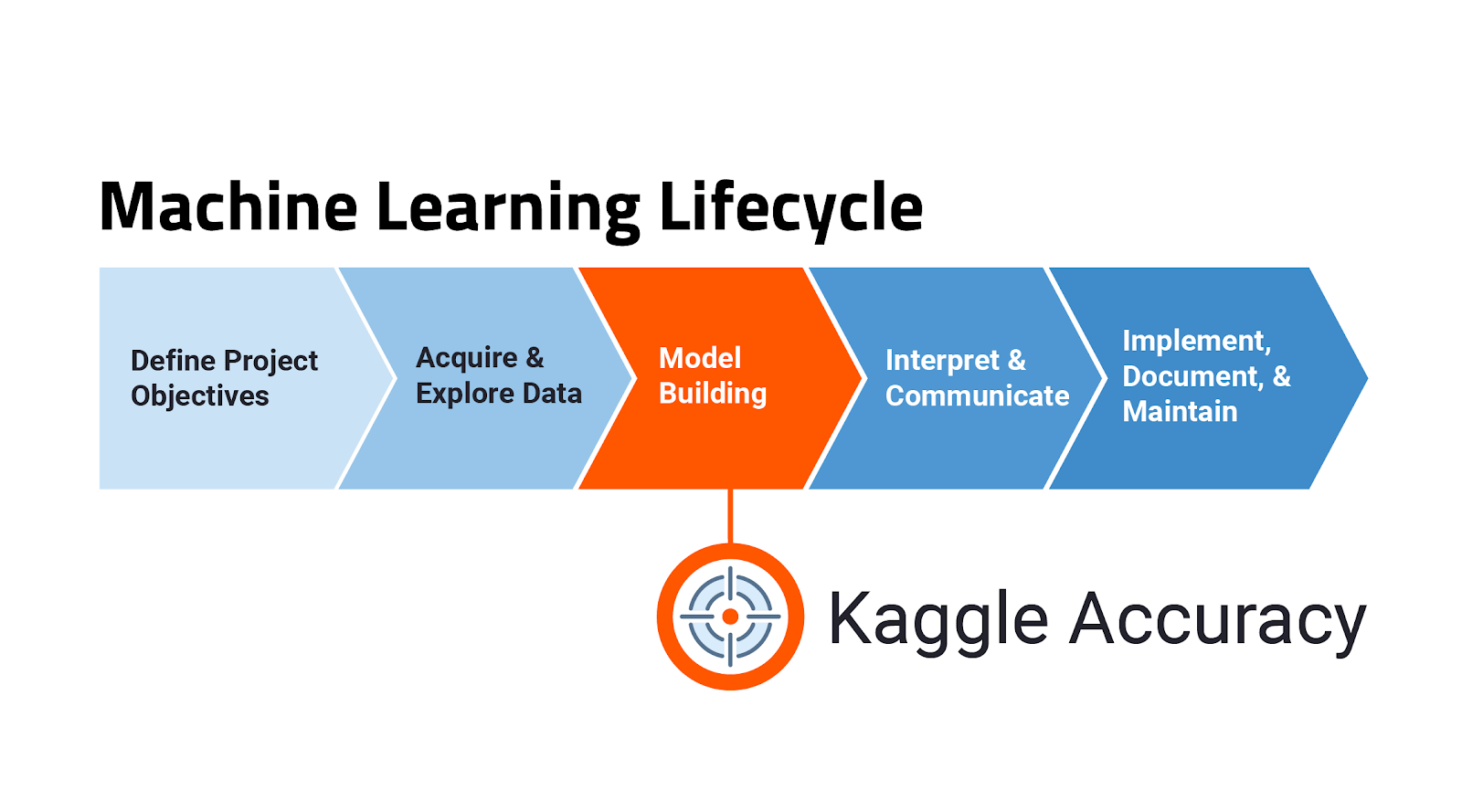
Sources of Error Beyond Kaggle Accuracy
Observed production accuracy can be conceptualized as a simple equation. The highest theoretical accuracy is Kaggle accuracy, achieved in a Kaggle-like data environment. From this Kaggle accuracy, we subtract the contributions of errors made in model building and errors in the productionalization of a model to calculate our observed production accuracy. Those errors often play more of a role in observed production accuracy than Kaggle accuracy.
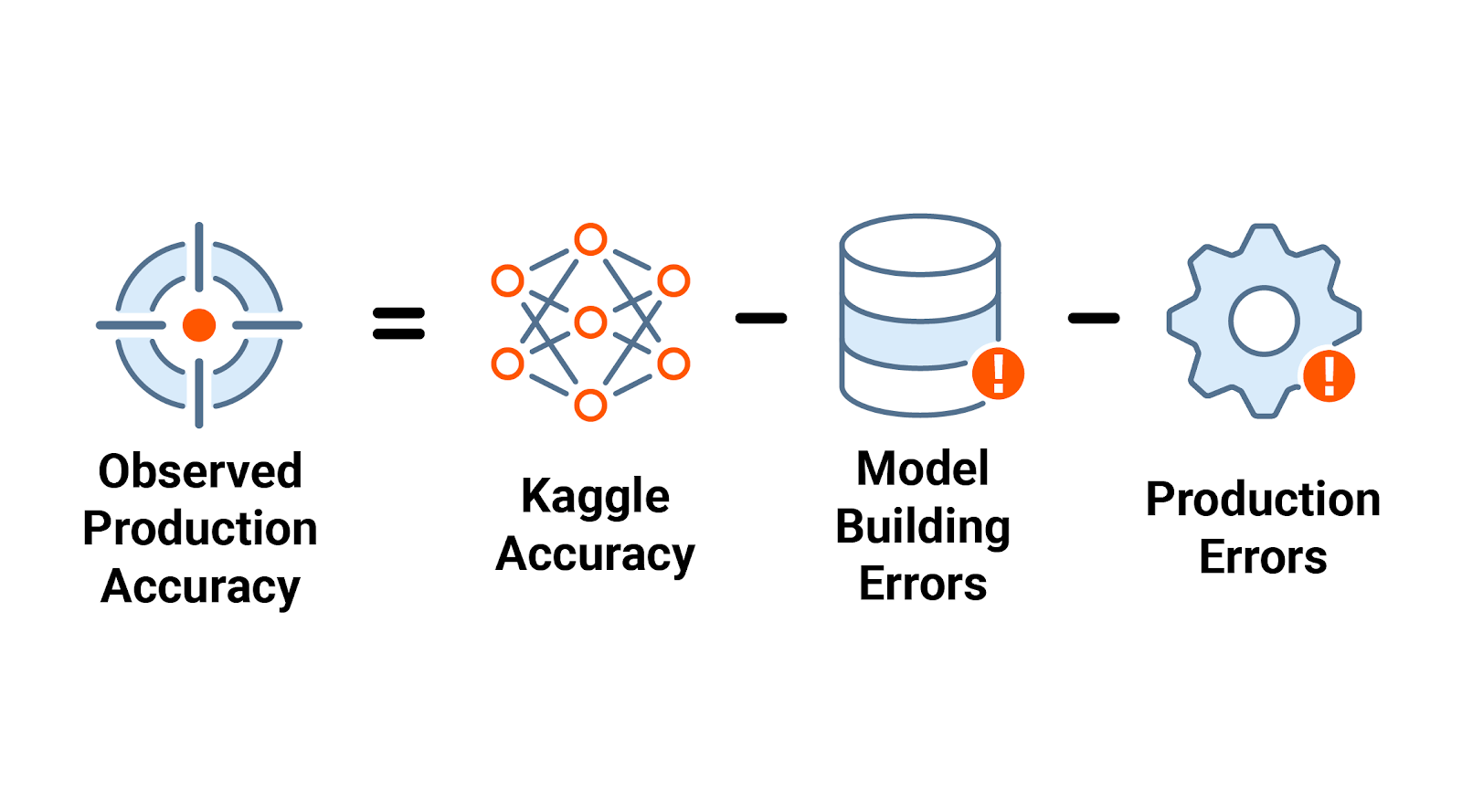
Model Building Errors
Errors in model building most often originate from the framing of the problem and the selection of features to use in your model. The first challenge is defining the predictive target. A poorly understood target can have disastrous results. For example, a 2019 study assessed a commercial algorithm used to assign risk levels to patients to identify those in need of extra care and discovered it greatly misrepresented the sickness of African American compared to Caucasian patients. Why? In order to measure “sickness”, the predictive target had used historical health costs, and African American patients had historically received less care for similar levels of illness.
Feature selection is the next pivotal step. Target leakage represents the most immediate danger, which Bestpetting intentionally exploited. It more often occurs accidentally; for instance, when you’re predicting loan defaults from loan applications, if you include a feature indicating that a collections agency was contacted for a particular loan, which you could not know at the time of application, the algorithm will seem to “perfectly” predict defaults. Other features may link to the target more subtly, but still result in artificially inflating the assessed accuracy of a cross-validated model. Target leakage can be much more dangerous if the feature is also in the test set reserved for final verification. Then, your Kaggle accuracy will be disastrously optimistic, meaning you only discover the error once your leaky model is in production and hurting your decision-making.
Production Errors
After a model has been deployed, errors in production have the added challenge of the time it takes for you to catch them. If your model is predicting an event that will not happen for six months, then it takes six months for you to validate its performance and calculate observed production accuracy–and that assumes you’re tracking actuals and calculating accuracy in the first place. In that potential lag-time, you would’ve accrued six months of poorly-informed decisions.
Data errors, which are due to the machine learning model itself, need to be monitored hand-in-hand with system errors, which relate to the application where the model is accessed to make predictions on new data. Both types of error represent a critical breakdown in your productionalized model. Keep in mind, accuracy is just one aspect of data monitoring. Simultaneously tracking the drivers of performance degradation can provide an early warning system before observed production accuracy is impacted. Observed production accuracy often degrades naturally over time because new data, and the process the data represents, no longer sufficiently resemble the state of the system when the model was trained. Calculating the differences in the distributions of individual features from training data to scoring data is called “data drift tracking”. When the data has drifted past what you have determined is an acceptable level, it may be time to retrain the model before performance deteriorates further.
Finally, it’s worth discussing how governance is core to observed production accuracy. Governance broadly refers to determining what is “acceptable” for a machine learning model’s performance, and who is accountable. Traceable lineage and documentation for the model, both in terms of the model building and the data it has been scoring, is pivotal to having accountability in the event something does go wrong. It is also essential to ensure there is a system in place that attributes responsibility and informs the right people about the operations of the model. The details of the broader context of the problem ultimately guide what metrics and thresholds for performance are acceptable. Different types of errors have different associated costs, and human decision-making plays a significant role in how the model’s predictions are finally used and what costs or benefits are incurred.
The Big and Small Picture
The Petfinder.my Adoption Prediction scandal has demonstrated that Kaggle competitions are not designed to take into account the broader scope of observed production accuracy–even though, for the host of the competition, this is where the real value of machine learning lies. Bestpetting found an avenue to cheat by circumventing the defined rules of the competition and “won” the accuracy prize, but failed to deliver on that value to the homeless animals of Malaysia. In the same way, with the type of errors discussed here, you can accidentally build a model that succeeds in terms of Kaggle accuracy but does not provide you the value it was meant to.
Our goal is not to discount Kaggle’s accuracy, but situate it within the bigger picture, in which a machine learning model makes decisions that bring value to your enterprise. Observed production accuracy is the achievement of rigorous best practices throughout the entire machine learning lifecycle–but more importantly is what’s meaningful to all of us, as machine learning continues to impact more and more aspects of everyday life.


Sarah is an Applied Data Scientist on the Trusted AI team at DataRobot. Her work focuses on the ethical use of AI, particularly the creation of tools, frameworks, and approaches to support responsible but pragmatic AI stewardship, and the advancement of thought leadership and education on AI ethics.
-
Belong @ DataRobot: Celebrating 2024 Women’s History Month with DataRobot AI Legends
March 28, 2024· 6 min read -
Choosing the Right Vector Embedding Model for Your Generative AI Use Case
March 7, 2024· 8 min read -
Reflecting on the Richness of Black Art
February 29, 2024· 2 min read
Latest posts
