

Understanding Song Popularity with Automated Machine Learning
Spotify made waves after it introduced its music service to the masses in 2008, allowing users to stream music as opposed to buying a record or purchasing a song on iTunes. Hailing nearly twice as many subscribers as competitor Apple music. Spotify continues to be a primary source for those who want to listen to music without having to buy every song or album desired.
One of the cool aspects about the former startup is that much of their music information (artists, albums, tracks, etc) is exposed via a web API. This includes attributes for each song such as its tempo, how much energy it has, what key it’s in, etc. Personally, I’ve always been fascinated about the mechanics behind a popular song. What are their general characteristics? Do they normally have more high-energy beats? A certain length? Catchy names? I set out to investigate these things empirically using DataRobot, an automated machine learning platform.
Data Collection
Using the R package spotifyr, I pulled the discography from artists that appeared in the Billboard Year End Chart – Hot 100 Songs list dating back to 2010. This chart ranks artists based on radio airplay, sales data, and streaming activity across all genres. Naturally, while these artists will have popular songs, not all of their music are hits. Hence, modeling the popularity of all their songs from 2010-2017 will allow us to investigate what separates popular tracks from not-so-popular songs from the most well-known names in music.
For my target, I use the “popularity” measure calculated by Spotify. This is a score from 0 to 100, with more popular tracks having a higher value. As for my features, I include the artist’s name as well as various attributes about the track such as its genre, lyrics, title, what day of the week it was released, and its audio features.
Exploratory Data Analysis
An obvious area to explore first is the genre. Each song in the dataset has a list of several categories that it falls into, as determined by Spotify. Using one of DataRobot’s text modelers, I generated a word cloud to identify which genres are most related to popularity. The larger the word, the more frequently it occurs. The more red the word, the more likely that it’ll be a popular song while the bluer words, are less likely to be popular.

Based on the data, it appears that “rap” and “pop” music generally denote a more popular track while hybrid genres such as “pop rap” or “dance pop” do not seem to garner as much interest. While it may seem confusing that “trap music” is so blue due to its prevalence in the hip-hop community, a possible reasoning for this lies in another word cloud: the song lyrics. Due to explicit content, the word cloud isn’t shown here, but it does reveal an interesting finding: explicit words are very polarizing, being either really red or really blue. Because of this insight, I decided to add some additional features related to the amount of profanity in a song and the general sentiment.
Modeling and Insights
With the help of DataRobot R package, I built over 400 models, each automatically tuned in less than an hour. To create a more powerful approach, I combined the predictions from some of these models to build what is known as a “blender” in DataRobot, which served as my final model for the subsequent analysis.
Using a technique called feature impact, my blender tells me which factors are most important when predicting a song’s popularity. Unsurprisingly, the genre, track lyrics, day of release, and artist are driving forces for predicting popularity. However, we see other attributes also play a role such as the duration and number of profane words present.
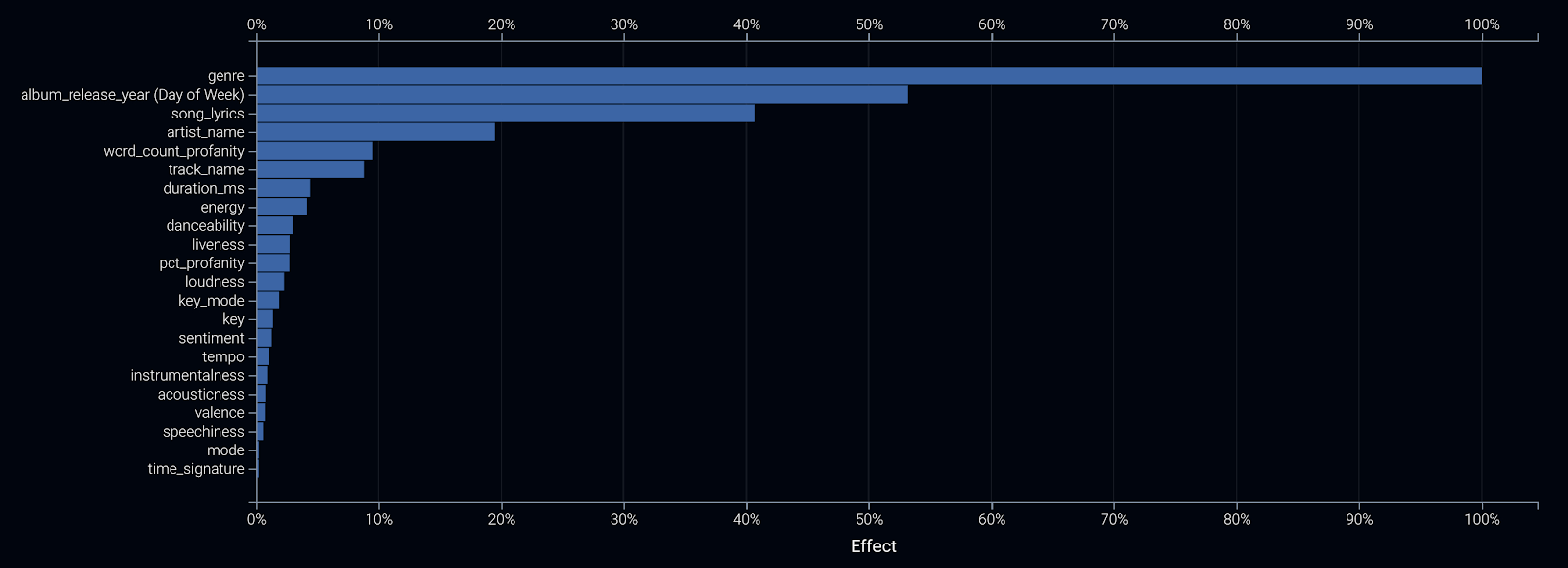
Let’s drill down as to why these other factors are important. Using feature effects, we can analyze the relationship that these particular features have on estimating the popularity of songs, given all the other information in the dataset.
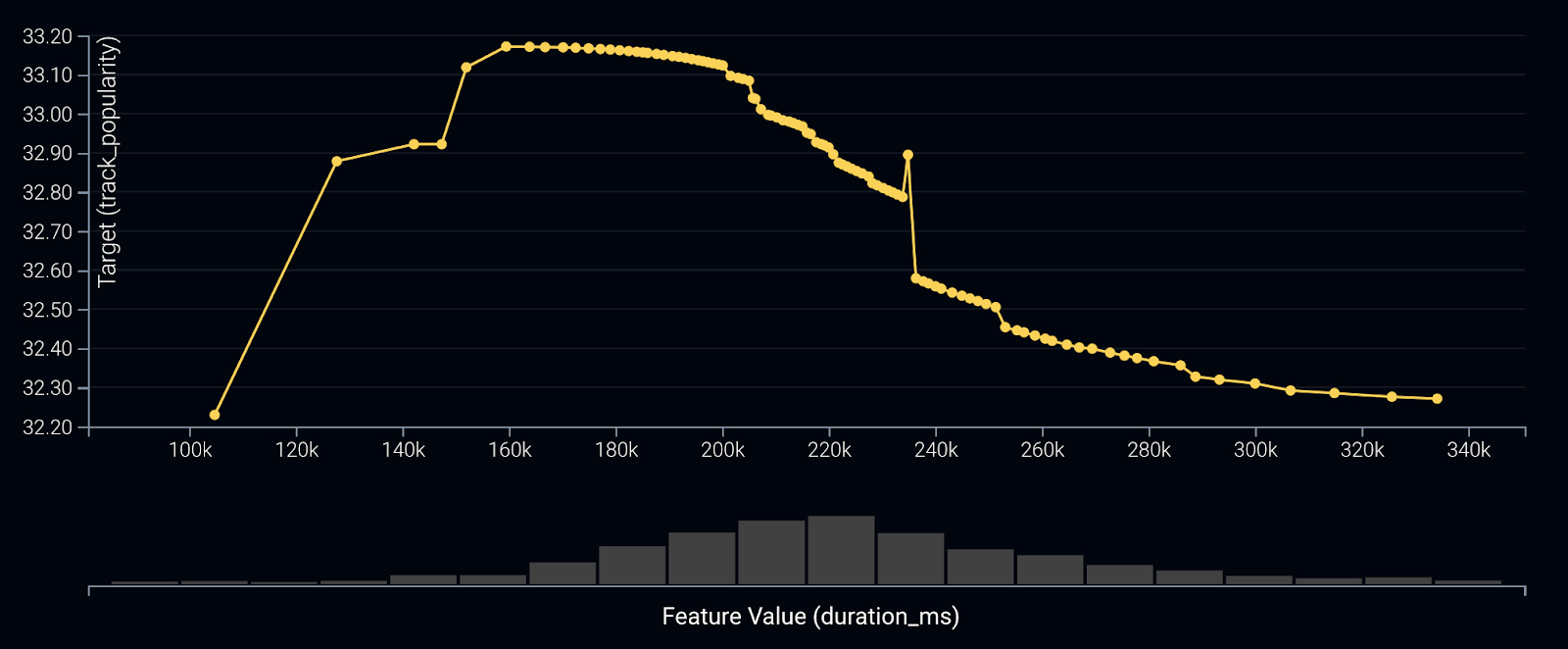
The above graph indicates a strong, non-linear relationship in the duration of the track, where the least popular songs are either less than two minutes or over five minutes. This peaks right around the infamous 3-minute rule, which is known at the optimal length for a hit song.
Of the sentiment and profanity-based features, the number of profane words in a song is most important. Its effect is listed below.
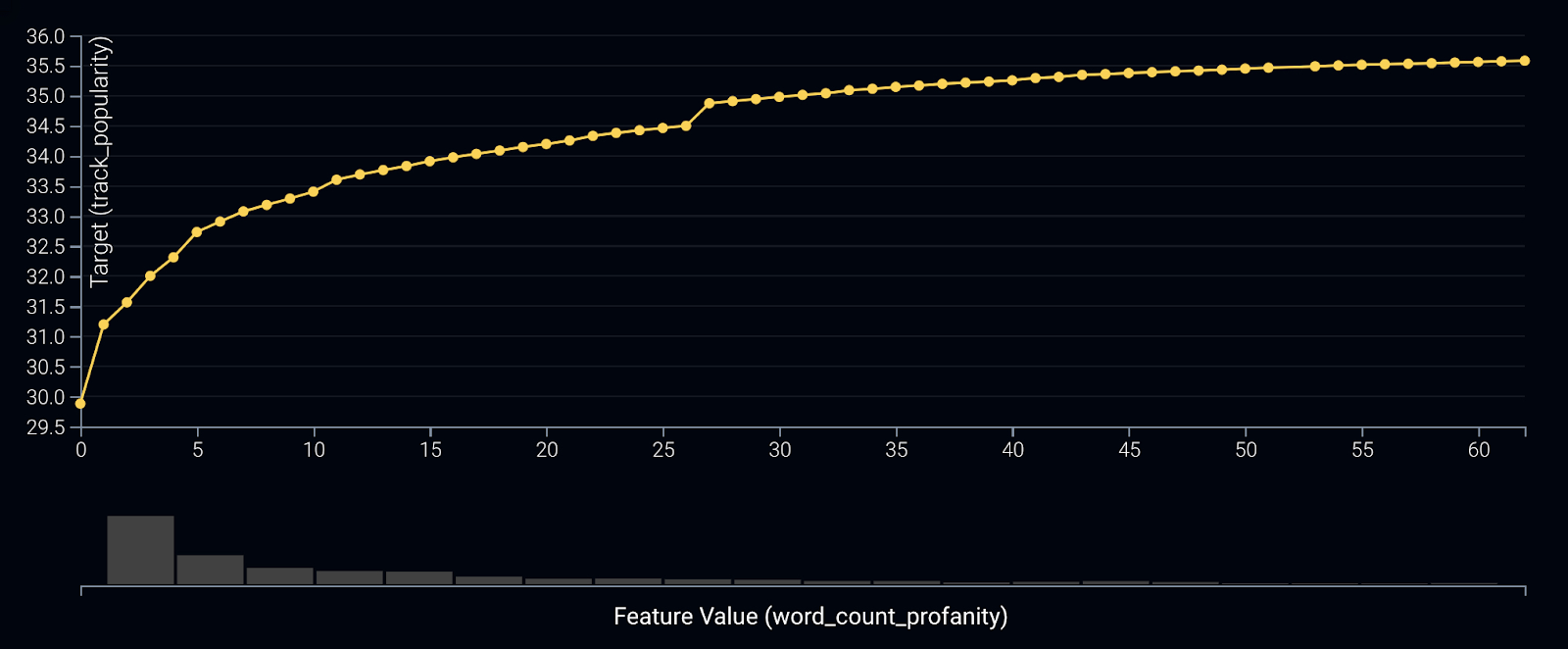
Interpreting this plot, it appears that the more profanity a song has, the more likely it will be considered popular. This pattern is accordant with the recent uptick in explicit content in popular songs. However, it does seem to have a diminishing law of return, beginning to plateau off at around 30 profane words (looking at another effect yields that some of the least popular songs have over 20% of its lyrics considered profanity). Ultimately, based on the historical data, one of the keys to a popular song seems to be striking a balance between explicit content and being totally G-rated.
Kendrick Lamar: A Case Study
Now having established some general trends in regards to what makes a popular song, I wanted to apply the blender on one of my favorite albums, DAMN, by Kendrick Lamar. This album not only won a Grammy for Best Rap Album, but also won a Pulitzer Prize for music, making Kendrick the first non-classical or jazz musician to win the award.
Given its notoriety, I was curious if there existed similar types of tracks on the album. One way to accomplish this would be via some kind of clustering algorithm on the raw data I collected; however, one of the issues with clustering is being unable to apply these techniques on more complex datasets such as those with mixed data types (numeric, categorical, and text features), which mine has.
Fortunately, with the help of prediction explanations, we can overcome this issue. Prediction explanations is an interpretive tool in DataRobot that provides insights as to why a model makes a prediction at the row level, shining light onto the “black-box” nature of machine learning algorithms.
These are available for any model built in DataRobot, even for my complicated blender. The beauty behind this approach is that it can numerically quantify the most relevant factors and their effect, for any song I want. After generating this insight for every track on DAMN, I visualize the similarity of the prediction explanations using this approach.
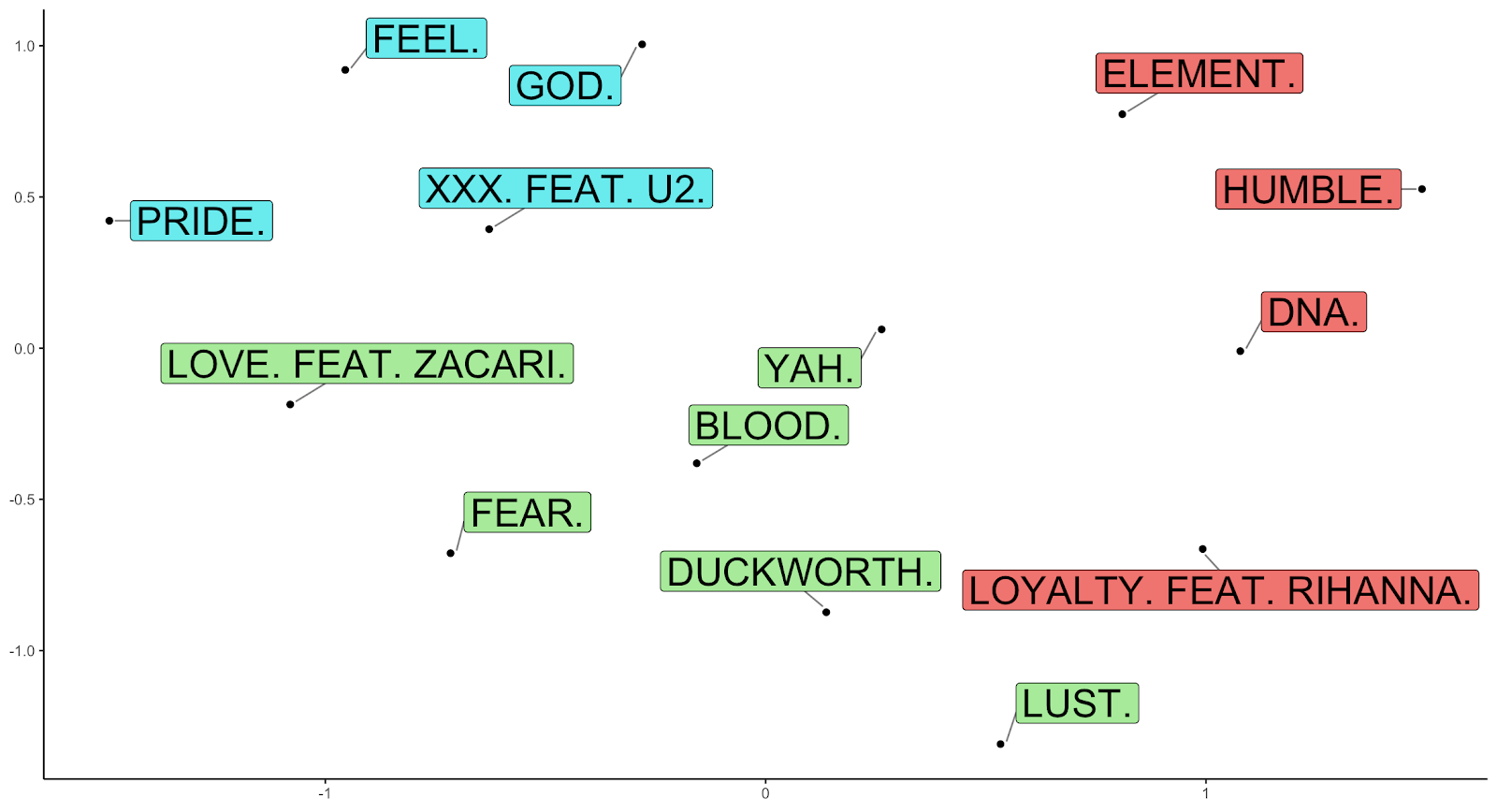
The above graph pictures which songs are most similar songs and how many distinct groups (3 in this case) exist based on their prediction explanations. What’s really cool about this result is that the red songs are four of the top five most popular tracks from the album, including “HUMBLE.” and “DNA.”, both of which were in the Billboard Year End Chart – Hot 100 Songs list for 2017. In addition, it puts some of the shortest and least profane tracks in the same group (see like “YAH.”, “BLOOD.”, and “LOVE. FEAT. ZACARI.”). With the help of prediction explanations, the music industry could empirically identify which songs are most likely to be popular and why, allowing for better insights and collaboration with new and established artists.
So What?
While this is a fun application of machine learning, it demonstrates a potential role it can have in the music industry. Music producers and radio executives could study what makes a successful song from a data perspective, helping them more fully understand why people listen to the songs that they do. Considering the wide diversity of music available, having easy ways to gain insights like this is paramount. While there’s no replacement for creativity and subject matter expertise, adopting machine learning approaches can aid in these decisions, and ultimately, lead to better music for everyone.

About the author:
Taylor Larkin is a Data Science Evangelist at DataRobot. Based out of Atlanta, he’s responsible for teaching data science best practices by leading training sessions, developing course content for DataRobot University, and helping academic institutions integrate DataRobot into the classroom. He has worked on machine learning projects and research articles in a variety of realms including geomagnetic storm prediction, healthcare, renewable energy, sports analytics, and wine preference. Prior to joining DataRobot, Taylor graduated from The University of Alabama with a PhD in Business Analytics and an MS in Applied Statistics.

Taylor Larkin is a senior data scientist at DataRobot. Based out of Atlanta, he’s currently responsible for leading and executing data science projects with customers. He has worked on use cases in a variety of realms including financial markets, marketing, transportation, and healthcare. Prior to joining DataRobot in 2017, Taylor graduated from The University of Alabama with his PhD where he proposed ways to improve geomagnetic storm prediction using machine learning. He enjoys spending his free time with his wife and old dog, Pearl.
-
DataRobot Recognized by Customers with TrustRadius Top Rated Award for Third Consecutive Year
May 9, 2024· 2 min read -
How to Choose the Right LLM for Your Use Case
April 18, 2024· 7 min read
Latest posts
