

Using Machine Learning to Identify High Potential Client Prospects in Wealth Management
In business you often want to accurately predict a relevant product need for a given client. Much research has been done on “recommender” systems using, for example, collaborative filtering to suggest a product based on either the purchases of similar clients or on the past purchases of that client.
Then, there are the cases where you have a product or service and want to find the ideal client. This becomes more difficult if the ideal client population is a small subset of the general population.
This scenario is particularly tricky in the Wealth Management business. Many of the desirable clients who have accumulated enough wealth to require sophisticated advisory needs – investments, tax, estate planning, trust – already have long established relationships with a trusted advisor. In some cases, these relationships span multiple generations. These clients are notoriously sticky, and tend not to move their business unless they are dissatisfied or the advisor moves to another institution.
A better strategy might be to go after the “emerging affluent” who are accumulating wealth and beginning to appreciate that managing it themselves is not the best use of their time and does not guarantee the best outcome. These clients, however, will not all become profitable. And, the ones who do may take quite some time to get there.
So, client prospecting in the wealth management business is difficult – the already profitable can be impossible to land, and the not yet profitable may take years to fully develop. So what can be done?
In these situations, the solution is to leverage your own data to learn how to identify and differentiate the best prospects.
Most wealth management leaders use their knowledge and experience, and anecdotal evidence, for prospecting. They will usually have a few great sources for referrals, or a favorite industry or region where they have had success, or they know that prospects from certain channels are better than others.
But now, bankers can use their past client data and machine learning technology to systematically determine all the data features that are good predictors of profitable future clients and use these features to identify high value prospects.
Whatever the method used to identify high-value prospects, if you can differentiate the good new client prospects from the less good ones in history then DataRobot’s automated machine learning platform can do the rest.
The best part: you do not need to know why certain prospects were better than others; only that they turned out to be better.
With automated machine learning, you need only to define the right feature and let DataRobot find the best model for predicting that feature value for you. You might create, for example, a feature called “annualized profit one year after on boarding” – this quantified profitability metric can then be used as the target (to be predicted).
With enough examples, machine learning can determine for you the best predictive characteristics. The resulting model can then be run against your prospect database or, even better, your institutions client population at large. The resulting predictions can be used to segment prospects, or prioritize those with the highest potential based on your past experience.
DataRobot’s Feature Impact capability lets you understand what aspects of the prospect data are the strongest predictors of future profitability based on the examples used to train the model. This may include purchased data, data about how the prospect was sourced, or demographics on the prospect themselves.
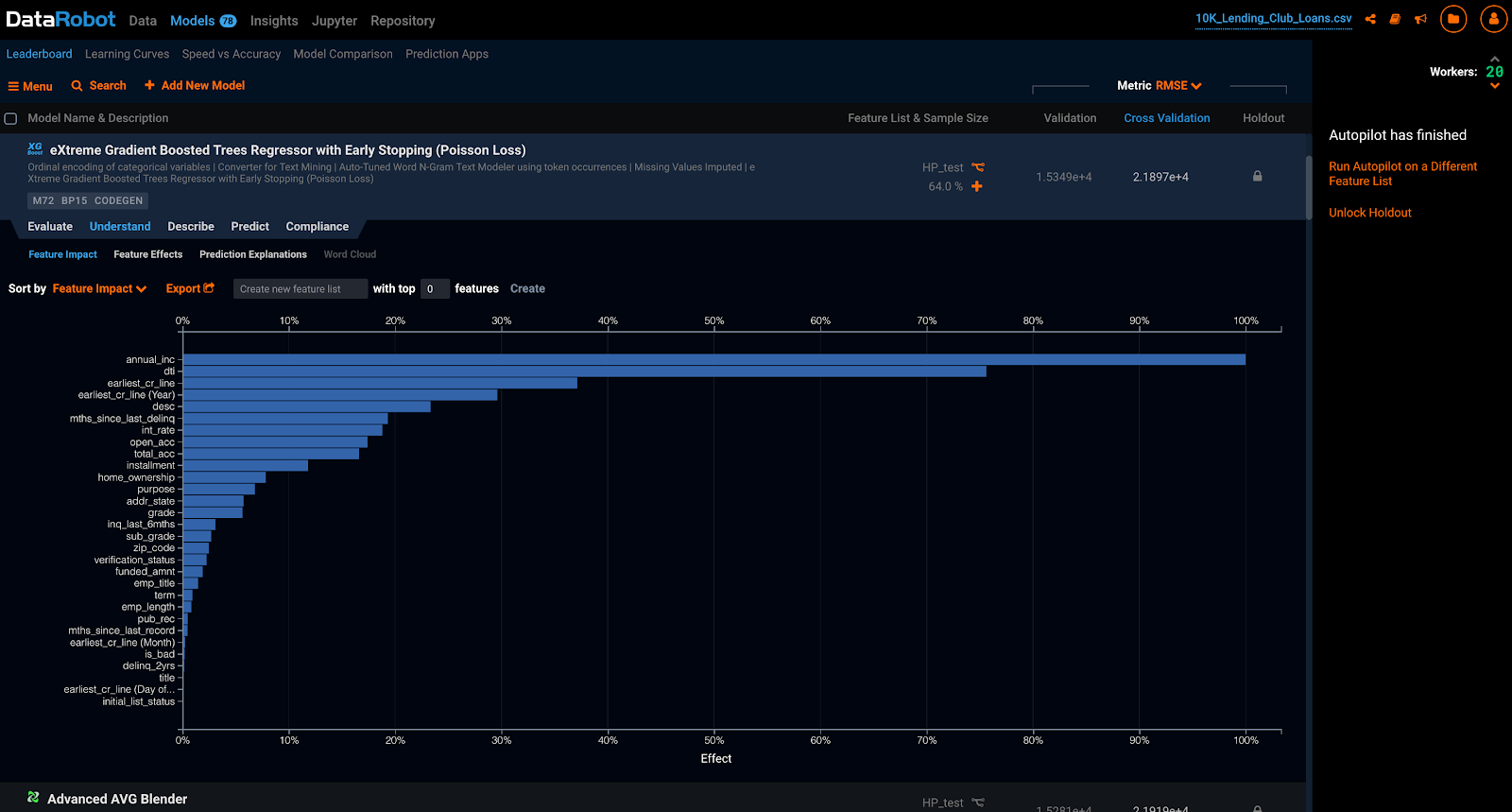
DataRobot’s Feature Impact screen shows you which data has the most predictive value for identifying the best prospects.
Once you know which features distinguish a high value prospect from an ordinary one, procedures can be developed or enhanced to focus on the leads with the highest potential. Consider if, for example, leads from a specific channel for prospects in a handful of specific locations and industries are identified as the highest value – new leads meeting those criteria could then be prioritized.
In addition, DataRobot’s HotSpot feature lets you isolate populations that are better prospects than others. This capability helps you see which combinations of features differentiate higher value prospects from others.
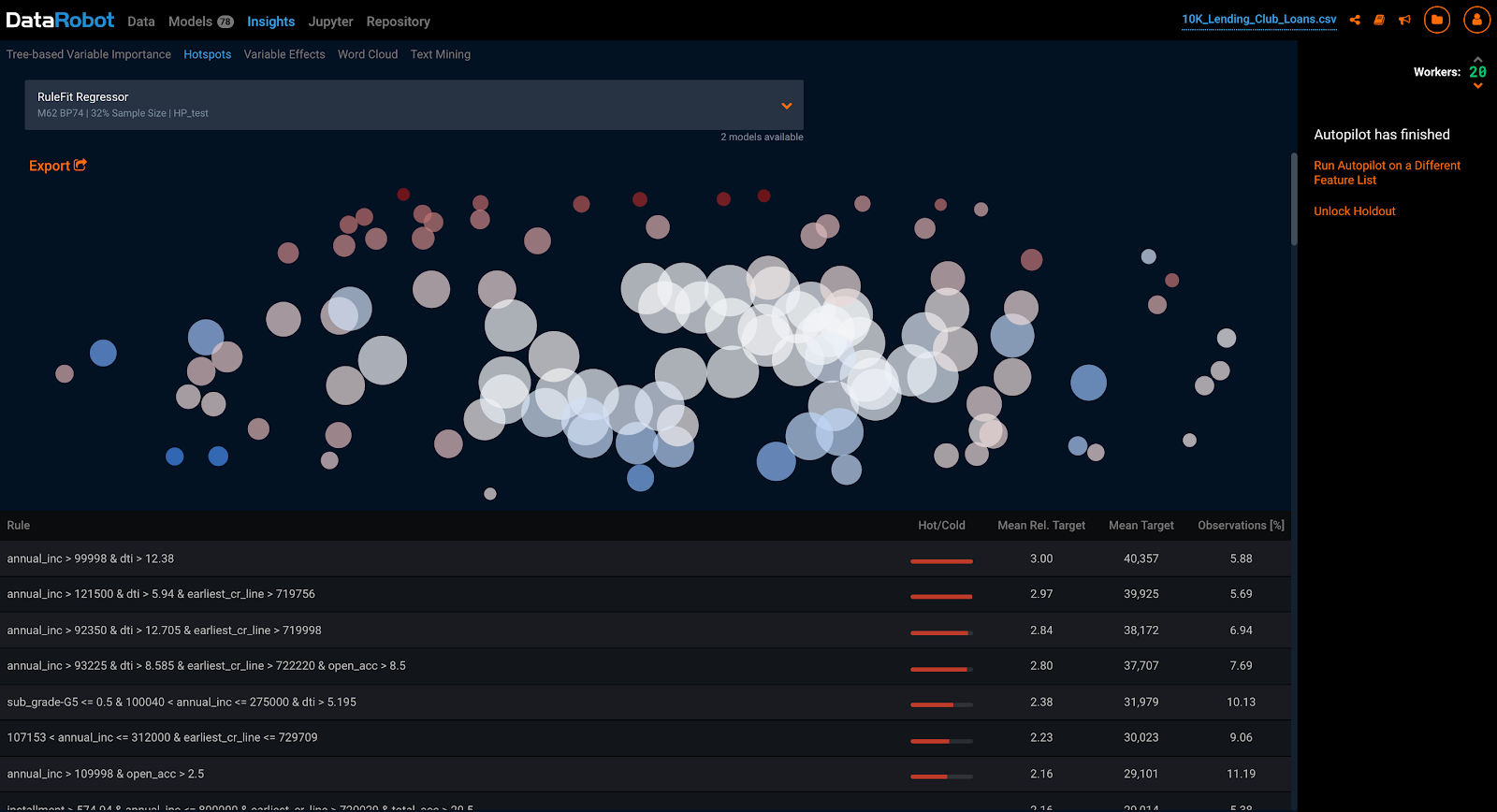
With HotSpot, the darkest blue dots represent combinations of features with the strongest likelihood of positive outcome, indicating these features should be explored to understand which leads are most valuable.
By using machine learning, you leverage your own experience to determine which new prospects have the highest potential. The result can be used in real-time as new referrals come in and to route high-potential prospects for immediate action. Or the model can be run against a large population to isolate the highest value prospects.
Either way, machine learning makes a positive outcome with less wasted effort far more likely.
Download the 5 AI Solutions Every Wealth Manager Needs eBook for more information.

About the Author:
H.P. Bunaes leads the banking practice at DataRobot, helping banks leverage AI and machine learning for predictive analytics and data mining. H.P. has 35 years experience in banking, with broad banking domain knowledge and deep expertise in data and analytics. Prior to joining DataRobot, H.P. held a variety of leadership positions at SunTrust, including leading the design and development of the risk data and analytics platform used enterprise wide for risk management. H.P. is a graduate of the Massachusetts Institute of Technology where he earned a Masters Degree in Management Information Systems, and of Trinity College where he earned a Bachelor of Science degree in Computer Science and Mechanical Engineering.

H.P. Bunaes is the GM of Banking at DataRobot, helping banks leverage AI and machine learning for predictive analytics and data mining. H.P. has 35 years experience in banking, with broad banking domain knowledge and deep expertise in data and analytics. Prior to joining DataRobot, H.P. held a variety of leadership positions at SunTrust, including leading the design and development of the risk data and analytics platform used enterprise-wide for risk management. H.P. is a graduate of the Massachusetts Institute of Technology where he earned a Masters Degree in Management Information Systems, and of Trinity College where he earned a Bachelor of Science degree in Computer Science and Mechanical Engineering.
-
How to Choose the Right LLM for Your Use Case
April 18, 2024· 7 min read -
Belong @ DataRobot: Celebrating 2024 Women’s History Month with DataRobot AI Legends
March 28, 2024· 6 min read -
Choosing the Right Vector Embedding Model for Your Generative AI Use Case
March 7, 2024· 8 min read
Latest posts
