

Using Automated Machine Learning to Predict NBA Player Performance
The 2018 NBA Finals are in full swing and this year marks the fourth consecutive time that the Cleveland Cavaliers will face off against the Golden State Warriors. With Lebron James and Steph Curry leading the charge for their teams, this rivalry is sure to make this year’s playoffs one for the history books.
With some of the top talent in the NBA, the Cleveland Cavaliers and the Golden State Warriors are the teams that other NBA franchises are looking to topple. Every NBA team is constantly searching for an edge, and with the success of analytics in other sports, such as Major League Baseball, NBA teams are looking to advanced technologies like machine learning and artificial intelligence (AI) to gain a competitive advantage.
There are many applications for AI within sports organizations, including sales and marketing, merchandising, chatbots, computer vision, and wearable tech, but this blog post focuses on a particular application – predicting player performance. And from a fan’s perspective, player performance is a lot more fun!
Player Performance Metrics
There are many ways to assess player performance. At the most basic level, basketball is about scoring more points than the opponent, so naturally points-per-game is a nice place to start. But, there are other methods to quantify player performance, and some of them get quite complex like Box Plus Minus or Player Efficiency Rating.
For this blog, I will walk through the steps of how DataRobot helps predict player performance as measured by Game Score (game_score).
The formula for Game Score is as follows:
game_score = PTS + 0.4 * FG – 0.7 * FGA – 0.4*(FTA – FT) + 0.7 * ORB + 0.3 * DRB + STL + 0.7 * AST + 0.7 * BLK – 0.4 * PF – TOV.
Game Score (game_score) attempts to incorporate some of the most important individual statistics and weights them to maximize its correlation with winning. Game Score was created by John Hollinger to give a rough measure of a player’s productivity for a single game.
Modeling with DataRobot
Following the default DataRobot workflow, I uploaded a csv file with statistics from the completed NBA season, selected the target (game_score), and kicked off Autopilot with a simple click of the “Start” button!
Autopilot initiates DataRobot’s automated machine learning engine, choosing 30-40 appropriate modeling approaches to compete for best accuracy. Each modeling approach, called a blueprint, is fit on a portion of the training data and ranked by accuracy using the out of sample validation data.
Autopilot automatically completes the typical modeling workflow that a top data scientist will routinely perform in a fraction of the time. In minutes, hundred of models are built, analyzed and displayed on the Model Leaderboard (see Figure 1) for further evaluation.
Model Leaderboard
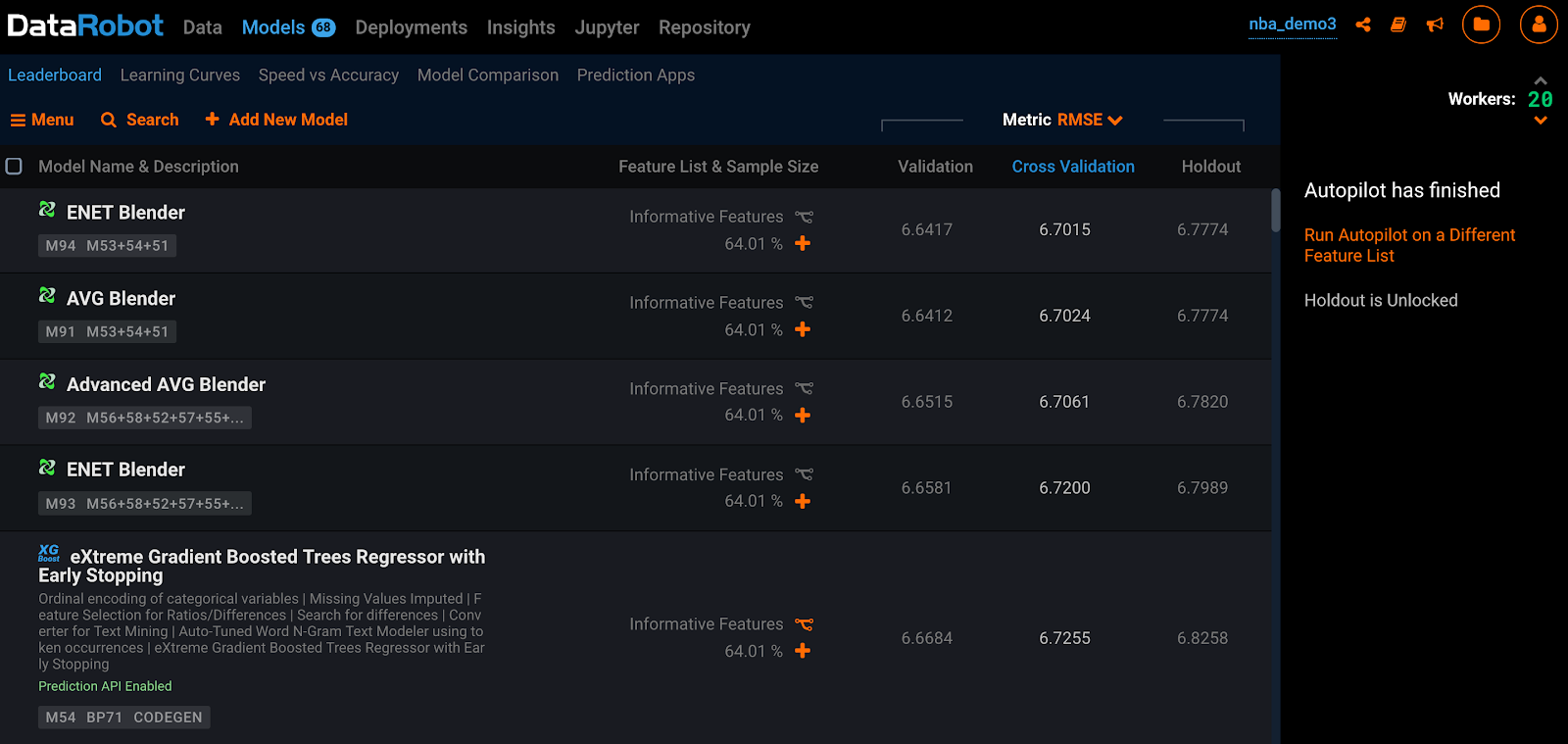
The Leaderboard displays badges, tags, and columns that provide information to quickly identify the model and scoring information. In terms of predicting player performance, the top model is an ENET Blender with a Cross Validation Root Mean Squared Error of 6.7015.
Lift Chart
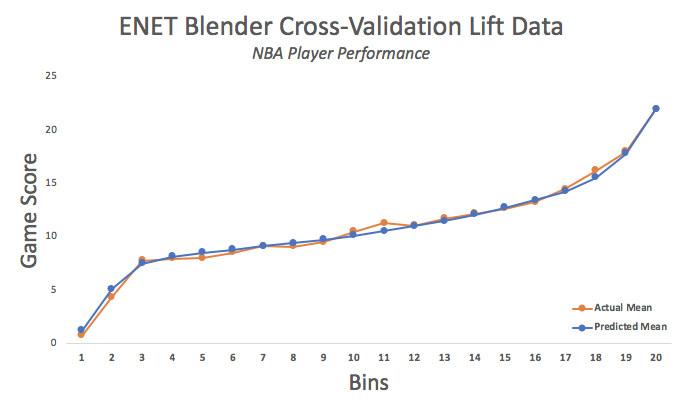
The lift chart is easy way to quickly evaluate the accuracy of a particular model on the dataset. The lift chart bins and sorts the expected player performance as predicted from lowest to highest. Overlayed are the actual values for player performance. In this chart, the actual player performance values track nicely with the predicted values with a well defined slope to resolve the top performers from rest.
Top Model Understanding
DataRobot has a number of built-in tools to bolster the user’s understanding of the data problem and the model. These tools enable easy and effective communication of insights and expected performance. One of the most important skills of a top data scientist is being able to tell a compelling story that drives decisions throughout the organization. Here are a few of the tools available in DataRobot for model insights.
Feature Impact
Feature impact is a tool that ranks each variable in the dataset by its relative importance. This is a good tool for understanding and explaining what features, or variables, the model has determined to be most important for making accurate predictions.
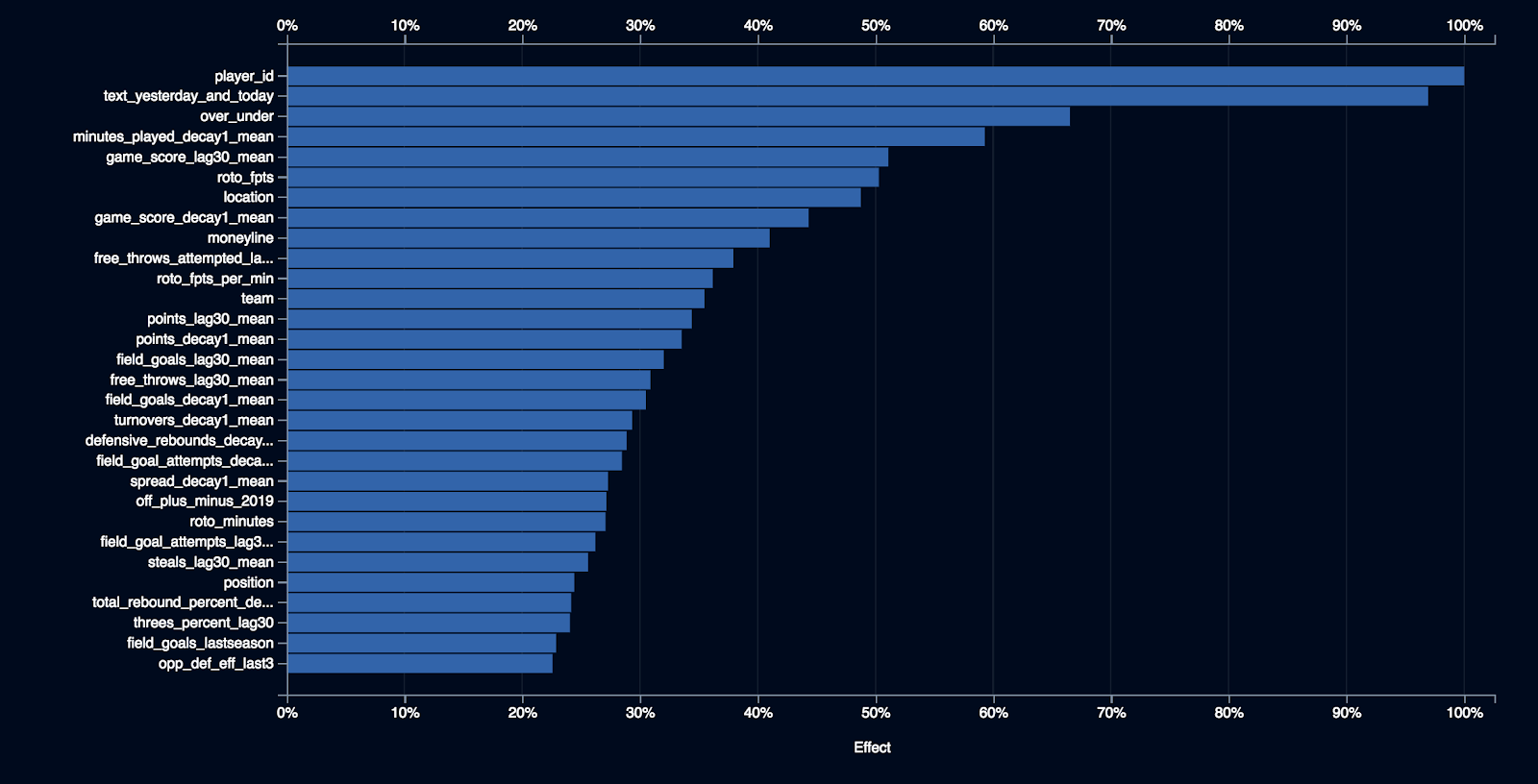
The most important feature for the ENET Blender model is player_id. The second most important feature is an unstructured text feature called text_yesterday_and_today, which is based on daily fantasy news at the player level. DataRobot seamlessly mines and processes unstructured text to extract information that may be predictive. DataRobot visualizes the salient information using a word cloud (see Figure 4).
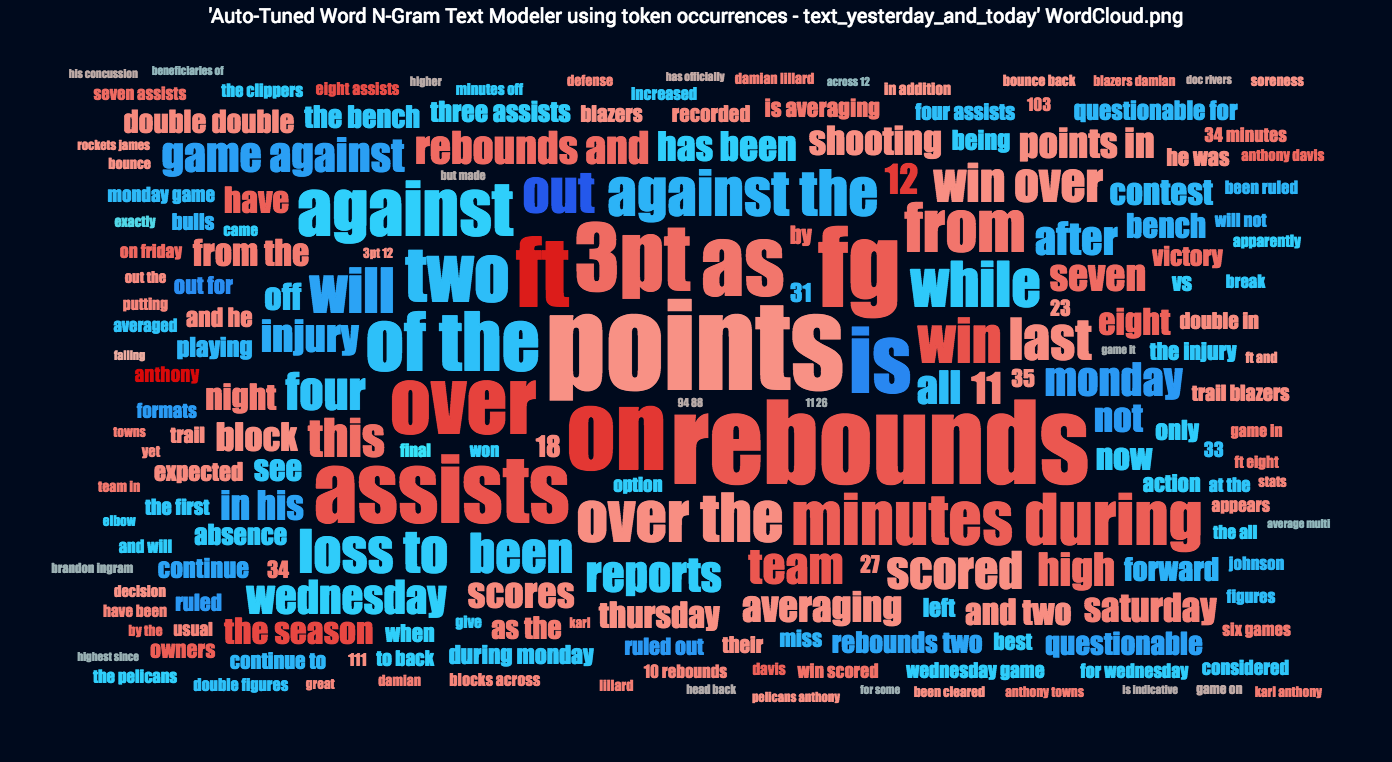
Let’s break this word cloud down a bit. First, the larger the word or phrase, the more often it shows up in the dataset. Second, red is associated with high performance and blue is associated with poor performance. The more intense the colors, the stronger the association is.
Notice that the model has cued off of words or phrases like “out,” “injury,” and “questionable for” that are strong indicators of poor performance (blue coloration). On the flip side, the model found associations for high performance (red coloration) between words and phrases like “ft,” “rebounds,” “assists,” and “minutes during.” On the surface, these associations aren’t all that surprising.
Feature Effects
Because of the complexity of many machine learning techniques, models can sometimes be difficult to interpret directly. The Feature Effects chart displays a feature’s effect on the overall prediction for that particular model, depicting how a model “understands” the relationship between each variable and the target. One of the strongest predictors of future performance is the minutes played recently. Let’s unpack minutes_played_decay1_mean with Feature Effects.
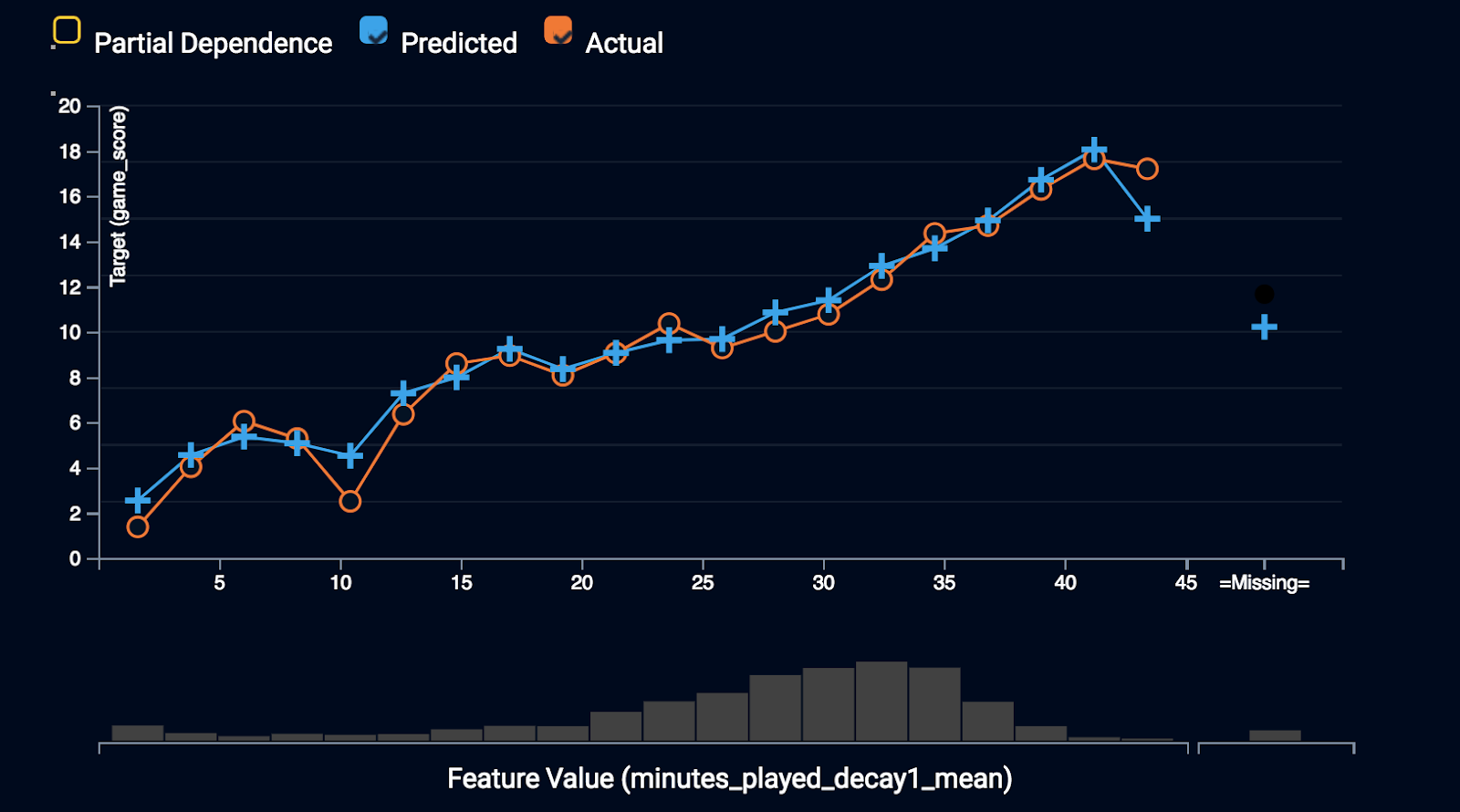
The relationship between minutes played recently and future performance is quite strong. The model is picking up an important signal in this feature. The blue line represents the mean prediction for each bin of minutes_played_decay1_mean and the orange line represents the actual mean predictions. Notice the predicted and the actual game_score values track nicely with each other and display a strong positive relationship with player performance. To take this one step further, let’s analyze the partial dependence curve.
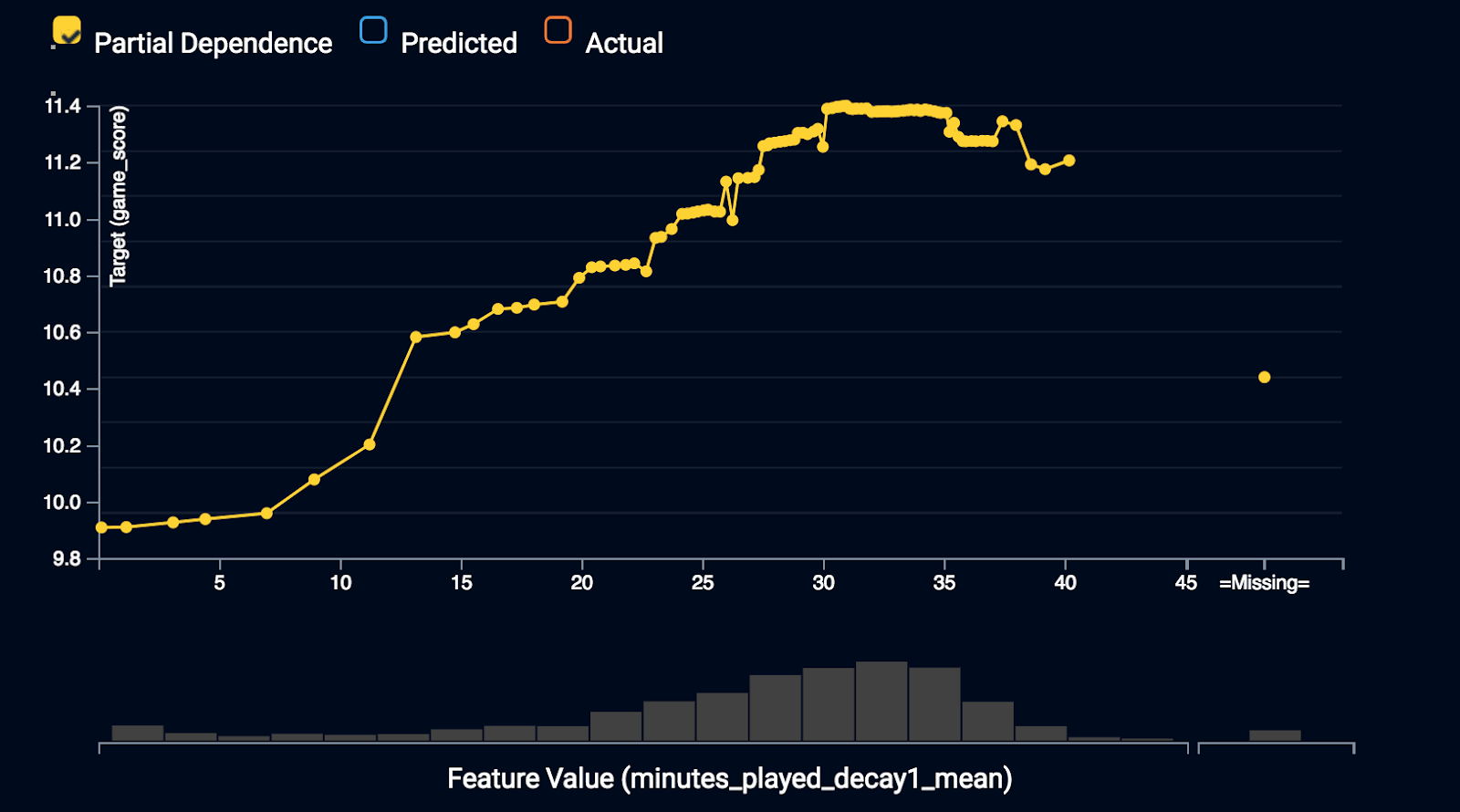
Partial dependence is a plot that visualizes the relationship between each feature and the prediction that the model is making. The shape of the line shows you how the given feature impacts predictions, while holding everything else constant. The advantage of partial dependence vs. coefficients or other metrics is that it’s non-parametric. Therefore it can resolve more complicated patterns in this relationship.
The relationship between minutes_played_decay1_mean and player performance is mostly positive, but there’s a leveling off, or even evidence of a local maximum at the upper end. This may indicate an optimal amount of playing time with evidence of diminishing performance if too many minutes have been logged recently.
Prediction Explanations
After you build models, you can use Prediction Explanations to help understand the reasons DataRobot generated individual predictions. Let’s unpack the top five Prediction Explanations for a few examples in the training data. To follow along, see Table 1.
Giannis Antetokounmpo
For a particular upcoming game, Giannis Antetokounmpo was predicted to perform quite well with a Game Score of 29.14. What did the model pick up about Giannis to make this prediction?
First of all, Giannis is a freak of nature and a bonafide NBA superstar, so his player_id is an important predictor. Next, over the last 30 days, Giannis had averaged 22 field goals attempted, 13 free throws attempted, and 37 points per game, indicating excellent recent historical production, which the model expects to continue. Lastly, the model picked up on his Player Efficiency Rating from the previous season, which is a strong indicator of consistent player performance.
Devin Booker
On the flip side, Devin Booker was nursing an injury and was predicted to poorly perform. What did the model pick up about Devin to make this prediction?
The most interesting Prediction Explanation comes from a recent news report:
“Suns’ Devin Booker: Progresses to wind sprints (groin) has progressed to doing wind sprints, Scott Bordow of The Arizona Republic reports. Until word emerges otherwise, Booker’s anticipated return date of Dec. 29 remains. But, it’s encouraging that he’s progressing well in his recovery. In his stead, Josh Jackson and Troy Daniels have been seeing extended run and will likely continue to do so while Booker remains sidelined.”
Using its text processing engine, DataRobot extracted signals from the news report, which are strongly indicative of poor performance. A human can easily draw the same conclusion, but may have a difficult time reconciling the hundreds of daily player news reports. DataRobot’s AI engine can easily digest, make sense of, and utilize of all of this information.
Table 3: Prediction Explanations
|
row_id |
1612 |
32 |
|
Player |
Giannis Antetokounmpo |
Devin Booker |
|
Prediction |
29.14173273 |
-0.135546432 |
|
Reason 1 Strength |
++ |
— |
|
Reason 1 Feature |
player_id |
roto_fpts_per_min |
|
Reason 1 Value |
‘antetgi01’ |
‘0.0’ |
|
Reason 2 Strength |
++ |
— |
|
Reason 2 Feature |
field_goal_attempts_lag30_mean |
over_under |
|
Reason 2 Value |
‘22.0’ |
MISSING |
|
Reason 3 Strength |
++ |
— |
|
Reason 3 Feature |
free_throws_attempted_lag30_mean |
roto_minutes |
|
Reason 3 Value |
‘13.0’ |
‘0.0’ |
|
Reason 4 Strength |
++ |
— |
|
Reason 4 Feature |
points_lag30_mean |
roto_fpts |
|
Reason 4 Value |
‘37.0’ |
‘0.0’ |
|
Reason 5 Strength |
++ |
— |
|
Reason 5 Feature |
PER_lastseason |
text_yesterday_and_today |
|
Reason 5 Value |
‘26.1’ |
‘Suns’ Devin Booker: Progresses to wind sprints (groin) has progressed to doing wind sprints, Scott Bordow of The Arizona Republic reports. Until word emerges otherwise, Booker’s anticipated return date of Dec. 29 remains. But, it’s encouraging that he’s progressing well in his recovery. In his stead, Josh Jackson and Troy Daniels have been seeing extended run and will likely continue to do so while Booker remains sidelined.’ |
Conclusions
While I only scratched the surface of the insights derived from this exercise, I hopefully highlighted the power of the DataRobot automated machine learning platform to build highly accurate models for predicting player performance. From optimizing a player’s workload to determining what drives performance on an individual basis, these insights can be that edge that coaches and executives are searching for. With the right tools, perhaps another NBA team can break the Cavaliers/Warriors final streak in 2019.

Ben Miller is a Customer Facing Data Scientist at DataRobot with a strong background in data science, advanced technology, and engineering. Ben is a machine learning professional with demonstrable skills in the area of multivariable regression, classification, clustering, predictive analytics, active learning, natural language processing, and algorithm R&D. He has scientific training and application in disparate industries including; biotechnology, life sciences, pharmaceutical, environmental, human resources, banking, and media.
-
How to Choose the Right LLM for Your Use Case
April 18, 2024· 7 min read -
Belong @ DataRobot: Celebrating 2024 Women’s History Month with DataRobot AI Legends
March 28, 2024· 6 min read -
Choosing the Right Vector Embedding Model for Your Generative AI Use Case
March 7, 2024· 8 min read
Latest posts
