

Using Fuzzy Matching Plus Artificial Intelligence to Identify Duplicate Customers
When you go to Starbucks, do they always write the correct name on your coffee cup? For me, the Starbucks crew frequently adds an extra ‘L’ and spells my name as “Collin” instead of “Colin” (and I just don’t have the heart to correct them).
Whether it’s a misspelled name in a coffee shop, or two people who share phone numbers with only a single digit difference, there are opportunities everywhere to make mistakes and create duplicate customer information. And large businesses like banks and online retailers are faced with thousands (or tens of thousands) of these types of mistakes and duplications in their customer databases.

Not knowing your customer leads to missed sales opportunities and poor customer service.
Duplicate customer records cause many problems for businesses, and at the top of the list are poor targeting and wasted marketing efforts. For example, if a customer is listed multiple times with different purchases in the database due to different spellings of their name, a new address, or a mistakenly-entered phone number, it is all too easy to try and sell them a product they already have.
Not knowing your customer leads to missed sales opportunities and poor customer service. It also creates inefficiencies and wasted costs, as each duplicate record creates extra processing and duplicate customer communications. And finally, it leads to inaccurate reporting, which in turn promotes less informed decisions. With data quality issues and millions of customer contacts, how can we remove and consolidate duplicate customer records for a single customer view?
Traditionally, fixing duplicate customer records is a manual process that is both time-consuming and expensive. Unless all the details are identical, it is difficult to know if different records are the same person. And typically, most potential duplicates are false positives – just because two people share the same name, address, or date of birth does not mean that they are the same person.
Eighty-one percent of marketers say that they have trouble achieving a single customer view, and over half of marketers from enterprise brands see effective linkage as the main barrier to creating a truly cross-channel marketing strategy, according to new research from Experian.
Database queries for duplicates will not find spelling mistakes, typos, missing values, changes of address, or people who left out their middle name. For example, I live in Singapore and many of my Chinese friends have both a Chinese name and a Western name, and use both names interchangeably.
The solution to these duplication problems is to use fuzzy matching instead of looking for exact matches. Fuzzy matching is a computer-assisted technique to score the similarity of data.
Consider the duplicate customer records for “Marcelino Bicho Del Santos” and “Marcelino B. Santos”(see Figure 1). Fuzzy matching would count the number of times each letter appears in these two names, and conclude that the names are fairly similar. In this case we would obtain a high fuzzy matching score of 0.93, where 0 means no match and 1 means an exact match.
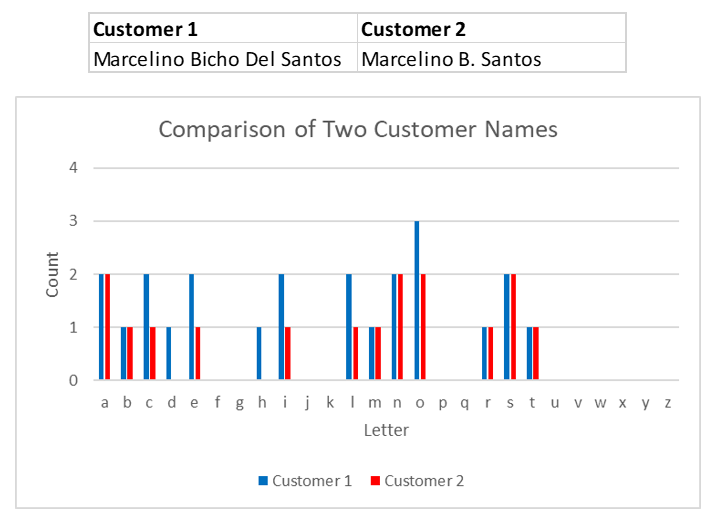
Now, compare Marcelino to another customer “John Smith” (see Figure 2). Once again, fuzzy matching counts up the number of times each letter appears in these two names, and concludes that the names were quite dissimilar. In this case we would obtain a low fuzzy matching score of 0.68, which is not very indicative of a match.
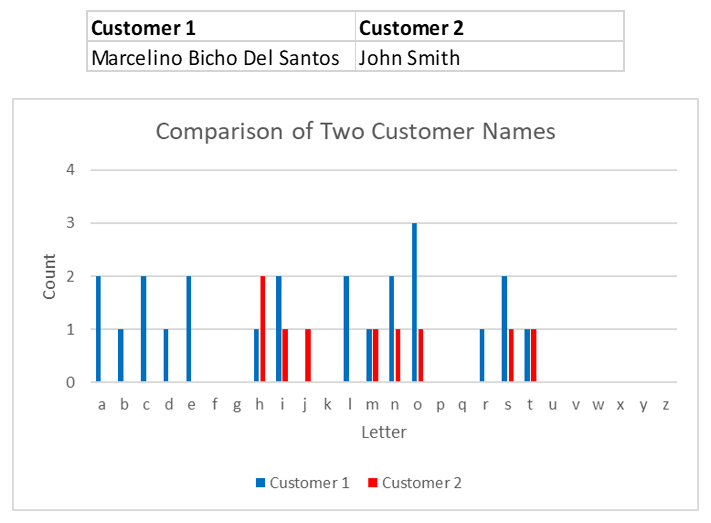
But fuzzy matching is not sufficient on its own. If Marcelino Bicho Del Santos is a 35-year-old living in Barcelona, and Marcelino B. Santos is a 90-year-old living in New York, they are most likely not the same person. For better accuracy, we need to know which combinations of fuzzy matching scores (there is one fuzzy matching score for each database field that is being compared) indicates a duplicate record. For example, in some countries a zip code uniquely identifies a building, while in other countries a zip code includes thousands of homes.
This is where artificial intelligence (AI) steps in, finding the optimal way to combine these scores. It isn’t enough to have the fuzzy matching scores, you also need to know which combination of similar database fields, and how similar those database fields need to be, in order to be indicative of a match.
You can train a machine learning algorithm using fuzzy matching scores on these historical tagged examples to identify which records are most likely to be duplicates and which are not.
The types of customer data that you can use to identify duplicates typically include name, address, date of birth, phone number, email address, and gender. In many cases, you can supplement this data with a credit card number, past purchase preferences, and occupation. You should consider using as many fields from your customer database as possible.
In addition, based upon your past manual attempts to find duplicate customer records, you will have examples of pairs of customer records that are duplicates, and some pairs that are similar but are not the same person. You can train a machine learning algorithm using fuzzy matching scores on these historical tagged examples to identify which records are most likely to be duplicates and which are not.
Once trained, your new AI will predict whether or not a pair of customer records are truly duplicates. Just send the model the fuzzy matching scores for any new pair of customer records and it will tell you the probability that they truly are duplicates.
Do you want to build an AI without all the hassle of choosing and training algorithms? The solution is automated machine learning — expert software that takes your data, trains multiple algorithms, and finds the one that is most accurate on your data. Automated machine learning models offer advanced interpretability that will even tell you why the model decided that “Collin Priest” and “Colin Priest” are the same person! Once you’re ready, you can deploy the algorithm into production via one click, making it available via a Rest API.
DataRobot pioneered automated machine learning, and offers the most comprehensive, easy-to-use solution for optimizing and accelerating the development and deployment of AI applications. Contact us for a live demonstration that shows how easy it is to build an AI that identifies duplicate customer records.

Colin Priest is the VP of AI Strategy for DataRobot, where he advises businesses on how to build business cases and successfully manage data science projects. Colin has held a number of CEO and general management roles, where he has championed data science initiatives in financial services, healthcare, security, oil and gas, government and marketing. Colin is a firm believer in data-based decision making and applying automation to improve customer experience. He is passionate about the science of healthcare and does pro-bono work to support cancer research.
-
How to Choose the Right LLM for Your Use Case
April 18, 2024· 7 min read -
Belong @ DataRobot: Celebrating 2024 Women’s History Month with DataRobot AI Legends
March 28, 2024· 6 min read -
Choosing the Right Vector Embedding Model for Your Generative AI Use Case
March 7, 2024· 8 min read
Latest posts
